
Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다.

- 小云云원래의
- 2018-03-07 14:01:354196검색
1. 소개
크롤러 프로그램을 사용하여 웹 페이지를 크롤링할 때 일반적으로 정적 페이지를 크롤링하는 것은 상대적으로 간단하며 이전에도 많은 사례를 작성했습니다. 하지만 js를 사용하여 동적으로 로드된 페이지를 크롤링하는 방법은 무엇입니까?
동적 js 페이지에는 여러 가지 크롤링 방법이 있습니다.
selenium+phantomjs를 통해 구현됩니다.
phantomjs는 헤드리스 브라우저이고 Selenium은 자동화된 테스트 프레임워크입니다. 헤드리스 브라우저를 통해 페이지를 요청하고 js가 로드될 때까지 기다린 다음 자동화된 테스트 Selenium을 통해 데이터를 얻습니다. 헤드리스 브라우저는 많은 리소스를 소비하기 때문에 성능이 부족합니다.
Scrapy-splash 프레임워크:
Splash는 js 렌더링 서비스로서 Twisted 및 QT를 기반으로 개발된 경량 브라우저 엔진이며 직접 http api를 제공합니다. 빠르고 가벼운 기능 덕분에 분산 개발이 쉬워졌습니다.
splash 및 scrapy 크롤러 프레임워크는 서로 호환되며 더 나은 크롤링 효율성을 제공합니다.
2. Splash 환경 구축
Splash 서비스는 docker 컨테이너를 기반으로 하기 때문에 먼저 docker 컨테이너를 설치해야 합니다.
2.1 Docker 설치(windows 10 home 버전)
win 10 Professional 버전이거나 다른 운영 체제인 경우 Windows 10 home 버전에 docker를 설치하려면 도구 상자를 통해 설치해야 합니다. 최신) 도구입니다.
docker 설치에 관해서는 문서를 참고하세요: WIN10에 Docker 설치
2.2 Splash 설치
docker pull scrapinghub/splash
2.3 Start Splash service
docker run -p 8050:8050 scrapinghub/splash
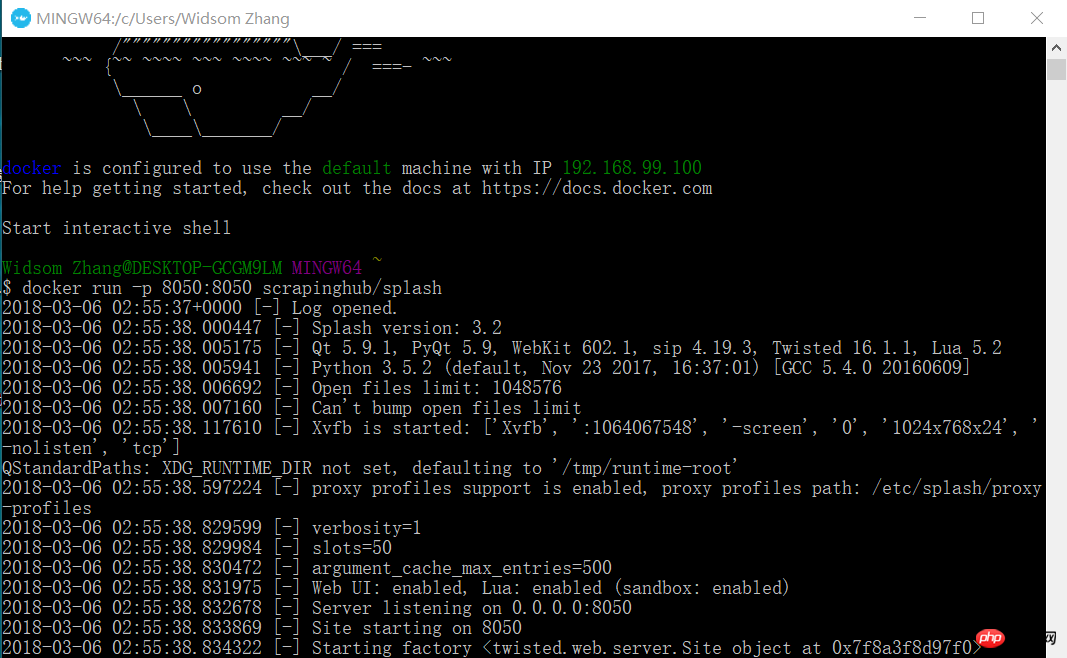
이때 브라우저를 열고 192.168.99.100:8050을 입력하세요. 이와 같은 인터페이스가 나타납니다.
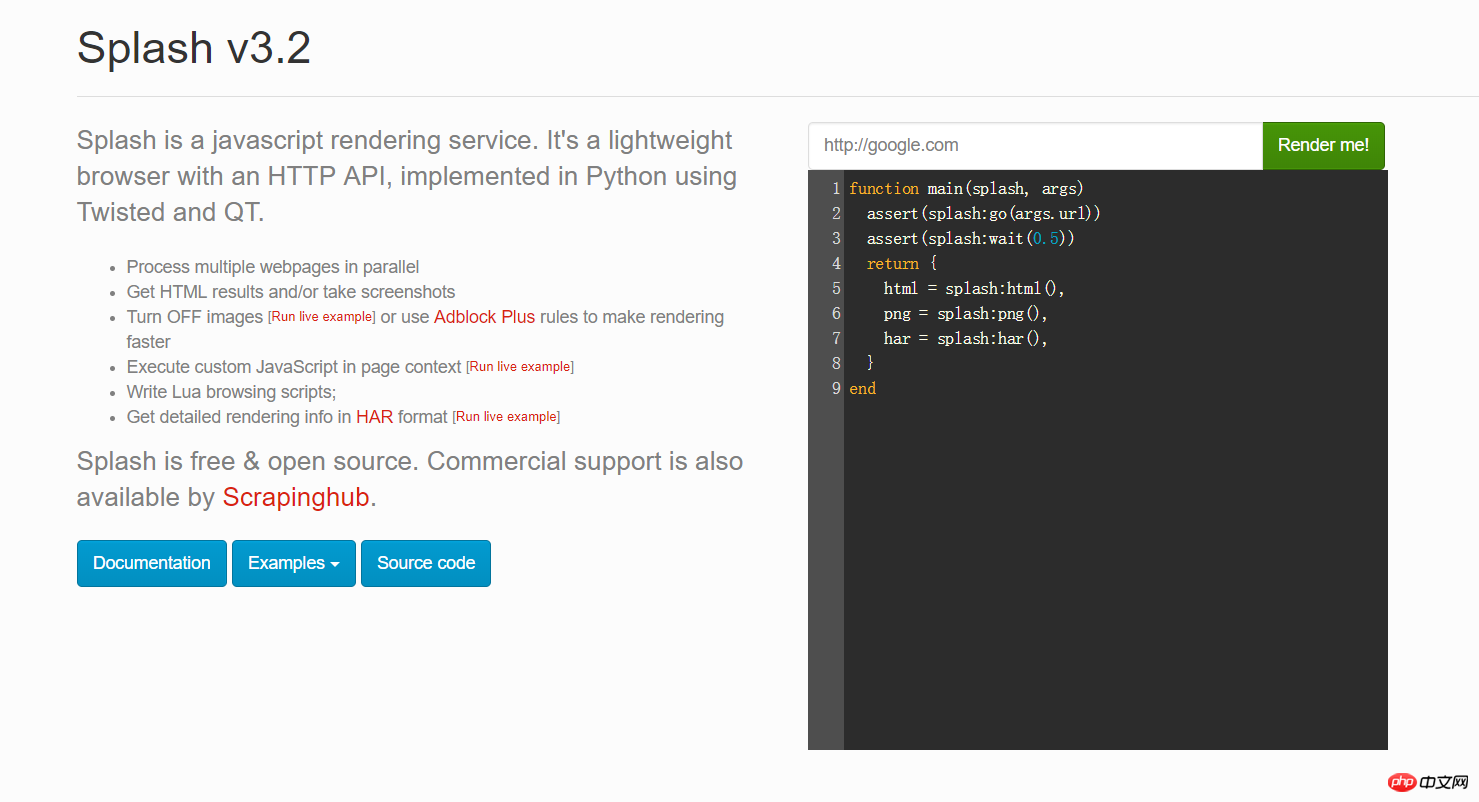
위 그림의 빨간색 상자에 URL을 입력할 수 있습니다. 렌더링 후의 모습을 보려면 Render me!를 클릭하세요.
2.4 Python의 scrapy-splash 패키지 설치
pip install scrapy-splash
3 Scrapy 크롤러는 js 프로젝트를 로드합니다. Google 뉴스를 예로 들어 테스트 중입니다.
비즈니스 요구로 인해 Google 뉴스와 같은 일부 외국 뉴스 웹사이트를 크롤링합니다. 하지만 실제로는 js 코드라는 것을 알았습니다. 그래서 scrapy-splash 프레임워크를 사용하기 시작했고 Splash의 js 렌더링 서비스와 협력하여 데이터를 얻었습니다. 구체적으로 다음 코드를 살펴보세요.
3.1 settings.py 구성 정보
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 항목 필드 정의
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다._url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 스파이더 코드
스파이더 디렉터리에서 다음 콘텐츠로 new_spider.py 파일을 만듭니다.
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다.Url = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다._url'] = Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다.Url
item['action_url'] = actionUrl
item['source'] = source yield item3.4 파이프라인 .py 코드
는 항목 데이터를 mysql 데이터베이스에 저장합니다.
db_news 데이터베이스 생성
CREATE DATABASE db_news
tb_news 테이블 생성
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다._url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipeline 클래스
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다._url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다._url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 scrapy 크롤러 실행
콘솔에서 실행:
scrapy crawl google_news
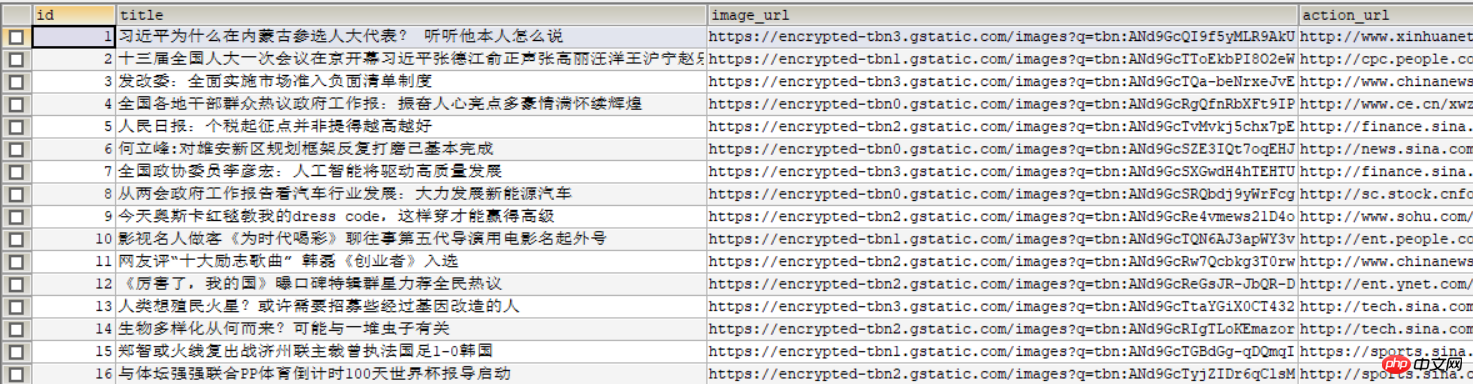
다음 사진이 데이터베이스에 표시됩니다:
관련 권장 사항:
위 내용은 Scrapy 및 scrapy-splash 프레임워크는 js 페이지를 빠르게 로드합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!