
Python 동적 크롤러 공유 예

- 小云云원래의
- 2018-03-30 16:41:113890검색
이 기사에서는 주로 Python 동적 크롤러의 예를 공유합니다. Python을 사용하여 기존 정적 웹 페이지를 크롤링할 때 urllib2를 사용하여 전체 HTML 페이지를 얻은 다음 HTML 파일에서 해당 키워드를 단어별로 검색하는 경우가 많습니다. 아래와 같이:
#encoding=utf-8
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"up=urllib2.urlopen(url)#打开目标页面,存入变量upcont=up.read()#从up中读入该HTML文件key1='<a><p style="text-align: left;"> 그러나 동적 페이지에서는 표시된 내용이 HTML 페이지를 통해 표시되지 않는 경우가 많지만 js 및 기타 메서드를 호출하여 데이터베이스에서 데이터를 가져와 웹 페이지에 반영합니다. </p> <p style="text-align: left;">국가발전개혁위원회 홈페이지의 '등록정보'(http://beian.hndrc.gov.cn/)를 예로 들어 이 페이지에 있는 신고사항 중 일부를 캡쳐하고 싶습니다. 예를 들어 "http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518"입니다. </p> <p style="text-align: left;">그런 다음 브라우저에서 이 페이지를 엽니다: </p> <p style="text-align:center"><img src="https://img.php.cn/upload/article/000/054/025/98318b42d241c7349e8445d46350a605-0.png" alt="Python 동적 크롤러 공유 예관련 정보가 완전히 표시되지만 이전 방법인 </p><pre class="brush:php;toolbar:false;">up=urllib2.urlopen(url) cont=up.read()
을 따르면 위 내용을 캡처할 수 없습니다.
이 페이지의 해당 소스 코드를 살펴보겠습니다.
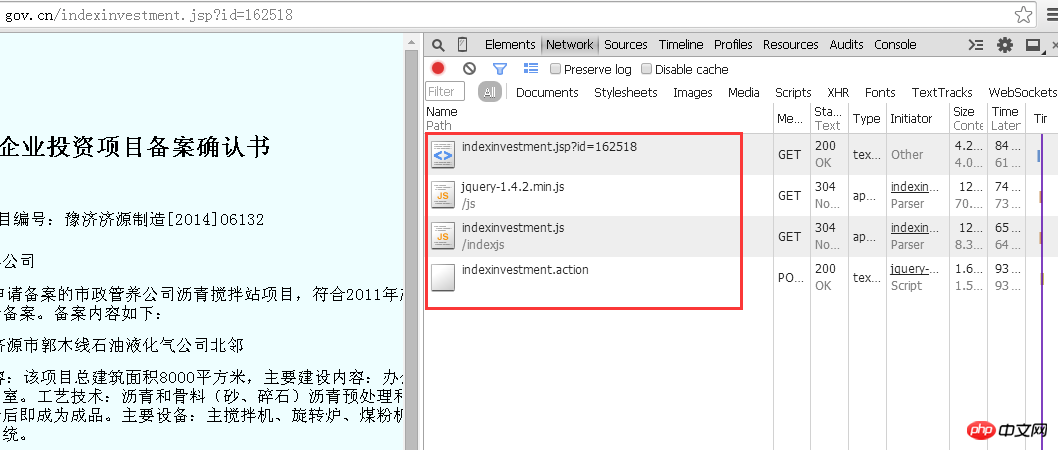
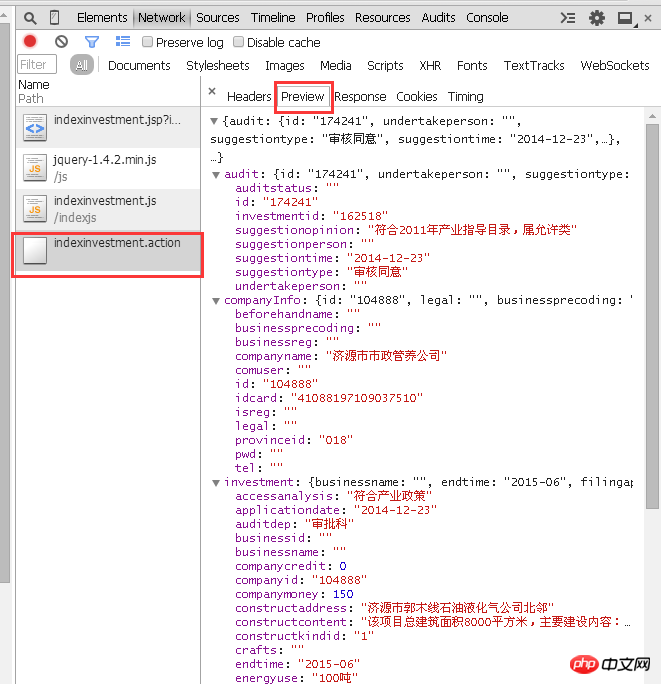
대상 URL의 경우 ID가 162518인 매개변수가 POST를 통해 전달됩니다.
먼저 수동으로 해보자. js는 매개변수를 어떻게 호출하나요? 예, 위에서 언급한 대로 물음표 + 변수 이름 + 등호 + 변수에 해당하는 숫자입니다. 즉, ID가 162518인 매개변수를 "http://beian.hndrc.gov.cn/indexinvestment.action" 페이지에 제출할 때 URL 뒤에
"?id=162518"을 추가해야 합니다. 즉,
"http://beian.hndrc.gov.cn/indexinvestment.action?id=162518".
이 URL을 브라우저에 붙여넣어 확인해 보겠습니다.

그런 다음 for, while 및 기타 루프를 사용하여 이러한 "등록 문서"를 일괄적으로 가져옵니다.
"정적 웹 페이지든, 동적 웹 페이지든, 시뮬레이션된 로그인 등이든 코드를 작성하기 전에 먼저 논리를 분석하고 이해해야 합니다"처럼 프로그래밍 언어는 도구일 뿐이고 중요한 것 문제를 해결하자는 생각이다. 아이디어가 떠오르면 문제를 해결하기 위한 도구를 찾아보면 됩니다.
위 내용은 Python 동적 크롤러 공유 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!