
Python을 사용하여 js의 콘텐츠를 크롤링하는 방법

- 零到壹度원래의
- 2018-04-10 09:54:129525검색
이 글의 내용은 Python을 사용하여 js에서 콘텐츠를 크롤링하는 방법을 공유하는 것입니다. 특정 참조 값이 있습니다. 필요한 친구가 참조할 수 있습니다.
1. 작성 시 획득 크롤러 소프트웨어 필요한 콘텐츠를 발견하면 필요한 콘텐츠가 자바스크립트로 추가되고 획득 시 비어 있는 것을 발견할 수 있습니다. 예를 들어 Sina News에서 댓글 수를 얻을 때 일반적인 방법으로는 얻을 수 없습니다
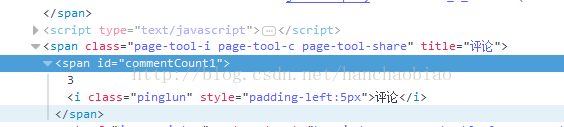
일반 검색 코드 예:
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
이번에 얻은 결과는 비어 있습니다. 이는 콘텐츠가 js 파일에 저장되어 있기 때문입니다.
그래서 우리는 댓글 내용을 검색한 결과 변경된 In js
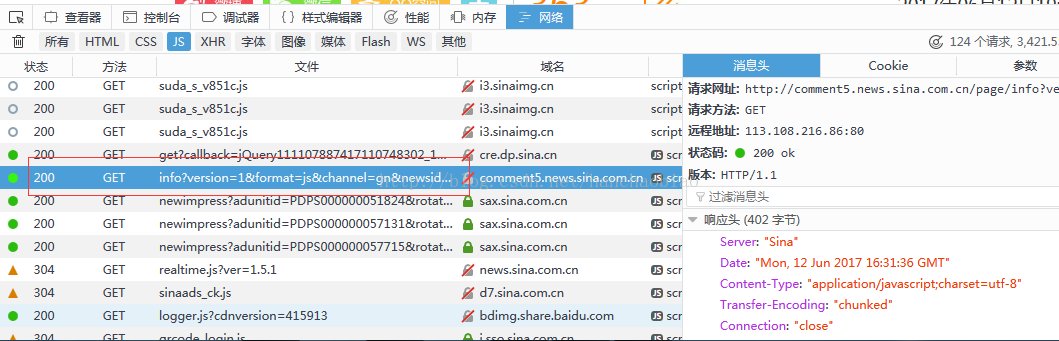
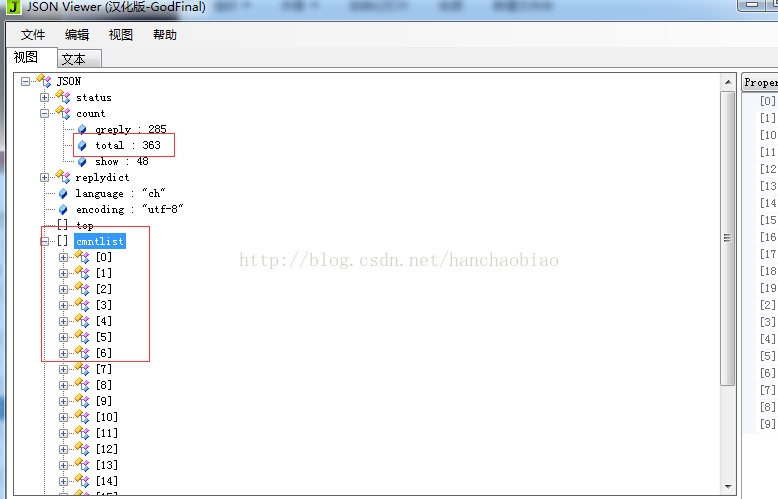
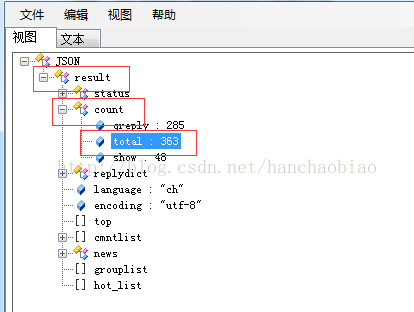
에 해당 내용이 저장되어 있는 것을 발견했습니다. json 데이터 뷰어에 총 댓글 수와 댓글의 내용이 나와 있습니다. js 파일에 json 형식으로 저장
메시지에 헤더에서 js 파일의 액세스 경로와 요청 방법을 볼 수 있습니다
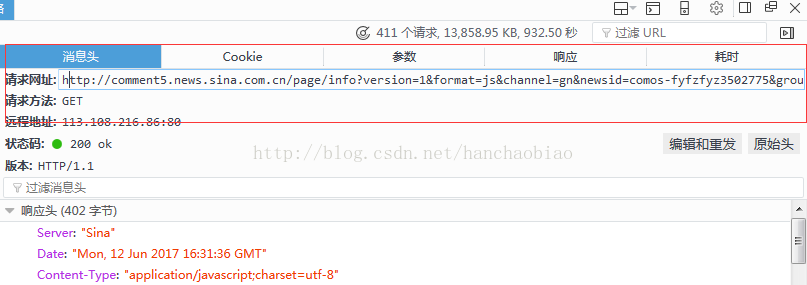
코드 예시
import json comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783') comments.encoding = 'utf-8' print(comments) jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据 print(jd['result']['count']['total'])
참고: var data=를 가져올 때 문자열 접두사가 json 데이터 형식을 따르지 않으므로 var data=를 제거해야 하는 이유에 대한 설명은 다음과 같습니다. 따라서 요청에서 제거해야 합니다. 변환 중 콘텐츠

총 댓글 수를 가져올 때 jd['result']['count'를 사용하는 이유 ]['total']
위 내용은 Python을 사용하여 js의 콘텐츠를 크롤링하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
이전 기사:Anaconda의 초보자 가이드다음 기사:Anaconda의 초보자 가이드