
안주케 중고주택사이트 데이터 공유의 Python 크롤링 방법

- 小云云원래의
- 2018-01-09 13:20:283800검색
이 글은 주로 Anjuke 중고 주택 웹사이트 데이터를 크롤링하기 위한 Python 글을 제공합니다(예제 설명). 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리도록 하겠습니다. 편집자를 따라 살펴보겠습니다. 모두에게 도움이 되기를 바랍니다.
이제 본격적인 크롤러 작성을 시작하겠습니다. 먼저 크롤링할 웹사이트의 구조를 분석해야 합니다. 허난의 학생으로서 정저우의 중고 주택 정보를 살펴보겠습니다! 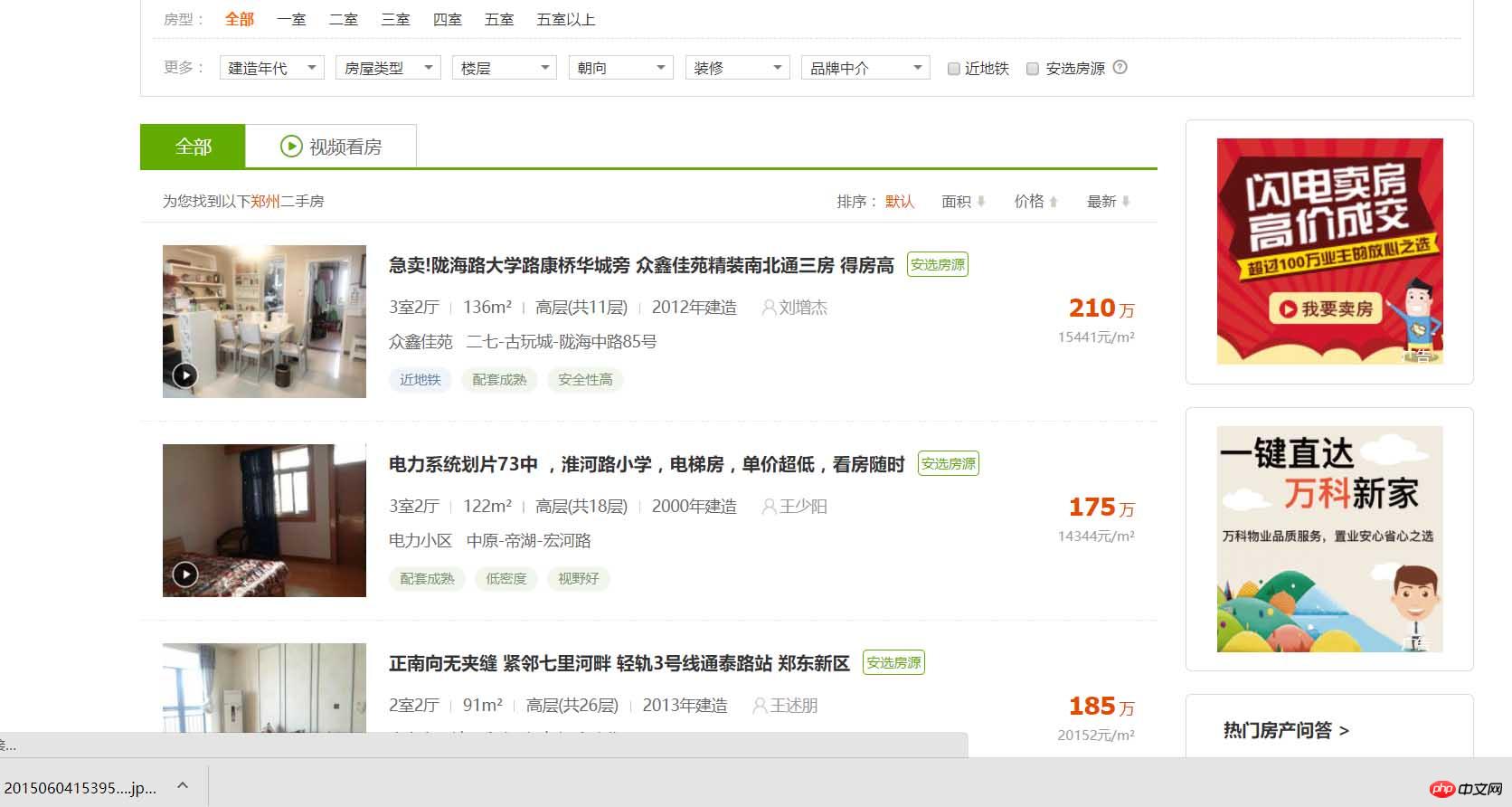
위 페이지에서 집 정보를 하나씩 볼 수 있습니다. 위에서 웹 페이지를 클릭하면 다음과 같은 내용을 볼 수 있습니다.
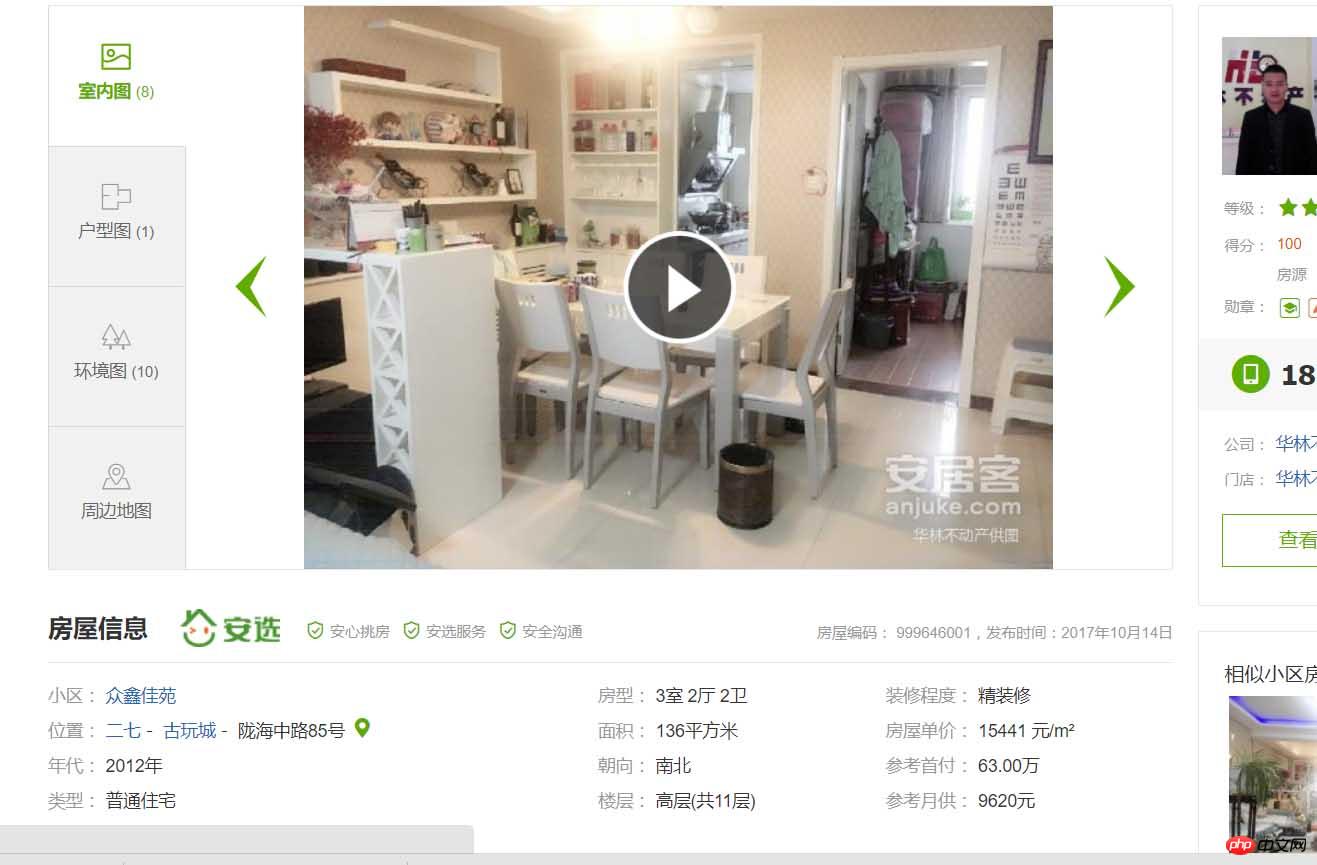
주택정보의 상세정보입니다. 좋아요! 그럼 우리가 할 일은 정저우의 모든 중고 주택 정보를 수집하여 데이터베이스에 저장하는 것입니다. 지리학자로서 아직까지는 다루지 않겠습니다. 자, 이제 공식적으로 시작하겠습니다. 먼저 python3.6의 요청 및 BeautifulSoup 모듈을 사용하여 페이지를 크롤링합니다. 먼저 요청 모듈이 요청을 수행합니다.
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)실행 후에는 이 웹사이트의 html 코드
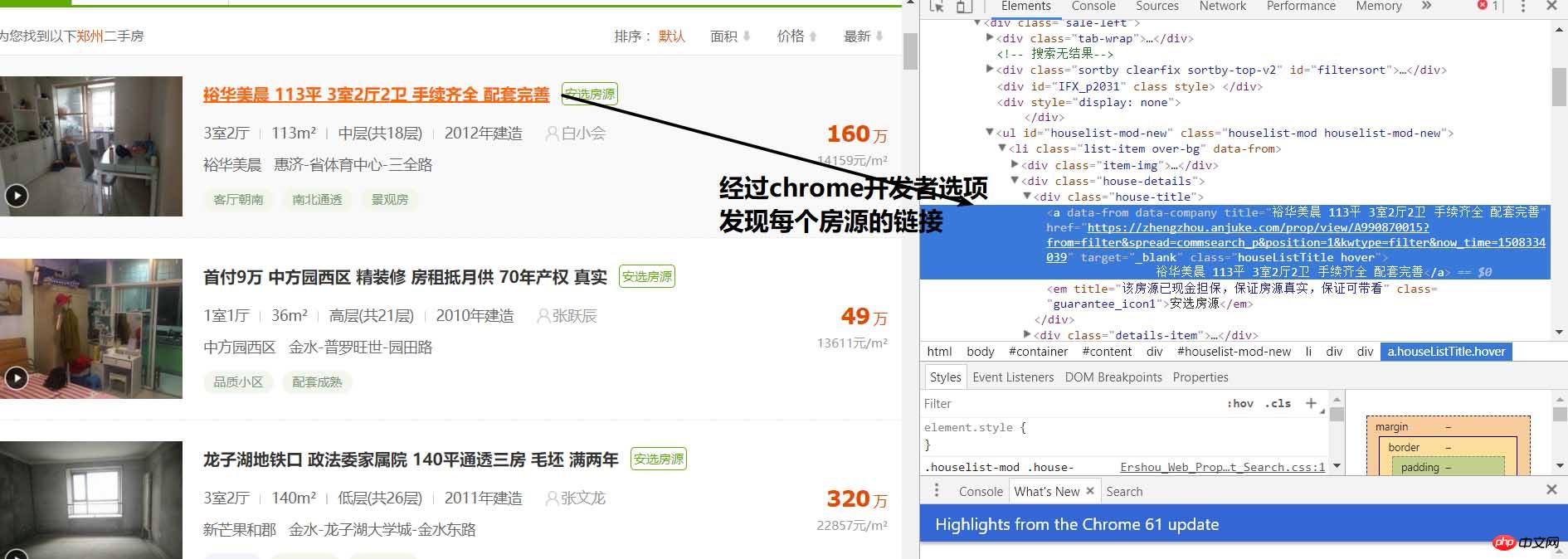
 분석을 통해 각 속성이 class="list-item"의 li 태그에 있음을 알 수 있으며 BeautifulSoup 패키지를 기반으로 추출할 수 있습니다
분석을 통해 각 속성이 class="list-item"의 li 태그에 있음을 알 수 있으며 BeautifulSoup 패키지를 기반으로 추출할 수 있습니다
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)금액 인쇄하면 코드를 더 줄일 수 있습니다. 좋습니다. 계속해서 추출하세요
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])이렇게 하면 URL을 하나씩 볼 수 있습니다. 별로 마음에 들지 않나요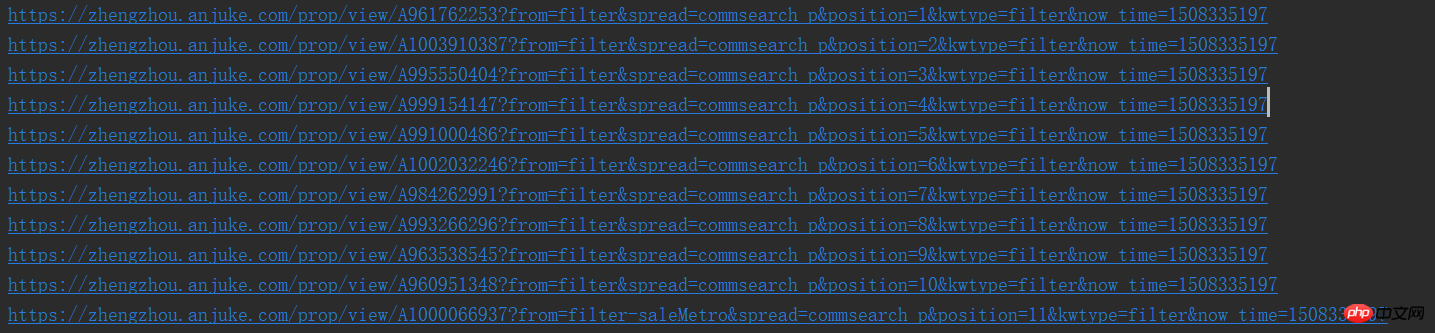
좋아요, 일반적인 방법으로는 로직상으로는 페이지에 들어가서 상세 페이지 분석을 시작해야 하는데, 크롤링 후에는 다음 페이지를 어떻게 크롤링해야 할까요? 그러면 먼저 해당 페이지에 다음 페이지가 있는지 분석해야 합니다
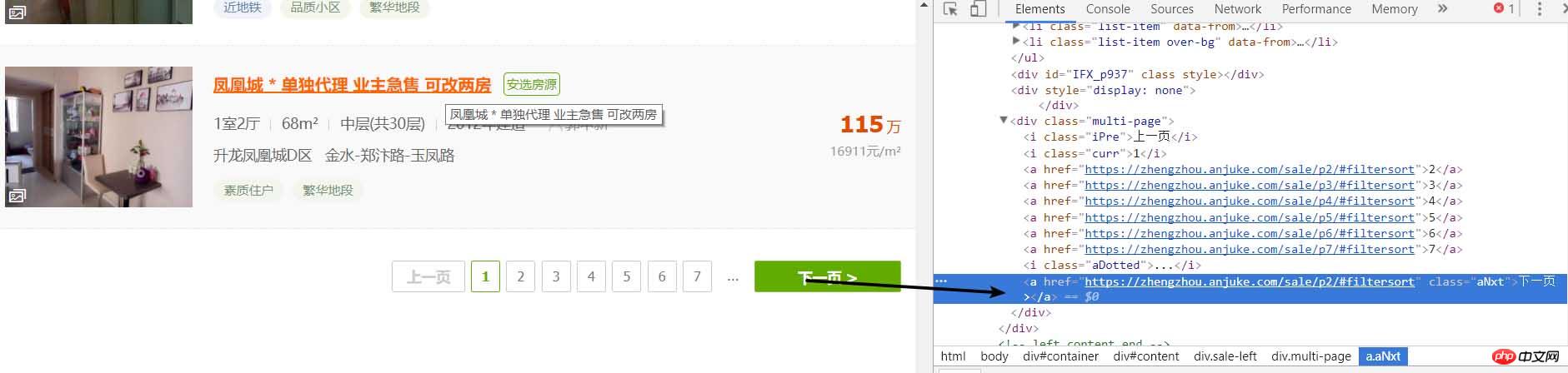
다음 페이지도 너무 간단하다는 것을 알 수 있습니다. 그러면 계속 누를 수 있습니다. 원래 레시피의 원래 맛이 계속됩니다
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')다음 페이지가 존재하면 웹 페이지에 태그가 있을 것이기 때문입니다. , i 태그가 되므로 이렇게 하면 됩니다. 따라서 이를 개선하고 위의 내용을 함수로 캡슐화할 수 있습니다
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)좋아, 그러면 세부 페이지 크롤링을 시작하겠습니다
야, 왜 힘이 있는 거지? 대학에 무슨 함정이 있겠습니까? 먼저 결과를 첨부합니다. 시간이 날 때 추가하겠습니다.
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)블로그를 하면서 코드를 작성했기 때문에 get_page 함수를 약간 변경했습니다. 즉, 다음 페이지에 대한 재귀 호출을 함수 뒤에 배치하고 캡슐화해야 합니다. 두 함수에 대한 소개가 없고
데이터가 mysql에 기록되지 않으므로 나중에 계속 추적하겠습니다. 감사합니다. you!!!
관련 권장 사항:
NetEase Cloud Music에서 인기 댓글을 크롤링하는 Python 방법 공유
위 내용은 안주케 중고주택사이트 데이터 공유의 Python 크롤링 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!