
Python이 Sogou WeChat 공개 계정 기사의 영구 링크를 크롤링하는 방법에 대한 아이디어 분석

- 零到壹度원래의
- 2018-04-04 11:51:227884검색
이 기사는 Sogou WeChat 공식 계정 기사의 영구 링크를 Python이 어떻게 크롤링하는지에 대한 아이디어 분석을 주로 소개합니다. 편집자는 이것이 꽤 좋다고 생각합니다. 이제 공유하고 참고로 제공하겠습니다. 편집자를 따라가서 살펴보겠습니다.
이 글은 주로 아이디어를 설명하고 있으니, 코드 부분은 직접 풀어보세요
Sogou WeChat 검색으로 공개 계정과 글을 얻으세요
WeChat 공개 플랫폼을 통해 영구 링크를 받으세요
python+scrapy 프레임워크
mysql 데이터베이스 저장 + 공개 계정 읽기
Sogou WeChat에서 오늘의 정보 순위를 확인하세요
입력 키워드를 지정하고 scrapy를 통해 공개 계정을 확보하세요
WeChat 공개 계정 링크에 로그인하여 쿠키 정보 얻기
WeChat 공개 플랫폼에 대한 모의 로그인이 아직 해결되지 않았기 때문에 수동으로 로그인해야 실시간으로 쿠키 정보를 얻을 수 있습니다

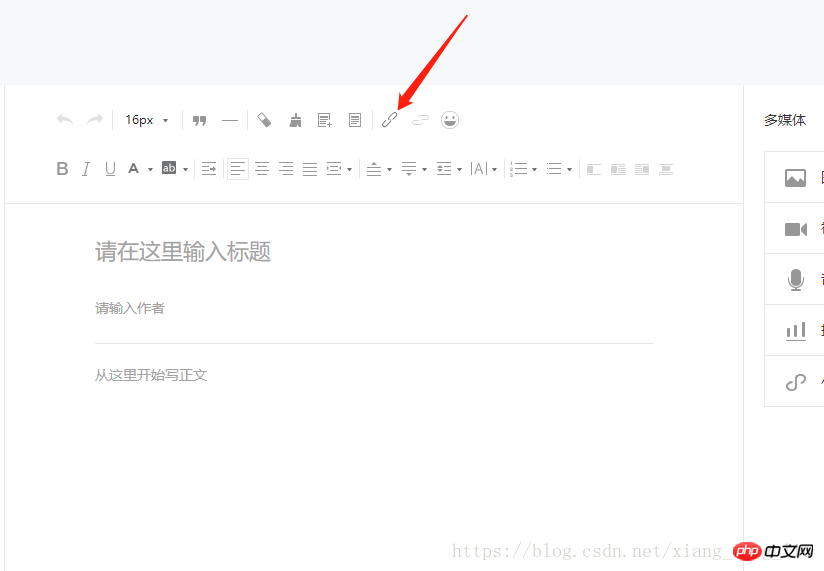
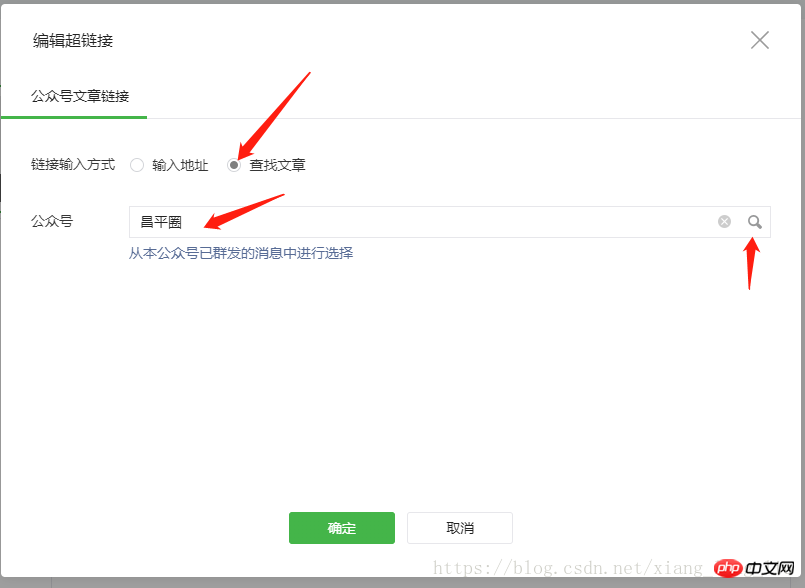
여기에서 영구 링크
코드 부분
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin?query="+name+"&type=2&page=1&ie=utf8"
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})Sogou WeChat을 변환할 수 있습니다. 액세스 빈도가 너무 빨라 인증 코드를 입력해야 할 수 있습니다
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=938949250&lang=zh_CN",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&token=938949250&lang=zh_CN&f=json&ajax=1&query=" + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=610084158&lang=zh_CN&f=json&ajax=1&random=0.7159556076774083&action=list_ex&begin=0&count=5&query=" + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=938949250&f=json&action=list_ex&count=5&query=&fakeid=" + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=1773340085&lang=zh_CN&f=json&ajax=1&action=list_ex&begin=0&count=5&query=" + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=938949250&f=json&ajax=1&action=list_ex&begin=0&count=5&query=" + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin?query="+name+"&type=2&page="+str(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})위 내용은 Python이 Sogou WeChat 공개 계정 기사의 영구 링크를 크롤링하는 방법에 대한 아이디어 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.