
PHP 정렬 알고리즘 힙 정렬(Heap Sort)

- 不言원래의
- 2018-04-21 14:17:252180검색
이 글에서는 주로 PHP 정렬 알고리즘인 힙 정렬(Heap Sort)을 소개하며, 힙 정렬의 원리와 구현 방법, 관련 사용 주의사항을 예제 형식으로 자세히 분석합니다. 이 문서에서는 PHP 정렬 알고리즘 힙 정렬에 대해 설명합니다. 참고용으로 모든 사람과 공유하세요. 세부 사항은 다음과 같습니다.
알고리즘 소개: 여기서 "Dahua 데이터 구조"의 시작 부분을 직접 인용합니다.
앞서 간단한 선택 정렬에 대해 이야기했는데, n개의 레코드 중에서 가장 작은 레코드를 선택하려면 n - 1번의 비교가 필요합니다. 이는 첫 번째 데이터를 찾아서 여러 번 비교해야 하는 것이 정상입니다. 그렇지 않으면 그것이 무엇인지 알 수 있습니다. 가장 작은 기록.
안타깝게도 이 작업은 각 패스의 비교 결과를 저장하지 않습니다. 이전 패스에서 많은 비교가 수행되었지만 정렬 중에 이전 패스가 저장되지 않았기 때문입니다. 이러한 비교 작업은 다음 정렬 단계에서 반복되므로 더 많은 비교가 기록됩니다.
매번 가장 작은 레코드를 선택하고 비교 결과에 따라 다른 레코드를 적절하게 조정할 수 있다면 전반적인 정렬 효율성이 매우 높아질 것입니다. 힙 정렬은 단순 선택 정렬을 개선한 것으로, 이러한 개선의 효과는 매우 분명합니다.
기본 아이디어: 힙 정렬을 소개하기 전에 먼저 힙에 대해 소개하겠습니다.
"Dahua 데이터 구조"의 정의: 힙은 다음 속성을 가진 완전한 이진 트리입니다. 노드는 왼쪽 및 오른쪽 자식 노드의 값보다 크거나 같으면 큰 상단 힙(큰 루트 힙)이 됩니다. 또는 각 노드의 값이 왼쪽 값보다 작거나 같으면 오른쪽 노드는 작은 최상위 힙(작은 루트 힙)이 됩니다.
저도 이것을 보고 "힙이 완전한 이진 트리인지 아닌지"에 대한 의구심이 들었습니다. 나무, 나는 여전히 내 의견을 유보합니다. 여기서는 주로 저장과 계산을 용이하게 하기 위해 완전한 이진 트리 형태의 큰 루트 힙(작은 루트 힙)을 사용한다는 점만 알아야 합니다(편의성은 나중에 살펴보겠습니다).
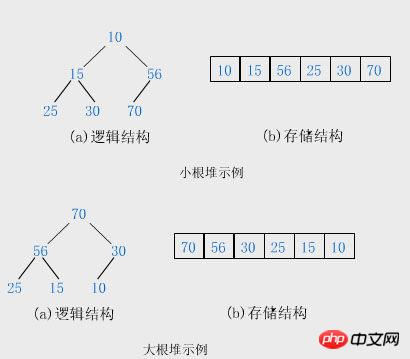
힙 정렬은 힙을 사용하여 정렬하는 방법입니다(큰 루트 힙을 가정). 기본 아이디어는 다음과 같습니다.
정렬할 시퀀스를 큰 루트 힙으로 구성합니다. 이때 전체 시퀀스의 최대값은 힙 상단의 루트 노드이다. 이를 제거하고(실제로 이를 힙 배열의 마지막 요소와 교환합니다. 이때 마지막 요소는 최대값입니다), 나머지 n - 1개 시퀀스를 힙으로 재구성하여 n개 요소를 얻습니다. 다음으로 가장 작은 값입니다. 이것을 반복해서 실행하면 순서가 있는 시퀀스를 얻을 수 있습니다.
큰 루트 힙 정렬 알고리즘의 기본 작업:1힙 만들기
힙 만들기는 len/2부터 시작하여 첫 번째 노드까지 계속해서 힙을 조정하는 프로세스입니다. , 여기서 len은 힙의 요소 수입니다. 힙을 만드는 과정은 선형 과정입니다. 힙을 조정하는 과정은 항상 len/2에서 0으로 호출됩니다. 이는 o(h1) + o(h2) ... + o(hlen/2)와 동일합니다. 여기서 h는 노드의 깊이를 나타내고, len/2는 노드 수를 나타내며, 이는 합산 과정이며 결과는 선형 O(n)입니다.
②조정 힙: 조정 힙은 힙을 만드는 과정에서 사용되며, 힙 정렬 과정에서도 사용됩니다. 아이디어는 노드 i를 해당 하위 노드 left(i) 및 right(i)와 비교하고 세 개 중 가장 큰(또는 가장 작은) 값이 노드 i가 아니라 해당 하위 노드 중 하나인 경우를 선택하는 것입니다. , 거기에서 노드 i는 노드와 상호 작용한 다음 힙 조정 프로세스를 호출합니다. 이는 재귀 프로세스입니다. 힙을 조정하는 프로세스의 시간 복잡도는 힙의 깊이와 관련이 있습니다. 깊이 방향을 따라 조정되기 때문에 lgn의 작업입니다.
③힙 정렬: 힙 정렬은 위의 두 가지 프로세스를 사용하여 수행됩니다. 첫 번째는 요소를 기반으로 힙을 구축하는 것입니다. 그런 다음 힙의 루트 노드를 꺼내고(일반적으로 마지막 노드와 교환) 첫 번째 len-1 노드로 힙 조정 프로세스를 계속한 다음 모든 노드가 제거될 때까지 루트 노드를 제거합니다. 힙 정렬 프로세스의 시간 복잡도는 O(nlgn)입니다. 힙을 만드는 데 드는 시간 복잡도는 O(n)(1회 호출)이므로 힙을 조정하는 데 드는 시간 복잡도는 lgn이고 n-1번 호출되므로 힙 정렬의 시간 복잡도는 O(nlgn)입니다. 이 과정을 명확하게 이해하려면 많은 다이어그램이 필요하지만 게으릅니다. . . . . .
알고리즘 구현:
<?php
//堆排序(对简单选择排序的改进)
function swap(array &$arr,$a,$b){
$temp = $arr[$a];
$arr[$a] = $arr[$b];
$arr[$b] = $temp;
}
//调整 $arr[$start]的关键字,使$arr[$start]、$arr[$start+1]、、、$arr[$end]成为一个大根堆(根节点最大的完全二叉树)
//注意这里节点 s 的左右孩子是 2*s + 1 和 2*s+2 (数组开始下标为 0 时)
function HeapAdjust(array &$arr,$start,$end){
$temp = $arr[$start];
//沿关键字较大的孩子节点向下筛选
//左右孩子计算(我这里数组开始下标识 0)
//左孩子2 * $start + 1,右孩子2 * $start + 2
for($j = 2 * $start + 1;$j <= $end;$j = 2 * $j + 1){
if($j != $end && $arr[$j] < $arr[$j + 1]){
$j ++; //转化为右孩子
}
if($temp >= $arr[$j]){
break; //已经满足大根堆
}
//将根节点设置为子节点的较大值
$arr[$start] = $arr[$j];
//继续往下
$start = $j;
}
$arr[$start] = $temp;
}
function HeapSort(array &$arr){
$count = count($arr);
//先将数组构造成大根堆(由于是完全二叉树,所以这里用floor($count/2)-1,下标小于或等于这数的节点都是有孩子的节点)
for($i = floor($count / 2) - 1;$i >= 0;$i --){
HeapAdjust($arr,$i,$count);
}
for($i = $count - 1;$i >= 0;$i --){
//将堆顶元素与最后一个元素交换,获取到最大元素(交换后的最后一个元素),将最大元素放到数组末尾
swap($arr,0,$i);
//经过交换,将最后一个元素(最大元素)脱离大根堆,并将未经排序的新树($arr[0...$i-1])重新调整为大根堆
HeapAdjust($arr,0,$i - 1);
}
}
$arr = array(9,1,5,8,3,7,4,6,2);
HeapSort($arr);
var_dump($arr);
실행 결과:
array(9) {
[0]=>
int(1)
[1]=>
int(2)
[2]=>
int(3)
[3]=>
int(4)
[4]=>
int(5)
[5]=>
int(6)
[6]=>
int(7)
[7]=>
int(8)
[8]=>
int(9)
}
실행 시간 초기 구성에서 소비되는 한 pair and in 똥더미를 다시 쌓고 반복해서 훑어보세요. 전체적으로 힙 정렬의 시간 복잡도는 O(nlogn)입니다. 힙 정렬은 원본 레코드의 정렬 상태에 민감하지 않으므로 최고, 최악, 평균 시간 복잡도는 O(nlogn)입니다. 이는 버블링, 간단한 선택 및 직접 삽입의 O(n^2) 시간 복잡도보다 성능 면에서 훨씬 더 좋습니다. 힙 정렬은 불안정한 정렬 방법입니다. 이 기사는 "Dahua 데이터 구조"를 참조했습니다. 나중에 참고할 수 있도록 여기에만 기록했습니다. 관련 추천: PHP 정렬 알고리즘 Quick Sort(Quick Sort) 및 최적화 PHP 정렬 알고리즘 Merging Sort(Merging Sort)
위 내용은 PHP 정렬 알고리즘 힙 정렬(Heap Sort)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!