



이 글은 주로 React의 기원과 발전을 여러분과 공유합니다. 여러분에게 도움이 되기를 바랍니다.
캐릭터 스플라이싱 시대 - 2004
2004년에도 Mark Zuckerberg는 기숙사에서 여전히 Facebook 원본 버전을 작업하고 있었습니다.
올해는 모두가 PHP의 문자열 연결 기능을 사용하여 웹사이트를 개발하고 있습니다.
$str = '
- ';
foreach ($talks as $talk) {
$str += '
- ' . $talk->name . ' '; } $str += '
당시에는 이 웹 사이트 개발 방법이 매우 정확해 보였습니다. 백엔드 개발이든 프런트 엔드 개발이든, 개발 경험이 전혀 없어도 이 방법을 사용하면 대규모 웹 사이트를 구축할 수 있기 때문입니다.
유일한 단점은 이 개발 방법이 XSS 주입 및 기타 보안 문제를 쉽게 일으킬 수 있다는 것입니다. $talk->name에 악성 코드가 포함되어 있고 보호 조치가 취해지지 않은 경우 공격자가 임의의 JS 코드를 삽입할 수 있습니다. 이로 인해 "사용자 입력을 절대 신뢰하지 않음"이라는 보안 규칙이 탄생했습니다.
이 문제를 해결하는 가장 쉬운 방법은 사용자의 입력을 escape(Escape)하는 것입니다. 그러나 이는 다른 문제도 발생합니다. 문자열이 여러 번 이스케이프되는 경우 이스케이프 방지 횟수도 동일해야 합니다. 그렇지 않으면 원래 내용을 얻을 수 없습니다. 실수로 HTML 태그(마크업)를 이스케이프하면 HTML 태그가 사용자에게 직접 표시되어 사용자 경험이 저하됩니다.
XHP Era - 2010
2010년, 보다 효율적으로 코딩하고 HTML 태그 이스케이프 오류를 방지하기 위해 Facebook은 XHP를 개발했습니다. XHP는 개발자가 문자열을 사용하는 대신 PHP에서 직접 HTML 태그를 사용할 수 있도록 하는 PHP의 구문 확장입니다.
$content =
이 경우 모든 HTML 태그는 PHP와 다른 구문을 사용하므로 이스케이프해야 할 것과 그렇지 않은 것을 쉽게 구분할 수 있습니다.
곧 Facebook 엔지니어들은 맞춤 라벨을 만들 수도 있고 맞춤 라벨을 결합하면 대규모 애플리케이션을 구축하는 데 도움이 될 수 있다는 사실을 발견했습니다.
그리고 이것이 바로 Semantic Web과 Web Components의 개념을 구현하는 한 가지 방법입니다.
$content = <list></list>;
foreach ($talks as $talk) {
$content->appendChild(<talk></talk>);
}
이후 Facebook은 클라이언트와 서버 간의 지연을 줄이기 위해 JS에서 더 새로운 기술적 방법을 시도했습니다. 크로스 브라우저 DOM 라이브러리와 데이터 바인딩 등이 있지만 이상적이지는 않습니다.
JSX - 2013
2013년까지 기다렸다가 어느 날 갑자기 프런트 엔드 엔지니어 Jordan Walke가 그의 관리자에게 대담한 아이디어를 제안했습니다. XHP의 확장 기능을 JS로 마이그레이션하는 것입니다. 처음에는 모두가 당시 모두가 낙관했던 JS 프레임워크와 호환되지 않았기 때문에 그가 미쳤다고 생각했습니다. 그러나 그는 결국 그의 관리자를 설득하여 아이디어를 테스트할 수 있는 6개월의 시간을 주었습니다. 여기서 페이스북의 훌륭한 엔지니어링 경영 철학은 훌륭하고 배울 가치가 있다는 점을 말씀드리고 싶습니다.
첨부 파일: Lee Byron이 말하는 Facebook 엔지니어 문화: 도구에 투자하는 이유
XHP의 확장 기능을 JS로 마이그레이션하려면 먼저 JS가 XML 구문을 지원할 수 있도록 하는 확장이 필요합니다. 이 확장을 JSX라고 합니다. 그 당시 Node.js의 등장과 함께 Facebook 내에서는 JS 변환을 위한 상당한 엔지니어링 관행이 이미 있었습니다. 그래서 JSX를 구현하는 것은 매우 쉬웠고 일주일 정도밖에 걸리지 않았습니다.
const content = (
<talklist>
{ talks.map(talk => <talk></talk>)}
</talklist>
);
React
이후 React의 대장정은 시작되었고, 아직 더 큰 어려움은 다가오지 않습니다. 그 중 가장 까다로운 것은 PHP에서 업데이트 메커니즘을 재현하는 방법입니다.
PHP에서는 데이터가 변경될 때마다 PHP가 렌더링한 새 페이지로 이동하기만 하면 됩니다.
개발자의 관점에서 볼 때 이러한 방식으로 애플리케이션을 개발하는 것은 매우 간단합니다. 왜냐하면 변경에 대해 걱정할 필요가 없고 인터페이스의 사용자 데이터가 변경되면 모든 것이 동기화되기 때문입니다.
데이터 변경이 있는 한 전체 페이지가 다시 렌더링됩니다.
간단하고 투박하지만 이 방법의 단점도 특히 두드러집니다. 즉, 매우 느립니다.
"좋기 전에 옳아야 한다"는 것은 마이그레이션 계획의 타당성을 검증하기 위해 개발자가 당분간 성능 문제에 관계없이 사용 가능한 버전을 신속하게 구현해야 함을 의미합니다.
DOM
PHP에서 영감을 받아 JS에서 다시 렌더링을 구현하는 가장 간단한 방법은 콘텐츠가 변경되면 전체 DOM을 재구축한 다음 이전 DOM을 새 DOM으로 바꾸는 것입니다.

이 방법은 효과가 있지만 일부 시나리오에서는 적합하지 않습니다.
예를 들어 현재 포커스가 있는 요소와 커서는 물론 페이지의 현재 상태인 텍스트 선택 및 페이지 스크롤 위치도 손실됩니다.
즉, DOM 노드에는 상태가 포함됩니다.

상태가 포함되어 있으므로 이전 DOM의 상태를 기록하고 새 DOM에 복원하는 것만으로도 충분하지 않을까요?
그러나 안타깝게도 이 방법은 구현하기가 복잡할 뿐만 아니라 모든 상황을 다룰 수는 없습니다.
OSX 컴퓨터에서 페이지를 스크롤할 때 일정량의 스크롤 관성이 발생합니다. 그러나 JS는 스크롤 관성을 읽거나 쓰기 위한 해당 API를 제공하지 않습니다. iframe이 포함된 페이지의 경우 상황이 더 복잡합니다. 다른 도메인에서 가져온 경우 브라우저 보안 정책 제한으로 인해 해당 콘텐츠를 복원하는 것은 물론이고 내부 콘텐츠를 전혀 볼 수 없습니다. iframe 的页面来说,情况则更复杂。如果它来自其他域,那么浏览器安全策略限制根本不会允许我们查看其内部的内容,更不用说还原了。
因此可以看出,DOM 不仅仅有状态,它还包含隐藏的、无法触达的状态。
既然还原状态行不通,那就换一种方式绕过去。
对于没有改变的 DOM 节点,让它保持原样不动,仅仅创建并替换变更过的 DOM 节点。
这种方式实现了 DOM 节点复用(Reuse)。
至此,只要能够识别出哪些节点改变了,那么就可以实现对 DOM 的更新。于是问题就转化为如何比对两个 DOM 的差异。
Diff
说到对比差异,相信大家马上就能联想到版本控制(Version Control)。它的原理很简单,记录多个代码快照,然后使用 diff 算法比对前后两个快照,从而生成一系列诸如“删除 5 行”、“新增 3 行”、“替换单词”等的改动;通过把这一系列的改动应用到先前的代码快照就可以得到之后的代码快照。
而这正是 React 所需要的,只不过它的处理对象是 DOM 而不是文本文件。
难怪有人说:“I tend to think of React as Version Control for the DOM” 。
DOM 是树形结构,所以 diff 算法必须是针对树形结构的。目前已知的完整树形结构 diff 算法复杂度为 O(n^3) 。
假如页面中有 10,000 个 DOM 节点,这个数字看起来很庞大,但其实并不是不可想象。为了计算该复杂度的数量级大小,我们还假设在一个 CPU 周期我们可以完成单次对比操作(虽然不可能完成),且 CPU 主频为 1 GHz 。这种情况下,diff 要花费的时间如下:

整整有 17 分钟之长,简直无法想象!
虽然说验证阶段暂不考虑性能问题,但是我们还是可以简单了解下该算法是如何实现的。
附:完整的 Tree diff 实现算法。

新树上的每个节点与旧树上的每个节点对比
如果父节点相同,继续循环对比子树
在上图的树中,依据最小操作原则,可以找到三个嵌套的循环对比。
但如果认真思考下,其实在 Web 应用中,很少有移动一个元素到另一个地方的场景。一个例子可能的是拖拽(Drag)并放置(Drop)元素到另一个地方,但它并不常见。
唯一的常用场景是在子元素之间移动元素,例如在列表中新增、删除和移动元素。既然如此,那可以仅仅对比同层级的节点。
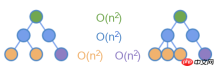
如上图所示,仅对相同颜色的节点做 diff ,这样能把时间复杂度降到了 O(n^2) 。
key

针对同级元素的比较,又引入了另一个问题。
同层级元素名称不同时,可以直接识别为不匹配;相同时,却没那么简单了。
假如在某个节点下,上一次渲染了三个 <input>,然后下一次渲染变成了两个。此时 diff 的结果会是什么呢?
最直观的结果是前面两个保持不变,删除第三个。
当然,也可以删除第一个同时保持最后两个。
如果不嫌麻烦,还可以把旧的三个都删除,然后新增两个新元素。
这说明,对于相同标签名称的节点,我们没有足够信息来对比前后差异。

如果再加上元素的属性呢?比如 value ,如果前后两次标签名称和 value따라서 DOM에는 상태가 있을 뿐만 아니라 숨겨지고 도달할 수 없는 상태도 포함되어 있음을 알 수 있습니다.
Diff
🎜비교 차이점이라고 하면 누구나 바로 Version Control(버전 관리)을 떠올릴 수 있을 거라 믿습니다. 그 원리는 매우 간단합니다. 여러 코드 스냅샷을 기록한 다음 diff 알고리즘을 사용하여 두 스냅샷을 비교하여 "5줄 삭제", "3줄 추가", "단어 교체" 등과 같은 일련의 변경 사항을 생성합니다. 이 일련의 변경 사항을 이전 코드 스냅샷에 적용하여 후속 코드 스냅샷을 얻습니다. 🎜🎜텍스트 파일 대신 DOM을 처리한다는 점을 제외하면 이것이 바로 React에 필요한 것입니다. 🎜누군가가 "나는 React를 DOM의 버전 제어로 생각하는 경향이 있습니다"라고 말한 것도 당연합니다. 🎜🎜DOM은 트리 구조이므로 diff 알고리즘은 트리 구조를 기반으로 해야 합니다. 현재 알려진 완전한 트리 구조 diff 알고리즘의 복잡성은 O(n^3)입니다. 🎜🎜페이지에 10,000개의 DOM 노드가 있다면 이 숫자는 엄청나 보이지만 상상할 수 없는 수치는 아닙니다. 이 복잡성의 규모를 계산하기 위해 우리는 한 CPU 사이클에서 단일 비교 작업을 완료할 수 있고(불가능하지만) CPU 클럭이 1GHz로 클럭된다고 가정합니다. 이 경우 diff에 소요된 시간은 다음과 같습니다. 🎜🎜 🎜🎜17분 길이로 상상할 수 없을 정도입니다! 🎜🎜검증 단계에서는 당분간 성능 문제를 고려하지 않지만, 알고리즘이 어떻게 구현되는지 간략하게 이해할 수 있습니다. 🎜
🎜🎜17분 길이로 상상할 수 없을 정도입니다! 🎜🎜검증 단계에서는 당분간 성능 문제를 고려하지 않지만, 알고리즘이 어떻게 구현되는지 간략하게 이해할 수 있습니다. 🎜첨부: 완전한 Tree diff 구현 알고리즘.🎜
span>🎜- 🎜새 트리의 각 노드를 이전 트리의 각 노드와 비교🎜
- 🎜부모 노드가 동일한 경우, 계속 루프 비교 하위 트리🎜
🎜 🎜위 그림과 같이 동일한 색상의 노드만 비교하면 시간 복잡도를 O(n^2)로 줄일 수 있습니다. 🎜키
🎜 🎜🎜동일 레벨 요소 비교에 또 다른 문제가 발생했습니다. 🎜동일한 레벨의 요소 이름이 다른 경우, 동일한 경우에는 불일치로 직접 식별할 수 있지만 그렇게 간단하지는 않습니다. 🎜특정 노드에서 지난번에
🎜🎜동일 레벨 요소 비교에 또 다른 문제가 발생했습니다. 🎜동일한 레벨의 요소 이름이 다른 경우, 동일한 경우에는 불일치로 직접 식별할 수 있지만 그렇게 간단하지는 않습니다. 🎜특정 노드에서 지난번에 <input> 3개가 렌더링되었고, 다음번에는 2개가 렌더링되었다고 가정해 보겠습니다. 이때 diff의 결과는 어떻게 될까요? 🎜🎜가장 직관적인 결과는 처음 두 개는 변경하지 않고 세 번째는 삭제하는 것입니다. 🎜물론 마지막 두 개를 유지하면서 첫 번째 것을 삭제할 수도 있습니다. 🎜문제가 있어도 괜찮다면 이전 항목 3개를 모두 삭제하고 새 요소 2개를 추가할 수 있습니다. 🎜이는 동일한 라벨 이름을 가진 노드의 경우 전후의 차이점을 비교할 수 있는 정보가 충분하지 않음을 나타냅니다. 🎜🎜🎜 🎜요소의 속성을 추가하면 어떻게 되나요? 예를 들어 값의 경우 태그 이름과 값 속성이 전후에 두 번 동일하면 요소가 일치하는 것으로 간주되므로 변경할 필요가 없습니다. 그러나 현실은 이것이 작동하지 않는다는 것입니다. 사용자가 입력할 때 값이 항상 변경되어 요소가 항상 대체되어 포커스를 잃게 되기 때문입니다. 더 나쁜 것은 모든 HTML 요소에 이 속성이 있는 것은 아닙니다. . 🎜
那使用所有元素都有的 id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input 设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key 属性的原因。

结合 key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。
附:详细的 diff 理解:不可思议的 react diff 。
持续优化
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 p,其实例属性就达到 231 个。
// Chrome v63
const p = document.createElement('p');
let m = 0;
for (let k in p) {
m++;
}
console.log(m); // 231
之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。

其过程如下:
维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。
接下来要说的两大优化就是来自于开源社区。
批处理(Batching)
著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。
我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。
当 DOM 被修改后,浏览器必须更新元素的位置和真实像素;
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
与此同时,常规的 JS 写法又很容易触发重排和重绘。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。
결국 커뮤니티 기고자 Ben Alpert는 일괄 처리를 사용하여 이 당황스러운 상황을 해결했습니다.
React에서 개발자는 구성 요소의 setState 메서드를 호출하여 현재 구성 요소가 변경될 것이라고 React에게 알립니다. setState 方法告诉 React 当前组件要变更了。

Ben Alpert 的做法是,调用 setState 时不立即把变更同步到 Virtual DOM,而是仅仅把对应元素打上“待更新”的标记。如果组件内调用多次 setState ,那么都会进行相同的打标操作。
等到初始化事件被完全广播开以后,就开始进行从顶部到底部的重新渲染(Re-Render)过程。这就确保了 React 只对元素进行了一次渲染。
这里要注意两点:
此处的重新渲染是指把
setState变更同步到 Virtual DOM ;在这之后才进行 diff 操作生成真实的 DOM 变更。与前文提到的“重新渲染整个 DOM ”不同的是,真实的重新渲染仅渲染被标记的元素及其子元素,也就是说上图中仅蓝色圆圈代表的元素会被重新渲染
这也提醒开发者,应该让拥有状态的组件尽量靠近叶子节点,这样可以缩小重新渲染的范围。
裁剪(Pruning)
随着应用越来越大,React 管理的组件状态也会越来越多,这就意味着重新渲染的范围也会越来越大。
认真观察上面批处理的过程可以发现,该 Virtual DOM 右下角的三个元素其实是没有变更的,但是因为其父节点的变更也导致了它们的重新渲染,多做了无用操作。

对于这种情况,React 本身已经考虑到了,为此它提供了 bool shouldComponentUpdate(nextProps, nextState) 接口。开发者可以手动实现该接口来对比前后状态和属性,以判断是否需要重新渲染。这样的话,重新渲染就变成如下图所示过程。

当时,React 虽然提供了 shouldComponentUpdate 接口,但是并没有提供一个默认的实现方案(总是渲染),开发者必须自己手动实现才能达到预期效果。
其原因是,在 JS 中,我们通常使用对象来保存状态,修改状态时是直接修改该状态对象的。也就是说,修改前后的两个不同状态指向了同一个对象,所以当直接比较两个对象是否变更时,它们是相同的,即使状态已经改变。
对此,David Nolen 提出了基于不可变数据结构(Immutable Data Structure)的解决方案。
该方案的灵感来自于 ClojureScript ,在 ClojureScript 中,大部分的值都是不可变的。换句话说就是,当需要更新一个值时,程序不是去修改原来的值,而是基于原来的值创建一个新值,然后使用新值进行赋值。
David 使用 ClojureScript 写了一个针对 React 的不可变数据结构方案:Om ,为 shouldComponentUpdate 提供了默认实现。
不过,由于不可变数据结构并未被 Web 工程师广为接受,所以当时并未把这项功能合并进 React 。
遗憾的是,截止到目前,shouldComponentUpdate
Ben Alpert의 접근 방식은 setState를 호출할 때 Virtual DOM에 대한 변경 사항을 즉시 동기화하는 것이 아니라 해당 요소를 "업데이트 예정"으로 표시하는 것뿐입니다. 구성 요소에서 setState가 여러 번 호출되면 동일한 표시 작업이 수행됩니다.
초기화 이벤트가 완전히 방송될 때까지 기다린 다음 위에서 아래로 다시 렌더링 프로세스를 시작합니다. 이렇게 하면 React가 요소를 한 번만 렌더링할 수 있습니다.
여기서 주목해야 할 두 가지 사항:
- 여기서 다시 렌더링하는 것은
setState변경 사항을 가상 DOM에 동기화하는 것을 의미합니다. 실제 DOM 변경 사항을 생성하는 diff 작업. -
위에서 언급한 "전체 DOM을 다시 렌더링하는 것"과 달리 실제 다시 렌더링은 표시된 요소와 그 하위 요소만 렌더링하므로 위 그림의 파란색 원만 나타냅니다. 요소가 다시 렌더링됩니다
이는 또한 개발자에게 상태 저장 구성 요소를 리프 노드에 최대한 가깝게 유지해야 하며, 이는 다시 렌더링 범위를 줄일 수 있음을 상기시킵니다.
가지치기
애플리케이션이 커질수록 React는 점점 더 많은 구성요소 상태를 관리하며, 이는 다시 렌더링의 범위도 점점 더 커진다는 것을 의미합니다. 위의 일괄 처리 프로세스를 주의 깊게 관찰하면 Virtual DOM의 오른쪽 하단에 있는 세 가지 요소가 실제로 변경되지 않았음을 알 수 있습니다. 그러나 해당 상위 노드의 변경으로 인해 다시 렌더링되기도 합니다. 불필요한 추가 작업이 발생합니다.
React 자체는 이미 이러한 상황을 고려했으며 이러한 목적을 위해 bool shouldComponentUpdate(nextProps, nextState) 인터페이스를 제공합니다. 개발자는 이 인터페이스를 수동으로 구현하여 이전과 이후의 상태 및 속성을 비교하여 다시 렌더링이 필요한지 여부를 결정할 수 있습니다. 이 경우 re-rendering은 아래 그림과 같은 과정이 됩니다.
shouldComponentUpdate 인터페이스를 제공했지만 기본 구현 솔루션(항상 렌더링)을 제공하지 않았고 개발자가 원하는 효과를 얻으려면 수동으로 구현해야 했습니다. 🎜🎜이유는 JS에서는 주로 상태를 저장하기 위해 객체를 사용하는데, 상태를 수정할 때에는 상태 객체를 직접 수정하기 때문입니다. 즉, 수정 전과 수정 후의 서로 다른 두 상태는 동일한 객체를 가리키므로, 두 객체의 변경 여부를 직접 비교하면 상태가 변경되더라도 동일합니다. 🎜🎜이에 대해 David Nolen은 Immutable Data Structure를 기반으로 한 솔루션을 제안했습니다. 🎜이 솔루션은 대부분의 값이 변경되지 않는 ClojureScript에서 영감을 받았습니다. 즉, 값을 업데이트해야 할 때 프로그램은 원래 값을 수정하지 않고 원래 값을 기반으로 새 값을 생성한 다음 새 값을 할당에 사용합니다. 🎜🎜David는 ClojureScript를 사용하여 shouldComponentUpdate에 대한 기본 구현을 제공하는 React: Om에 대한 불변 데이터 구조 솔루션을 작성했습니다. 🎜🎜그러나 불변 데이터 구조는 웹 엔지니어들에게 널리 받아들여지지 않았기 때문에 당시에는 이 기능이 React에 통합되지 않았습니다. 🎜안타깝게도 현재 shouldComponentUpdate는 여전히 기본 구현을 제공하지 않습니다. 🎜하지만 David는 개발자를 위한 좋은 연구 방향을 열어주었습니다. 🎜🎜정말 불변 데이터 구조를 사용하여 React 성능을 향상시키고 싶다면 React와 같은 학교 출신인 Facebook Immutable.js를 참고하세요. React의 좋은 파트너입니다! 🎜🎜결론🎜🎜React의 최적화는 여전히 계속되고 있습니다. 예를 들어 Fiber는 React 16에서 새로 도입되었습니다. 즉, 변경 사항을 감지하는 방법과 타이밍을 재설계하여 렌더링 프로세스를 허용합니다. 부분별로 완료해야 하며 한꺼번에 완료할 필요는 없습니다. 🎜공간의 제약으로 인해 이 글에서는 Fiber를 심도 있게 소개하지 않습니다. 관심 있는 분들은 React Fiber가 무엇인지 참고하시기 바랍니다. 🎜🎜관련 권장 사항: 🎜🎜🎜🎜React 구성 요소 수명 주기에 대한 자세한 설명🎜🎜🎜🎜react에서 제어되는 구성 요소와 제어되지 않는 구성 요소에 대한 자세한 설명🎜🎜🎜🎜react를 사용하여 페이징 구성 요소를 작성하는 예🎜🎜🎜🎜🎜위 내용은 React에 대한 간략한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 JavaScript 및 웹 : 핵심 기능 및 사용 사례Apr 18, 2025 am 12:19 AM
JavaScript 및 웹 : 핵심 기능 및 사용 사례Apr 18, 2025 am 12:19 AM웹 개발에서 JavaScript의 주요 용도에는 클라이언트 상호 작용, 양식 검증 및 비동기 통신이 포함됩니다. 1) DOM 운영을 통한 동적 컨텐츠 업데이트 및 사용자 상호 작용; 2) 사용자가 사용자 경험을 향상시키기 위해 데이터를 제출하기 전에 클라이언트 확인이 수행됩니다. 3) 서버와의 진실한 통신은 Ajax 기술을 통해 달성됩니다.
 JavaScript 엔진 이해 : 구현 세부 사항Apr 17, 2025 am 12:05 AM
JavaScript 엔진 이해 : 구현 세부 사항Apr 17, 2025 am 12:05 AM보다 효율적인 코드를 작성하고 성능 병목 현상 및 최적화 전략을 이해하는 데 도움이되기 때문에 JavaScript 엔진이 내부적으로 작동하는 방식을 이해하는 것은 개발자에게 중요합니다. 1) 엔진의 워크 플로에는 구문 분석, 컴파일 및 실행; 2) 실행 프로세스 중에 엔진은 인라인 캐시 및 숨겨진 클래스와 같은 동적 최적화를 수행합니다. 3) 모범 사례에는 글로벌 변수를 피하고 루프 최적화, Const 및 Lets 사용 및 과도한 폐쇄 사용을 피하는 것이 포함됩니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성Apr 16, 2025 am 12:12 AMPython은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스Apr 15, 2025 am 12:16 AMPython과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 C/C에서 JavaScript까지 : 모든 것이 어떻게 작동하는지Apr 14, 2025 am 12:05 AM
C/C에서 JavaScript까지 : 모든 것이 어떻게 작동하는지Apr 14, 2025 am 12:05 AMC/C에서 JavaScript로 전환하려면 동적 타이핑, 쓰레기 수집 및 비동기 프로그래밍으로 적응해야합니다. 1) C/C는 수동 메모리 관리가 필요한 정적으로 입력 한 언어이며 JavaScript는 동적으로 입력하고 쓰레기 수집이 자동으로 처리됩니다. 2) C/C를 기계 코드로 컴파일 해야하는 반면 JavaScript는 해석 된 언어입니다. 3) JavaScript는 폐쇄, 프로토 타입 체인 및 약속과 같은 개념을 소개하여 유연성과 비동기 프로그래밍 기능을 향상시킵니다.
 JavaScript 엔진 : 구현 비교Apr 13, 2025 am 12:05 AM
JavaScript 엔진 : 구현 비교Apr 13, 2025 am 12:05 AM각각의 엔진의 구현 원리 및 최적화 전략이 다르기 때문에 JavaScript 엔진은 JavaScript 코드를 구문 분석하고 실행할 때 다른 영향을 미칩니다. 1. 어휘 분석 : 소스 코드를 어휘 단위로 변환합니다. 2. 문법 분석 : 추상 구문 트리를 생성합니다. 3. 최적화 및 컴파일 : JIT 컴파일러를 통해 기계 코드를 생성합니다. 4. 실행 : 기계 코드를 실행하십시오. V8 엔진은 즉각적인 컴파일 및 숨겨진 클래스를 통해 최적화하여 Spidermonkey는 유형 추론 시스템을 사용하여 동일한 코드에서 성능이 다른 성능을 제공합니다.
 브라우저 너머 : 실제 세계의 JavaScriptApr 12, 2025 am 12:06 AM
브라우저 너머 : 실제 세계의 JavaScriptApr 12, 2025 am 12:06 AM실제 세계에서 JavaScript의 응용 프로그램에는 서버 측 프로그래밍, 모바일 애플리케이션 개발 및 사물 인터넷 제어가 포함됩니다. 1. 서버 측 프로그래밍은 Node.js를 통해 실현되며 동시 요청 처리에 적합합니다. 2. 모바일 애플리케이션 개발은 재교육을 통해 수행되며 크로스 플랫폼 배포를 지원합니다. 3. Johnny-Five 라이브러리를 통한 IoT 장치 제어에 사용되며 하드웨어 상호 작용에 적합합니다.
 Next.js (백엔드 통합)로 멀티 테넌트 SAAS 애플리케이션 구축Apr 11, 2025 am 08:23 AM
Next.js (백엔드 통합)로 멀티 테넌트 SAAS 애플리케이션 구축Apr 11, 2025 am 08:23 AM일상적인 기술 도구를 사용하여 기능적 다중 테넌트 SaaS 응용 프로그램 (Edtech 앱)을 구축했으며 동일한 작업을 수행 할 수 있습니다. 먼저, 다중 테넌트 SaaS 응용 프로그램은 무엇입니까? 멀티 테넌트 SAAS 응용 프로그램은 노래에서 여러 고객에게 서비스를 제공 할 수 있습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

드림위버 CS6
시각적 웹 개발 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

