
Node.js가 Douban 데이터를 크롤링하는 방법에 대한 공유 예

- 小云云원래의
- 2018-03-06 09:18:161382검색
저는 항상 제 vue가 좋다고 생각했고, webpack이 좋다고 생각했어요. 오늘 MOOC에서 node를 탐색하면서 아직 멀었다는 걸 깨달았습니다. 다들 아시다시피 vue-cli는 webpack 기반이고, webpack은 node 기반입니다. node를 모른다면 webpack을 어떻게 이해할 수 있을까요? 그래서 아직 초기 단계인 Douban 데이터를 크롤링하기 위해 스스로에게 질문을 던졌습니다. 오늘은 Douban에서 크롤링한 데이터에 대해 간략하게 설명하고 나중에 다른 페이지에 자신만의 방식으로 표시해 보겠습니다.
1. 해결해야 할 문제
서비스 구축
크롤링 데이터 처리 방법
기본 브라우저를 자동으로 여는 방법
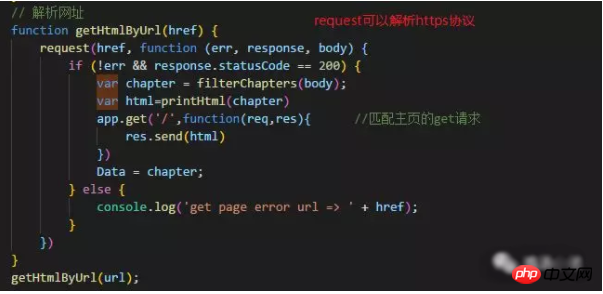
2. 서비스 구축 처음에는 http를 사용했는데, http의 한 가지 단점은 https 프로토콜의 URL을 파싱할 수 없다는 것이므로 express를 사용하여 https 프로토콜의 URL을 파싱했습니다.
오늘 URL https://movie.douban.com/chart를 크롤링했는데 아래와 같이 사진, 영화 이름, 영화 링크 세 부분이 있습니다.
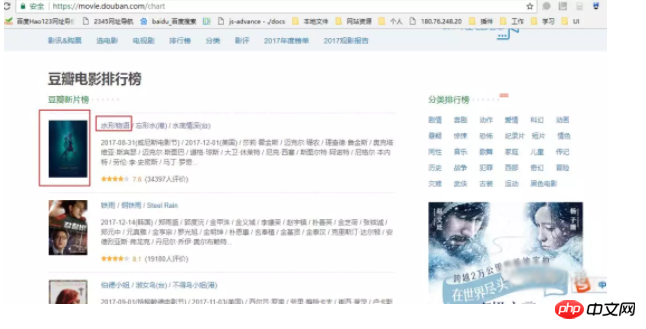

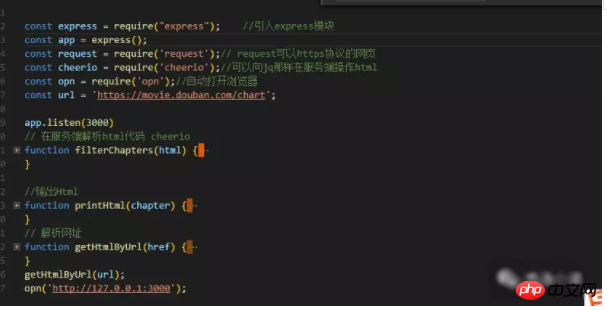
요청을 사용하여 크롤링한 데이터를 처리하는 방법은 무엇입니까? Cherio 패키지를 사용하면 Jq와 같이 크롤링된 HTML 데이터를 처리할 수 있습니다.
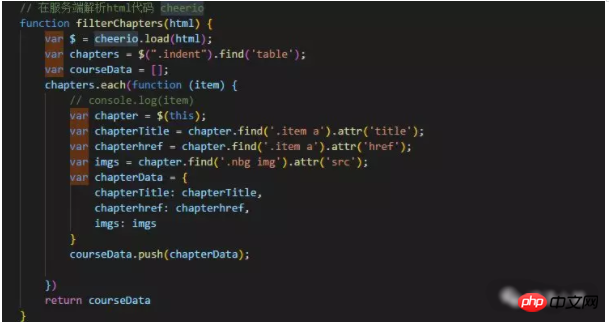
①. 먼저 데이터를 구문 분석하고 크롤링된 웹 페이지의 html 데이터를 가져옵니다. 그런 다음 Cherio 패키지를 사용하여 원하는 데이터를 가져옵니다.
 3. 데이터를 가져와서 HTML을 생성하고 페이지에 출력합니다. 아래 사진처럼 제가 사용한 스트링 스플라이싱 방법은 좀 바보같기도 하고, 아직 더 나은 방법을 찾지 못했습니다.
3. 데이터를 가져와서 HTML을 생성하고 페이지에 출력합니다. 아래 사진처럼 제가 사용한 스트링 스플라이싱 방법은 좀 바보같기도 하고, 아직 더 나은 방법을 찾지 못했습니다.
브라우저와 vue-cli에서 사용하는 opn 패키지를 자동으로 열 수 있도록 vue-cli의 webpack 구성을 살펴보셨는지 궁금합니다.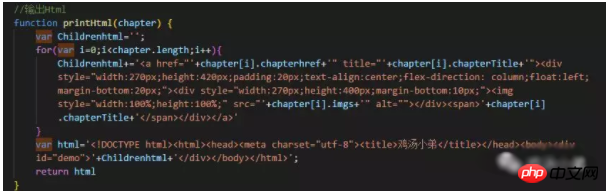
이 패키지는 사용하기 매우 편리합니다.
5. 디스플레이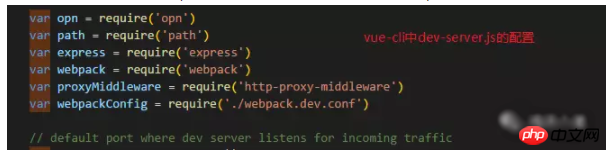
Tmall 크롤링 방법 PHP
를 사용한 Taobao 제품 데이터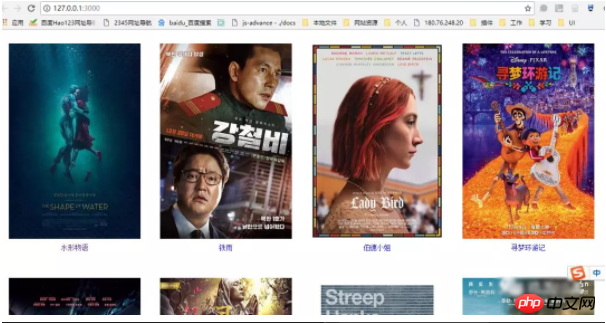
5개의 이미지 크롤링 추천 코스
를 구현합니다.위 내용은 Node.js가 Douban 데이터를 크롤링하는 방법에 대한 공유 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!