
PHP 크롤러의 백만 레벨 Zhihu 사용자 데이터 크롤링 및 분석

- 不言원래의
- 2018-04-20 11:58:201919검색
이 기사의 내용은 PHP 크롤러를 통한 백만 레벨 Zhihu 사용자 데이터 크롤링 및 분석에 대한 것입니다. 이제 필요한 친구들이 참고할 수 있도록 공유합니다.
본 글은 주로 PHP 100만급 Zhihu 사용자 데이터 크롤링 및 분석 관련 정보를 소개하고 있으니 필요하신 분들은 참고하시면 됩니다
개발 전 준비사항
Linux 시스템 설치(Ubuntu14) .04), VMWare 가상 머신에 Ubuntu를 설치합니다.
-
MySQL5.5 이상을 설치합니다.
-
curl 및 pcntl 확장 프로그램을 설치하세요.
PHP의 컬 확장을 사용하여 페이지 데이터 가져오기 PHP의 컬 확장은 PHP에서 지원하는 라이브러리로, 다양한 유형의 프로토콜을 사용하여 다양한 서버와 연결하고 통신할 수 있습니다.
이 프로그램은 Zhihu 사용자 데이터를 캡처합니다. 사용자의 개인 페이지에 액세스하려면 사용자가 액세스하기 전에 로그인해야 합니다. 당사가 이용자의 개인센터 페이지에 진입하기 위해 브라우저 페이지의 이용자 아바타 링크를 클릭할 때 이용자의 정보를 볼 수 있는 이유는, 해당 링크를 클릭할 때 브라우저가 로컬 쿠키를 가져와 함께 제출할 수 있도록 도와주기 때문입니다. 새로운 페이지로 이동하여 사용자의 개인센터 페이지로 진입할 수 있습니다. 따라서 개인 페이지에 접속하기 전에 사용자의 쿠키 정보를 얻은 다음 각 컬 요청마다 쿠키 정보를 가져와야 합니다. 쿠키 정보를 얻으려면 다음 페이지에서 쿠키 정보를 볼 수 있습니다.
초기 예:
|
1 2 3 4 5 6 7 8 9 |
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此处mora-hu代表用户ID $ch = curl_init($url); //初始化会话 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //设置请求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的结果 |
모라후 사용자의 개인센터 페이지를 얻으려면 위의 코드를 실행하세요. 이 결과를 사용한 다음 정규 표현식을 사용하여 페이지를 처리하면 캡처해야 하는 이름, 성별 및 기타 정보를 얻을 수 있습니다.
1. 사진 핫링크 방지
반환된 결과를 정규화하여 개인정보를 출력할 때 페이지 출력시 사용자의 아바타가 열리지 않는 현상을 발견했습니다. 정보를 검토한 결과 Zhihu가 사진을 핫링크로부터 보호했기 때문이라는 것을 알게 되었습니다. 해결책은 이미지를 요청할 때 요청 헤더에 리퍼러를 위조하는 것입니다.
정규 표현식을 사용하여 이미지 링크를 얻은 후 이번에는 이미지 요청 소스를 가져와 해당 요청이 Zhihu 웹사이트에서 전달되었음을 나타냅니다. 구체적인 예는 다음과 같습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
function getImg($url, $u_id)
{
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg';
}
if (empty($url))
{
return '';
}
$context_options = array(
'http' =>
array(
'header' => "Referer:http://www.zhihu.com"//带上referer参数
)
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';
} |
2. 더 많은 사용자 크롤링
개인 정보를 확보한 후 해당 사용자의 팔로어 및 팔로우된 사용자 목록에 액세스해야 더 많은 사용자 정보를 얻을 수 있습니다. 그런 다음 레이어별로 방문하세요. 보시다시피 개인 센터 페이지에는 다음과 같은 두 개의 링크가 있습니다.
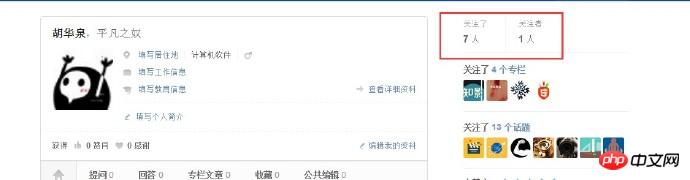
여기에는 두 개의 링크가 있으며 하나는 팔로우되고 다른 하나는 팔로워입니다. 일반 일치를 사용하여 해당 링크를 일치시킨 후 컬을 사용하여 쿠키를 가져오고 다른 요청을 보냅니다. 사용자가 팔로우한 목록 페이지를 캡처한 후 다음 페이지를 얻을 수 있습니다.
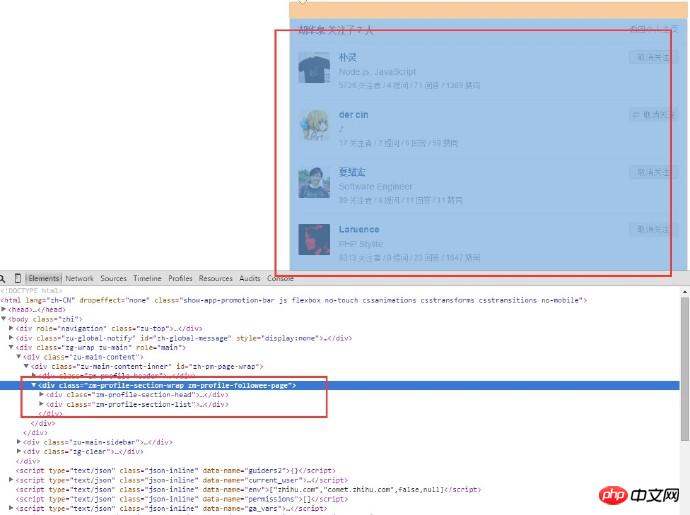
사용자의 정보만 가져오면 되므로 페이지의 html 구조를 분석합니다. 이 작품의 내용과 사용자 이름이 모두 여기에 있습니다. 사용자가 팔로우하는 페이지의 URL은 다음과 같습니다.

다른 사용자의 URL은 거의 동일하며 차이점은 사용자 이름에 있습니다. 일반 일치를 사용하여 사용자 이름 목록을 얻고, URL을 하나씩 입력한 다음 요청을 하나씩 보냅니다(물론 하나씩은 더 느리므로 아래에 해결 방법이 있으며 이에 대해서는 나중에 설명합니다). 새 사용자 페이지에 들어간 후 위 단계를 반복하고 원하는 데이터 양에 도달할 때까지 이 루프를 계속합니다.
3.리눅스 통계 파일 번호
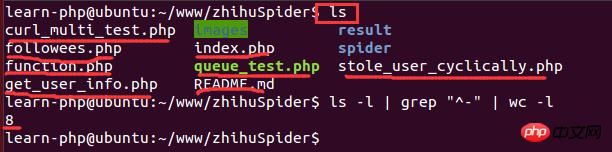
스크립트가 한동안 실행된 후, 데이터 양이 상대적으로 많을 경우, 얼마나 많은 사진을 얻었는지 확인해야 합니다. 폴더를 열어 사진 수를 확인하세요. 스크립트는 Linux 환경에서 실행되므로 Linux 명령을 사용하여 파일 수를 계산할 수 있습니다.
1 |
ls-l | grep"^-"wc -l |
그 중 ls -l은 디렉터리에 있는 파일 정보의 긴 목록 출력입니다(여기의 파일은 디렉터리, 링크, 장치 파일 등일 수 있음). grep "^-"는 긴 목록 출력 정보 "^-"를 필터링합니다. "는 일반 파일만 유지하고, 디렉토리만 유지하는 경우 "^d"입니다. wc -l은 통계 출력 정보의 행 수입니다. 다음은 실행 예입니다.
4. MySQL에 삽입 시 중복 데이터 처리
프로그램을 일정 기간 실행한 후 많은 사용자가 중복 데이터를 가지고 있는 것으로 나타났습니다. 따라서 처리할 중복된 사용자 데이터 시간을 삽입해야 합니다. 해결 방법은 다음과 같습니다.
1) 데이터베이스에 삽입하기 전에 데이터가 이미 데이터베이스에 존재하는지 확인하세요.
2) 고유 인덱스를 추가하고 INSERT INTO...ON DUPLICATE KEY UPDATE...
3를 사용하세요. ) 고유 인덱스 추가 및 삽입 INSERT INGNORE INTO 사용...
4) 고유 인덱스 추가 및 삽입 시 REPLACE INTO 사용...
첫 번째 옵션은 가장 간단하지만 효율성이 가장 낮은 옵션이므로 그렇지 않습니다. 채택. 두 번째와 네 번째 솔루션의 실행 결과는 동일하지만, 차이점은 동일한 데이터가 나타나면 INSERT INTO ... ON DUPLICATE KEY UPDATE가 직접 업데이트되는 반면, REPLACE INTO는 이전 데이터를 먼저 삭제한 후 새 데이터를 삽입한다는 점입니다. 이 과정에서 인덱스도 다시 유지해야 하므로 속도가 느려집니다. 그래서 저는 2번과 4번 사이에서 두 번째 옵션을 선택했습니다. 세 번째 옵션인 INSERT INGNORE는 INSERT 문을 실행할 때 발생하는 오류와 구문 문제를 무시하지 않지만 기본 키의 존재를 무시합니다. 이 경우 INSERT INGNORE를 사용하는 것이 더 좋습니다. 마지막으로 데이터베이스에 기록해야 할 중복 데이터의 수를 고려하여 프로그램에서는 두 번째 솔루션을 채택했습니다.
5. 멀티 스레드 페이지 캡처를 위해 컬멀티 사용
단일 프로세스와 단일 컬을 사용하여 데이터를 캡처하기 시작했는데 속도가 매우 느렸습니다. 밤을 새워서 생각해봤는데 새로운 사용자 페이지에 들어가서 컬 요청을 할 때 한 번에 여러 사용자를 요청할 수 있나요? 나중에 컬_멀티의 좋은 점을 발견했습니다. cur_multi와 같은 함수는 하나씩 요청하는 대신 동시에 여러 URL을 요청할 수 있습니다. 이는 실행을 위해 여러 스레드를 여는 Linux 시스템의 프로세스 기능과 유사합니다. 다음은 다중 스레드 크롤러를 구현하기 위해 컬_멀티를 사용하는 예입니다.
|
1 2 3 4# 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
$mh = curl_multi_init(); //返回一个新cURL批处理句柄
for ($i = 0; $i < $max_size; $i++)
{
$ch = curl_init(); //初始化单个cURL会话
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄
}
$user_arr = array();
do {
//运行当前 cURL 句柄的子连接
while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);
if ($cme != CURLM_OK) {break;}
//获取当前解析的cURL的相关传输信息
while ($done = curl_multi_info_read($mh))
{
$info = curl_getinfo($done['handle']);
$tmp_result = curl_multi_getcontent($done['handle']);
$error = curl_error($done['handle']);
$user_arr[] = array_values(getUserInfo($tmp_result));
//保证同时有$max_size个请求在处理
if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list))
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch);
$i++;
}
curl_multi_remove_handle($mh, $done['handle']);
}
if ($active)
curl_multi_select($mh, 10);
} while ($active);
curl_multi_close($mh);
return $user_arr; |
6. HTTP 429 요청이 너무 많음
curl_multi 함수를 사용하면 여러 요청을 동시에 보낼 수 있지만 실행 과정에서 동시에 200개의 요청을 보낸 것으로 나타났습니다. 요청을 반환할 수 없습니다. 즉, 패킷 손실이 발견되었습니다. 추가 분석을 위해 컬_getinfo 함수를 사용하여 각 요청 핸들 정보를 인쇄합니다. 이 함수는 HTTP 응답 정보가 포함된 연관 배열을 반환하며, 이는 요청에서 반환된 HTTP 상태 코드를 나타냅니다. 많은 요청의 http_code가 429인 것을 확인했습니다. 이 반환 코드는 너무 많은 요청이 전송되었음을 의미합니다. Zhihu가 크롤러 방지 보호 기능을 구현한 것으로 추측하여 다른 웹사이트에서 테스트한 결과 한 번에 200개의 요청을 보낼 때 문제가 없는 것으로 나타났습니다. 이는 Zhihu가 이와 관련하여 보호 기능을 구현했음을 입증한 것입니다. 일회성 요청 횟수가 제한되어 있습니다. 그래서 요청 횟수를 계속 줄여보니 5시에는 패킷 손실이 없는 것으로 나타났습니다. 이 프로그램에서는 한 번에 최대 5개의 요청만 보낼 수 있음을 보여줍니다. 비록 많지는 않지만 작은 개선입니다.
7. Redis를 사용하여 방문한 사용자를 저장합니다.
사용자를 잡는 과정에서 일부 사용자가 이미 방문했으며 해당 사용자의 팔로어 및 팔로잉 사용자가 이미 반복 처리되었음을 확인했습니다. 데이터베이스 수준에서 수행된 경우에도 프로그램은 요청을 보내기 위해 여전히 컬을 사용하므로 반복된 요청을 보내면 반복되는 네트워크 오버헤드가 많이 발생합니다. 또 다른 점은 캡처할 사용자를 다음 실행을 위해 임시로 한 곳에 저장해야 한다는 것입니다. 처음에는 배열에 배치했지만 나중에는 다중 프로세스에서 여러 프로세스를 추가해야 한다는 것을 알았습니다. 프로그래밍, 하위 프로세스는 프로그램 코드, 함수 라이브러리를 공유하지만 프로세스에서 사용되는 변수는 다른 프로세스에서 사용되는 변수와 완전히 다릅니다. 서로 다른 프로세스 간의 변수는 분리되어 있어 다른 프로세스에서 읽을 수 없으므로 배열을 사용할 수 없습니다. 그래서 처리된 사용자와 캡처할 사용자를 저장하기 위해 Redis 캐시를 사용하자고 생각했습니다. 이런 방식으로 실행이 완료될 때마다 사용자는 이미_request_queue 큐에 푸시되고 캡처할 사용자(즉, 각 사용자의 팔로워 및 팔로우된 사용자 목록)는 request_queue에 푸시된 다음 각 전에 실행 시 사용자는 request_queue에 있는 대기열로 푸시됩니다. 그런 다음 해당 사용자가 이미_request_queue에 있는지 확인합니다. 그렇다면 다음 항목으로 진행하고, 그렇지 않으면 실행을 계속합니다.
PHP에서 redis를 사용하는 예:
|
1 2 3 4 5 6 7 8 |
<?php
$redis = new Redis();
$redis->connect('127.0.0.1', '6379');
$redis->set('tmp', 'value');
if ($redis->exists('tmp'))
{
echo $redis->get('tmp') . "\n";
} |
8. PHP의 pcntl 확장을 사용하여 다중 프로세스 구현
사용자 정보의 다중 스레드 캡처를 구현하기 위해 cur_multi 함수로 전환한 후 프로그램을 하룻밤 동안 실행했는데 얻은 최종 데이터는 10W였습니다. 여전히 이상적인 목표를 달성할 수 없었기 때문에 계속해서 최적화를 했고 나중에 PHP에 다중 프로세스 프로그래밍을 달성할 수 있는 pcntl 확장이 있다는 것을 발견했습니다. 다음은 다중 프로그램 프로그래밍의 예입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//PHP多进程demo
//fork10个进程
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
echo "child process $i running\n";
//子进程执行完毕之后就退出,以免继续fork出新的子进程
exit($i);
}
}
//等待子进程执行完毕,避免出现僵尸进程
while (pcntl_waitpid(0, $status) != -1) {
$status = pcntl_wexitstatus($status);
echo "Child $status completed\n";
} |
9、在Linux下查看系统的cpu信息
实现了多进程编程之后,就想着多开几条进程不断地抓取用户的数据,后来开了8调进程跑了一个晚上后发现只能拿到20W的数据,没有多大的提升。于是查阅资料发现,根据系统优化的CPU性能调优,程序的最大进程数不能随便给的,要根据CPU的核数和来给,最大进程数最好是cpu核数的2倍。因此需要查看cpu的信息来看看cpu的核数。在Linux下查看cpu的信息的命令:
1 |
cat /proc/cpuinfo |
결과는 다음과 같습니다.
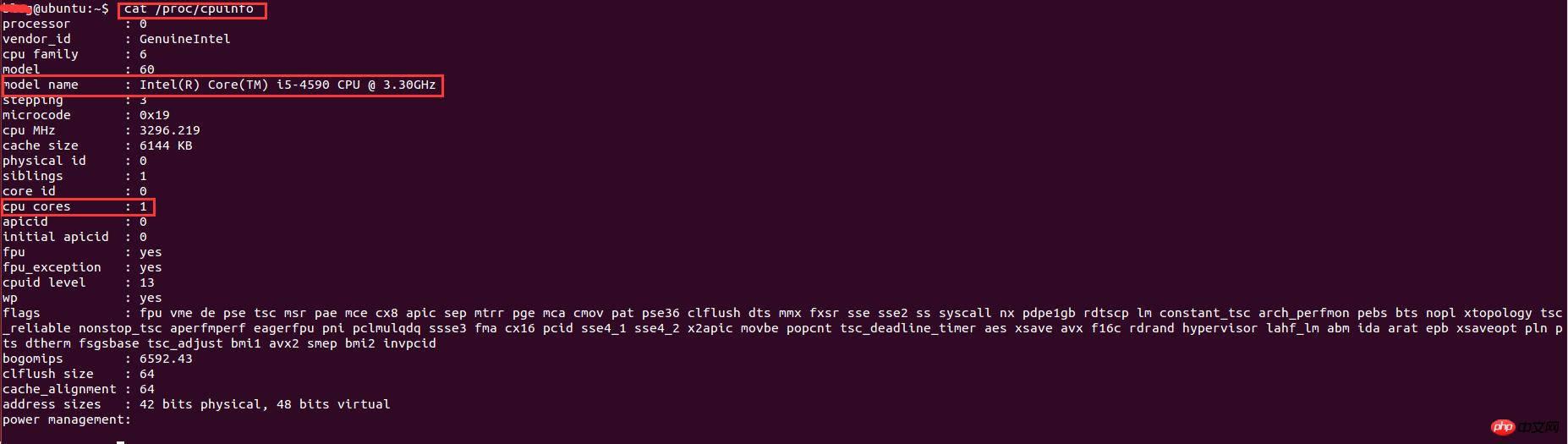
이 중 모델명은 CPU 유형 정보를 나타내고, CPU 코어는 CPU 코어 수를 나타냅니다. 여기서 코어 수는 1개입니다. 가상 머신에서 실행 중이기 때문에 할당된 CPU 코어 수가 상대적으로 적으므로 프로세스 2개만 열 수 있습니다. 최종 결과는 단 한 주말 동안 110만 명의 사용자 데이터가 수집되었다는 것입니다.
10. 다중 프로세스 프로그래밍에서 Redis와 MySQL 간의 연결 문제
다중 프로세스 조건에서 프로그램을 일정 기간 실행한 후 데이터를 삽입할 수 없는 것으로 나타났습니다. 이 방식은 redis에서도 마찬가지입니다.
다음 코드는 실행되지 않습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<?php
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
$redis = PRedis::getInstance();
// do something
exit;
}
} |
기본적인 이유는 각 하위 프로세스가 생성될 때 상위 프로세스의 동일한 복사본을 상속받기 때문입니다. 객체는 복사될 수 있지만 생성된 연결은 여러 객체로 복사될 수 없습니다. 결과적으로 각 프로세스는 동일한 Redis 연결을 사용하고 자체 작업을 수행하므로 결국 설명할 수 없는 충돌이 발생합니다.
해결책: >프로그램은 프로세스를 분기하기 전에 상위 프로세스가 Redis 연결 인스턴스를 생성하지 않는다는 것을 완전히 보장할 수 없습니다. 따라서 이 문제를 해결하는 유일한 방법은 하위 프로세스 자체를 이용하는 것입니다. 자식 프로세스에서 얻은 인스턴스가 현재 프로세스에만 관련되어 있다면 이 문제는 존재하지 않을 것이라고 상상해 보십시오. 따라서 해결책은 redis 클래스 인스턴스화의 정적 메서드를 약간 수정하고 이를 현재 프로세스 ID에 바인딩하는 것입니다.
수정된 코드는 다음과 같습니다.
|
1 2 3 4 5 6 7 8 9 10 |
<?php
public static function getInstance() {
static $instances = array();
$key = getmypid();//获取当前进程ID
if ($empty($instances[$key])) {
$inctances[$key] = new self();
}
return $instances[$key];
} |
11. PHP 통계 스크립트 실행 시간
각 프로세스에 걸리는 시간을 알고 싶어서 스크립트 실행 시간을 계산하는 함수를 작성합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function microtime_float()
{
list($u_sec, $sec) = explode(' ', microtime());
return (floatval($u_sec) + floatval($sec));
}
$start_time = microtime_float();
//do something
usleep(100);
$end_time = microtime_float();
$total_time = $end_time - $start_time;
$time_cost = sprintf("%.10f", $total_time);
echo "program cost total " . $time_cost . "s\n"; |
위 내용은 참고용으로 이 글의 전체 내용입니다. 공부에 도움이 되길 바랍니다.
관련 추천:
위 내용은 PHP 크롤러의 백만 레벨 Zhihu 사용자 데이터 크롤링 및 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!