
async 및 enterproxy를 사용하여 동시성 수 제어

- 小云云원래의
- 2018-01-03 09:06:481553검색
동시성은 누구에게나 친숙한 개념이라고 생각합니다. 이 글에서는 비동기 및 EnterProxy를 사용하여 동시성 수를 제어하는 방법에 대한 관련 정보를 주로 샘플 코드를 통해 소개하며, 이는 모든 사람의 학습이나 업무에 참고가 될 것입니다. .밸류, 필요하신 친구들은 에디터를 따라가서 함께 배워보세요.
동시성과 병렬성에 대해 이야기합시다
운영 체제에서 동시성은 여러 프로그램이 시작과 실행 사이의 일정 기간에 있고 이러한 프로그램이 모두 동일한 프로세서에서 실행되지만 하나의 프로그램만 실행되는 것을 의미합니다. 언제든지 프로세서에서.
동시성은 우리가 자주 언급하는 것입니다. 웹 서버든 앱이든, 운영 체제에서 동시성은 시작과 실행 사이의 일정 기간 동안의 여러 프로그램을 의미하며 이러한 프로그램은 모두 동일한 프로세스가 프로세서에서 실행되며 언제든지 하나의 프로그램만 프로세서에서 실행됩니다. 많은 웹사이트에는 동시 연결 수에 제한이 있으므로 요청이 너무 빨리 전송되면 반환 값이 비어 있거나 오류가 보고됩니다. 또한 일부 웹사이트에서는 동시 연결을 너무 많이 보내고 악의적인 요청을 하고 있다고 생각하기 때문에 IP를 차단할 수도 있습니다.
동시성에 비해 병렬성은 많이 낯설 수 있습니다. 병렬성은 독립적이고 비동기적인 속도로 실행되는 프로그램 그룹을 말하며, 이는 여러 프로그램(작업)이 동시에 발생하는 것과 같지 않습니다. 동시에 수행되는 CPU 코어를 추가하여 구현됩니다. 맞습니다. 병렬화는 동시에 멀티 태스킹을 가능하게 합니다
enterproxy를 사용하여 동시성 수를 제어하세요
enterproxy는 Pu Lingda가 가장 많이 기여한 도구로, 이벤트 기반의 사고 방식에 변화를 가져왔습니다. 프로그래밍, 이벤트 메커니즘을 사용하여 복잡한 비즈니스 분리 로직은 콜백 기능 결합에 대한 비판을 해결하고 직렬 대기를 병렬 대기로 전환하며 다중 비동기 협업 시나리오에서 실행 효율성을 향상시킵니다.
enterproxy를 사용하여 비즈니스 수를 제어하는 방법 동시성? 일반적으로 Enterproxy 및 직접 만든 카운터를 사용하지 않으면 세 가지 소스를 가져옵니다.
이 깊이 중첩된 직렬 방식
var render = function (template, data) {
_.template(template, data);
};
$.get("template", function (template) {
// something
$.get("data", function (data) {
// something
$.get("l10n", function (l10n) {
// something
render(template, data, l10n);
});
});
});
과거의 깊은 중첩 방법을 제거하고 일반적인 작성 방법은 우리 고유의 카운터 유지
(function(){
var count = 0;
var result = {};
$.get('template',function(data){
result.data1 = data;
count++;
handle();
})
$.get('data',function(data){
result.data2 = data;
count++;
handle();
})
$.get('l10n',function(data){
result.data3 = data;
count++;
handle();
})
function handle(){
if(count === 3){
var html = fuck(result.data1,result.data2,result.data3);
render(html);
}
}
})();
여기서 enterproxy는 이러한 비동기 작업이 완료되었는지 관리하는 데 도움이 되며, 제공된 처리 기능을 자동으로 호출하고 캡처된 데이터를 매개변수로 사용합니다. 또한 다른 많은 시나리오에 필요한 API도 제공합니다. 이 API enterproxy를 직접 배울 수 있습니다.
비동기를 사용하여 동시성 수를 제어하세요
보내야 할 요청이 40개라면 많은 웹사이트가 실패할 수 있습니다. 동시에 발행된 연결이 너무 많아 악의적인 요청을 하면 IP가 차단됩니다.
비동기에서 mapLimit을 사용하여 동시성 수를 5개로 제어하고 한 번에 5개의 링크만 캡처합니다.
var ep = new enterproxy();
ep.all('data_event1','data_event2','data_event3',function(data1,data2,data3){
var html = fuck(data1,data2,data3);
render(html);
})
$.get('http:example1',function(data){
ep.emit('data_event1',data);
})
$.get('http:example2',function(data){
ep.emit('data_event2',data);
})
$.get('http:example3',function(data){
ep.emit('data_event3',data);
})
먼저 동시성이 무엇인지, 왜 동시성 수를 제한해야 하는지, 어떤 솔루션을 사용할 수 있는지 알아야 합니다. 그런 다음 설명서로 이동하여 API 사용 방법을 확인할 수 있습니다. 비동기 문서는 이러한 구문을 배울 수 있는 좋은 방법입니다.
여기에 반환된 데이터는 거짓이며 반환 지연은 무작위입니다.
async.mapLimit(arr, 5, function (url, callback) {
// something
}, function (error, result) {
console.log("result: ")
console.log(result);
})
그런 다음 async.mapLimit을 사용하여 동시에 크롤링하고 결과를 얻습니다.
var concurreyCount = 0;
var fetchUrl = function(url,callback){
// delay 的值在 2000 以内,是个随机的整数 模拟延时
var delay = parseInt((Math.random()* 10000000) % 2000,10);
concurreyCount++;
console.log('现在并发数是 ' , concurreyCount , ' 正在抓取的是' , url , ' 耗时' + delay + '毫秒');
setTimeout(function(){
concurreyCount--;
callback(null,url + ' html content');
},delay);
}
var urls = [];
for(var i = 0;i<30;i++){
urls.push('http://datasource_' + i)
}
시뮬레이션은 alsotang에서 발췌
output을 실행한 후 다음과 같은 결과를 얻었습니다
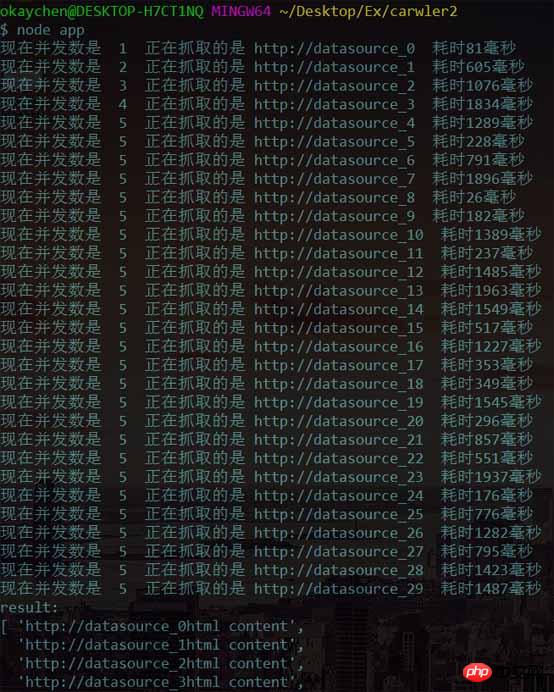 동시성 수가 1부터 증가하기 시작하다가 5까지 증가하면 더 이상 증가하지 않는 것을 발견했습니다. 작업이 있을 경우 크롤링을 계속하며, 동시 연결 수는 항상 5개로 제어됩니다.
동시성 수가 1부터 증가하기 시작하다가 5까지 증가하면 더 이상 증가하지 않는 것을 발견했습니다. 작업이 있을 경우 크롤링을 계속하며, 동시 연결 수는 항상 5개로 제어됩니다.
노드 단순 크롤러 시스템 완성
또탕의 "Node Teaching or Meeting" 튜토리얼 예제에서 사용한 eventproxy는 eventproxy를 사용하여 동시수를 제어하므로, 비동기를 사용하여 동시수를 제어하는 노드 단순 크롤러를 완성하겠습니다. .
크롤링 대상은 이 웹사이트의 홈페이지입니다(수동 얼굴 보호)
첫 번째 단계로 먼저 다음 모듈을 사용해야 합니다.
- url: URL 구문 분석에 사용되며 여기에서 url.resolve( ) 합법적인 도메인 이름
- async: 강력한 기능과 비동기 JavaScript 작업을 제공하는 실용적인 모듈
- cheerio: 서버용으로 특별히 맞춤화된 빠르고 유연하며 구현된 jQuery 코어 구현
- superagent : A nodejs의 매우 편리한 클라이언트 요청 프록시 모듈
- npm
을 통해 종속 모듈을 설치합니다. 두 번째 단계는 require를 통해 종속 모듈을 도입하고 크롤링 개체 URL을 결정하는 것입니다.
async.mapLimit(urls,5,function(url,callback){
fetchUrl(url,callbcak);
},function(err,result){
console.log('result: ');
console.log(result);
})
세 번째 단계: 사용 superagent를 사용하여 대상 URL을 요청하고, baseUrl을 처리하여 대상 콘텐츠 URL을 가져온 다음 이를 배열에 저장합니다.
var url = require("url");
var async = require("async");
var cheerio = require("cheerio");
var superagent = require("superagent");
var baseUrl = 'http://www.chenqaq.com';
캡처된 URL 개체를 확인하는 기능만 있으면 됩니다. arr을 탐색하여 인쇄하는 함수입니다. :
superagent.get(baseUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
var arr = [];
var $ = cheerio.load(res.text);
// 下面和jQuery操作是一样一样的..
$(".post-list .post-title-link").each(function (idx, element) {
$element = $(element);
var _url = url.resolve(baseUrl, $element.attr("href"));
arr.push(_url);
});
// 验证得到的所有文章链接集合
output(arr);
// 第四步:接下来遍历arr,解析每一个页面需要的信息
})
4단계: 획득한 URL 객체를 탐색하고 각 페이지에 필요한 정보를 구문 분석해야 합니다.
这里就需要用到async控制并发数量,如果你上一步获取了一个庞大的arr数组,有多个url需要请求,如果同时发出多个请求,一些网站就可能会把你的行为当做恶意请求而封掉你的ip
async.mapLimit(arr,3,function(url,callback){
superagent.get(url)
.end(function(err,mes){
if(err){
console.error(err);
console.log('message info ' + JSON.stringify(mes));
}
console.log('「fetch」' + url + ' successful!');
var $ = cheerio.load(mes.text);
var jsonData = {
title:$('.post-card-title').text().trim(),
href: url,
};
callback(null,jsonData);
},function(error,results){
console.log('results ');
console.log(results);
})
})
得到上一步保存url地址的数组arr,限制最大并发数量为3,然后用一个回调函数处理 「该回调函数比较特殊,在iteratee方法中一定要调用该回调函数,有三种方式」
callback(null) 调用成功
callback(null,data) 调用成功,并且返回数据data追加到results
callback(data) 调用失败,不会再继续循环,直接到最后的callback
好了,到这里我们的node简易的小爬虫就完成了,来看看效果吧
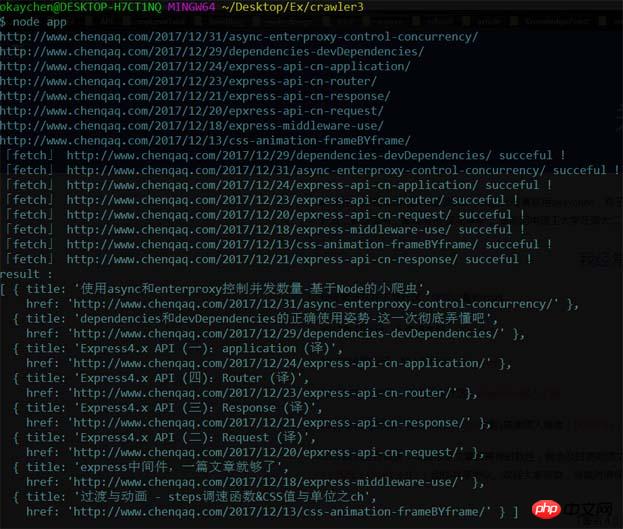
嗨呀,首页数据好少,但是成功了呢。
参考资料
Node.js 包教不包会 - alsotang
enterproxy
async
async Documentation
相关推荐:
위 내용은 async 및 enterproxy를 사용하여 동시성 수 제어의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!