
완전한 크롤러 프레임워크를 작성하는 방법

- 零到壹度원래의
- 2018-03-30 11:28:404889검색
이 글은 크롤러 프레임워크에 대한 요청 메소드를 완벽하게 작성하는 방법을 주로 공유합니다. 이는 좋은 참고 가치가 있으며 모든 사람에게 도움이 되기를 바랍니다. 편집자를 따라가서 모두에게 도움이 되기를 바랍니다.
크롤러 프레임워크 생성:
1. 스크래피 크롤러 프로젝트를 생성합니다
2. 프로젝트에서 스크래피 크롤러를 생성합니다
3. 크롤러를 실행합니다. , 웹페이지 가져오기
특정 작업:
1. 프로젝트 만들기
프로젝트 이름 정의: python123demo
방법:
cm 단위 d, d: D 드라이브를 입력하세요 , cd pycodes pycodes
파일을 입력한 다음
scrapy startproject python123demo
파일이 pycodes로 생성됩니다.

 _init_.py는 그렇지 않습니다.
_init_.py는 그렇지 않습니다.


2. 프로젝트에서 스크래피 크롤러를 생성합니다
명령을 실행하고 크롤러 이름을 지정하고 크롤링된 웹사이트
크롤링을 생성합니다. 어:
 demo라는 이름의 스파이더를 생성합니다
demo라는 이름의 스파이더를 생성합니다
demo.py만 생성합니다. 내용은 다음과 같습니다.
 name = 'demo' 현재 크롤러 이름은 데모
name = 'demo' 현재 크롤러 이름은 데모
입니다. 허용됨 _domains = " 웹 사이트의 도메인 이름 아래 링크를 크롤링합니다. 도메인 이름은 cmd 명령 콘솔에서 입력합니다
start_urls = [] 크롤링된 초기 페이지
parse()를 사용하여 해당 항목을 처리합니다. 콘텐츠를 구문 분석하여 사전을 형성하고 새로운 URL 크롤링 요청을 발견하세요
3. 생성된 스파이더 크롤러를 우리의 요구에 맞게 구성하세요
파싱된 페이지를 파일에 저장하세요
데모를 수정하세요. py file

4. 크롤러를 실행하고 웹페이지를 가져옵니다.
cmd를 열고 명령줄을 입력하여 크롤링합니다.
 컴퓨터에 오류가 발생했습니다.
컴퓨터에 오류가 발생했습니다.
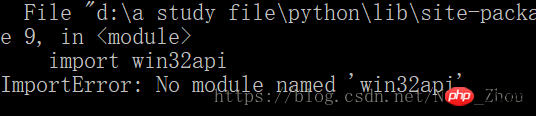 windows 시스템 이 문제를 해결하려면 Py32Win 모듈을 설치해야 하는데, 공식 홈페이지 링크를 통해 exe를 직접 설치하면 수백 가지 오류가 발생하기 때문에 더 편리한 방법은
windows 시스템 이 문제를 해결하려면 Py32Win 모듈을 설치해야 하는데, 공식 홈페이지 링크를 통해 exe를 직접 설치하면 수백 가지 오류가 발생하기 때문에 더 편리한 방법은
입니다.
pip3 install pypiwin32
이것은 py3 솔루션입니다
참고: py3 버전에 pip install pypiwin32 명령을 사용하면 오류가 발생합니다
설치가 완료된 후 다시 크롤러를 실행하세요.
캡처 페이지는 데모.html 파일에 저장됩니다.

demo.py 해당 전체 코드:

두 버전은 동일합니다:

위 내용은 완전한 크롤러 프레임워크를 작성하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!