|
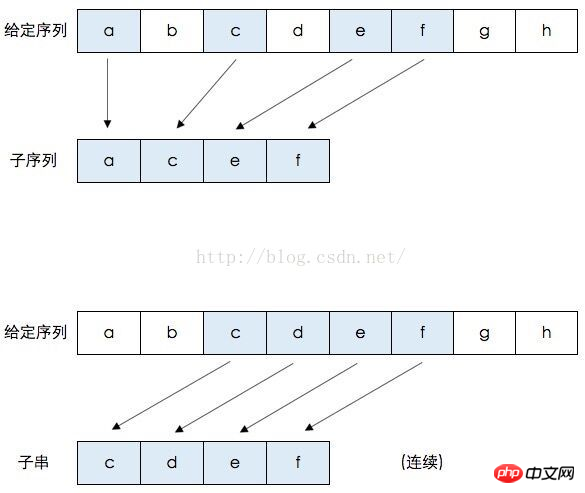
그리고 두 문자열 사이에서 비교할 문자가 다른 경우 채워질 그리드는 왼쪽 또는 위쪽에 관련되며 더 큰 쪽이 사용된다는 것을 확신할 수 있습니다.
비교된 문자가 동일한 경우 걱정하지 마세요. X의 C를 Y의 C, 즉 ABC의 하위 시퀀스 집합 {"",A,B,C, AB,BC,ABC} 및 BDC 하위 시퀀스 집합 {"",B,D,C,BD,DC,BDC}를 비교하면 얻은 공통 하위 문자열은 "",B,D입니다. 이때 결론은 여전히 이전과 동일합니다. 문자가 동일할 경우 해당 그리드 값은 왼쪽, 오른쪽, 왼쪽 위 모서리의 값과 같고 왼쪽, 위, 왼쪽 위 모서리의 값은 같습니다. 항상 평등합니다. 이러한 미스터리를 입증하려면 더 엄격한 수학적 지식이 필요합니다.
A와 B라는 두 개의 배열이 있다고 가정합니다. A[i]는 A의 i번째 요소이고, A(i)는 A의 첫 번째 요소에서 i번째 요소로 구성된 접두사입니다. m(i, j)는 A(i)와 B(j)의 가장 긴 공통 부분 수열 길이입니다.
알고리즘 자체의 재귀적 특성으로 인해 특정 i와 j에 대해서만 증명하면 됩니다.
m(i, j) = m(i-1, j-1) + 1 (A[ i] = B [j])
m(i, j) = max( m(i-1, j), m(i, j-1) ) (A[i] != B[j]일 때)
첫 번째 공식은 A[i] = B[j]일 때 증명하기 쉽습니다. m(i, j) > m(i-1, j-1) + 1(m(i, j)은 m(i-1, j-1) +보다 작을 수 없다고 가정하여 반대 증명을 사용할 수 있습니다. 1, 많은 이유가 있습니다. 분명히) 그러면 m(i-1, j-1)이 가장 길지 않다는 모순된 결과를 추론할 수 있습니다.
두 번째는 좀 까다롭습니다. A[i] != B[j]인 경우 m(i, j) > max( m(i-1, j), m(i, j-1) )라고 가정하면 여전히 반증입니다.
반증 가설을 통해 m(i, j) > m(i-1, j)를 얻을 수 있습니다. 이는 A[i]가 m(i, j)에 해당하는 LCS 시퀀스에 있어야 한다고 추론할 수 있습니다(모순되는 증거가 있음). 그리고 A[i] != B[j]이므로 B[j]는 m(i, j)에 해당하는 LCS 시퀀스에 있어서는 안 됩니다. 따라서 m(i, j) = m(i, j-1)이라고 추론할 수 있습니다. 이는 어쨌든 가설과 모순되는 결과를 낳는다.
인증을 받으세요.
이제 아래 방정식을 사용하여 표를 계속 채웁니다.
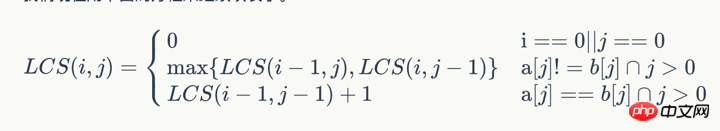
프로그램 구현
//by 司徒正美
function LCS(str1, str2){
var rows = str1.split("")
rows.unshift("")
var cols = str2.split("")
cols.unshift("")
var m = rows.length
var n = cols.length
var dp = []
for(var i = 0; i < m; i++){
dp[i] = []
for(var j = 0; j < n; j++){
if(i === 0 || j === 0){
dp[i][j] = 0
continue
}
if(rows[i] === cols[j]){
dp[i][j] = dp[i-1][j-1] + 1 //对角+1
}else{
dp[i][j] = Math.max( dp[i-1][j], dp[i][j-1]) //对左边,上边取最大
}
}
console.log(dp[i].join(""))//调试
}
return dp[i-1][j-1]
}LCS는 위치를 이동하는 것만으로 더욱 단순화할 수 있으므로 새 배열을 생성할 필요가 없습니다. //by司徒正美
function LCS(str1, str2){
var m = str1.length
var n = str2.length
var dp = [new Array(n+1).fill(0)] //第一行全是0
for(var i = 1; i <= m; i++){ //一共有m+1行
dp[i] = [0] //第一列全是0
for(var j = 1; j <= n; j++){//一共有n+1列
if(str1[i-1] === str2[j-1]){
//注意这里,str1的第一个字符是在第二列中,因此要减1,str2同理
dp[i][j] = dp[i-1][j-1] + 1 //对角+1
} else {
dp[i][j] = Math.max( dp[i-1][j], dp[i][j-1])
}
}
}
return dp[m][n];
}LCS를 인쇄하세요 인쇄 기능을 제공하겠습니다. 먼저 인쇄하는 방법을 살펴보세요. 오른쪽 하단에서 시작하여 맨 위 줄에서 끝납니다. 따라서 대상 문자열은 역순으로 구성됩니다. stringBuffer와 같은 번거로운 중간 수량의 사용을 피하기 위해 프로그램이 실행될 때마다 하나의 문자열만 반환하고 그렇지 않으면 printLCS(x,y,...)를 사용하여 빈 문자열을 반환합니다. str[ i] 필요한 문자열을 얻기 위해 추가됩니다. 우리가 얻은 문자열이 실제 LCS 문자열인지 확인하는 또 다른 방법을 작성해 보겠습니다. 이미 일하고 있는 사람으로서 학교에서 학생처럼 단위 테스트를 하고 다른 사람들이 밟을 수 있도록 온라인에 올리지 않고는 코드를 작성할 수 없습니다. //by 司徒正美,打印一个LCS
function printLCS(dp, str1, str2, i, j){
if (i == 0 || j == 0){
return "";
}
if( str1[i-1] == str2[j-1] ){
return printLCS(dp, str1, str2, i-1, j-1) + str1[i-1];
}else{
if (dp[i][j-1] > dp[i-1][j]){
return printLCS(dp, str1, str2, i, j-1);
}else{
return printLCS(dp, str1, str2, i-1, j);
}
}
}
//by司徒正美, 将目标字符串转换成正则,验证是否为之前两个字符串的LCS
function validateLCS(el, str1, str2){
var re = new RegExp( el.split("").join(".*") )
console.log(el, re.test(str1),re.test(str2))
return re.test(str1) && re.test(str2)
}
사용:
function LCS(str1, str2){
var m = str1.length
var n = str2.length
//....略,自行补充
var s = printLCS(dp, str1, str2, m, n)
validateLCS(s, str1, str2)
return dp[m][n]
}
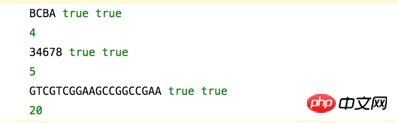
var c1 = LCS( "ABCBDAB","BDCABA");
console.log(c1) //4 BCBA、BCAB、BDAB
var c2 = LCS("13456778" , "357486782" );
console.log(c2) //5 34678
var c3 = LCS("ACCGGTCGAGTGCGCGGAAGCCGGCCGAA" ,"GTCGTTCGGAATGCCGTTGCTCTGTAAA" );
console.log(c3) //20 GTCGTCGGAAGCCGGCCGAA
모든 LCS 인쇄
아이디어는 위와 유사합니다. LCS 방법에는 Math.max 값이 있습니다. 이는 실제로 세 가지 상황을 통합합니다. 그래서 세 개의 문자열을 분기할 수 있습니다. 우리의 메소드는 자동 제거를 위해 es6 컬렉션 객체를 반환합니다. 그런 다음 새 세트를 사용하여 이전 세트의 문자열을 병합할 때마다.
//by 司徒正美 打印所有LCS
function printAllLCS(dp, str1, str2, i, j){
if (i == 0 || j == 0){
return new Set([""])
}else if(str1[i-1] == str2[j-1]){
var newSet = new Set()
printAllLCS(dp, str1, str2, i-1, j-1).forEach(function(el){
newSet.add(el + str1[i-1])
})
return newSet
}else{
var set = new Set()
if (dp[i][j-1] >= dp[i-1][j]){
printAllLCS(dp, str1, str2, i, j-1).forEach(function(el){
set.add(el)
})
}
if (dp[i-1][j] >= dp[i][j-1]){//必须用>=,不能简单一个else搞定
printAllLCS(dp, str1, str2, i-1, j).forEach(function(el){
set.add(el)
})
}
return set
}
}
사용:
function LCS(str1, str2){
var m = str1.length
var n = str2.length
//....略,自行补充
var s = printAllLCS(dp, str1, str2, m, n)
console.log(s)
s.forEach(function(el){
validateLCS(el,str1, str2)
console.log("输出LCS",el)
})
return dp[m][n]
}
var c1 = LCS( "ABCBDAB","BDCABA");
console.log(c1) //4 BCBA、BCAB、BDAB
var c2 = LCS("13456778" , "357486782" );
console.log(c2) //5 34678
var c3 = LCS("ACCGGTCGAGTGCGCGGAAGCCGGCCGAA" ,"GTCGTTCGGAATGCCGTTGCTCTGTAAA" );
console.log(c3) //20 GTCGTCGGAAGCCGGCCGAA

공간 최적화
롤링 배열 사용:
function LCS(str1, str2){
var m = str1.length
var n = str2.length
var dp = [new Array(n+1).fill(0)],now = 1,row //第一行全是0
for(var i = 1; i <= m; i++){ //一共有2行
row = dp[now] = [0] //第一列全是0
for(var j = 1; j <= n; j++){//一共有n+1列
if(str1[i-1] === str2[j-1]){
//注意这里,str1的第一个字符是在第二列中,因此要减1,str2同理
dp[now][j] = dp[i-now][j-1] + 1 //对角+1
} else {
dp[now][j] = Math.max( dp[i-now][j], dp[now][j-1])
}
}
now = 1- now; //1-1=>0;1-0=>1; 1-1=>0 ...
}
return row ? row[n]: 0
}
위험한 재귀 솔루션
str1의 하위 시퀀스는 아래 첨자 시퀀스 {1, 2 , . .., m}의 하위 수열입니다. 따라서 str1에는 총 ${2^m}$개의 서로 다른 하위 수열이 있으므로(${2^n}$과 같이 str2의 경우에도 마찬가지) 복잡성이 놀라울 정도로 커집니다. 지수 시간( ${2^m * 2^n}$).
//警告,字符串的长度一大就会爆栈
function LCS(str1, str2, a, b) {
if(a === void 0){
a = str1.length - 1
}
if(b === void 0){
b = str2.length - 1
}
if(a == -1 || b == -1){
return 0
}
if(str1[a] == str2[b]) {
return LCS(str1, str2, a-1, b-1)+1;
}
if(str1[a] != str2[b]) {
var x = LCS(str1, str2, a, b-1)
var y = LCS(str1, str2, a-1, b)
return x >= y ? x : y
}
}
이 기사의 사례를 읽으신 후 방법을 마스터하셨다고 믿습니다. 더 흥미로운 정보를 보려면 PHP 중국어 웹사이트의 다른 관련 기사를 주목하세요!
추천 도서:
datepicker 사용 방법
NavigatorIOS 컴포넌트 사용에 대한 자세한 설명
Vue.js에서 ejsExcel 템플릿 사용
|