
Python NLP에 대한 간략한 소개

- 小云云원래의
- 2017-12-26 09:16:242601검색
이 글에서는 Python NLP, Python 자연어 처리(NLP) 입문 튜토리얼과 Python의 NLTK 라이브러리 사용법을 주로 소개합니다. NLTK는 Python의 자연어 처리 툴킷으로 NLP 분야에서 가장 일반적으로 사용되는 Python 라이브러리입니다. 편집자님이 꽤 좋다고 하셔서 지금 공유하고 참고용으로 드리고 싶습니다. 편집자를 따라 살펴보겠습니다. 모두에게 도움이 되기를 바랍니다.
NLP란 무엇인가요?
간단히 말하면 자연어 처리(NLP)는 인간의 언어를 이해할 수 있는 애플리케이션이나 서비스의 개발입니다.
여기에서는 음성 인식, 음성 번역, 완전한 문장 이해, 일치하는 단어의 동의어 이해, 문법적으로 올바른 완전한 문장 및 단락 생성 등 자연어 처리(NLP)의 몇 가지 실제 적용 사례를 논의합니다.
이것이 NLP가 할 수 있는 전부는 아닙니다.
NLP 구현
검색 엔진: Google, Yahoo 등 Google 검색 엔진은 귀하가 기술 전문가임을 알고 있으므로 기술 관련 결과를 표시합니다.
소셜 웹사이트 푸시: Facebook 뉴스피드 등. 뉴스피드 알고리즘이 귀하의 관심사가 자연어 처리임을 인식하면 관련 광고와 게시물이 표시됩니다.
음성 엔진: Apple의 Siri 등.
스팸 필터링: Google 스팸 필터와 같습니다. 일반적인 스팸 필터링과 달리 이메일 내용의 더 깊은 의미를 이해하여 이메일이 스팸인지 여부를 판단합니다.
NLP 라이브러리
다음은 일부 오픈 소스 자연어 처리 라이브러리(NLP)입니다.
NLTK(자연어 도구 키트)
-
Apache OpenNLP 제품군;
-
Gate NLP library
그중 NLTK(자연어 처리 라이브러리)는 Python으로 작성되었으며 매우 강력한 커뮤니티 지원을 받고 있습니다.
NLTK는 시작하기도 쉽습니다. 실제로 가장 간단한 자연어 처리(NLP) 라이브러리입니다.
이 NLP 튜토리얼에서는 Python NLTK 라이브러리를 사용합니다.
NLTK 설치Windows/Linux/Mac을 사용하는 경우 pip를 사용하여 NLTK를 설치할 수 있습니다.
pip install nltkpython 터미널을 열고 NLTK를 가져와서 NLTK가 올바르게 설치되었는지 확인하세요.
import nltk모든 것이 순조롭게 진행된다면 NLTK 라이브러리가 성공적으로 설치되었음을 의미합니다. NLTK를 처음 설치한 후 다음 코드를 실행하여 NLTK 확장 패키지를 설치해야 합니다.
import nltk nltk.download()이렇게 하면 설치해야 할 패키지를 선택할 수 있는 NLTK 다운로드 창이 팝업됩니다.
모든 패키지를 그대로 설치할 수 있습니다. 크기가 작아서 문제가 없습니다.
먼저 웹 페이지 콘텐츠를 크롤링한 다음 텍스트를 분석하여 페이지 콘텐츠를 이해합니다. 우리는 웹 페이지를 크롤링하기 위해 urllib 모듈을 사용할 것입니다:
import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() print (html)인쇄된 결과에서 볼 수 있듯이 결과에는 정리해야 할 많은 HTML 태그가 포함되어 있습니다.
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") # 这需要安装html5lib模块 text = soup.get_text(strip=True) print (text)이제 크롤링된 웹 페이지에서 깨끗한 텍스트를 얻었습니다.
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() print (tokens)
Count 단어 빈도
텍스트가 처리되었으므로 이제 Python NLTK를 사용하여 토큰의 빈도 분포를 계산합니다. NLTK에서 FreqDist() 메서드를 호출하여 달성할 수 있습니다.
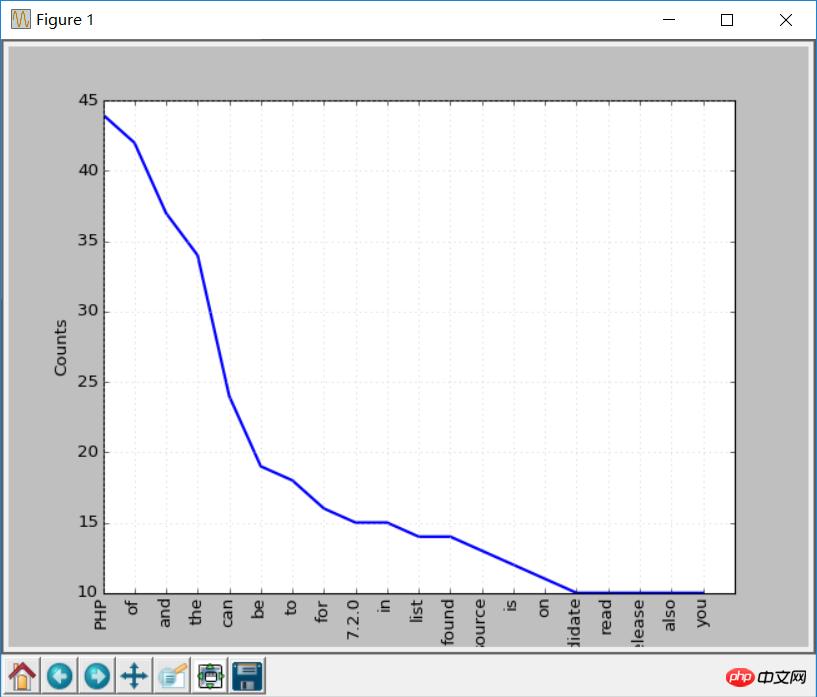
from bs4 import BeautifulSoup import urllib.request import nltk response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() freq = nltk.FreqDist(tokens) for key,val in freq.items(): print (str(key) + ':' + str(val))출력 결과를 검색하면 가장 일반적인 토큰이 PHP라는 것을 알 수 있습니다.
freq.plot(20, cumulative=False) # 需要安装matplotlib库
 일반적으로 불용어는 분석 결과에 영향을 미치지 않도록 제거해야 합니다.
일반적으로 불용어는 분석 결과에 영향을 미치지 않도록 제거해야 합니다.
NLTK에는 다양한 언어로 된 불용어 목록이 제공됩니다. 영어 불용어를 받으면:
from nltk.corpus import stopwords stopwords.words('english')이제 토큰을 그리기 전에 코드를 수정하고 잘못된 단어를 삭제하세요.
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token)최종 코드는 다음과 같아야 합니다.from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))이제 단어 빈도 차트를 다시 수행하면 중지 단어가 제거되었기 때문에 효과가 이전보다 더 좋아질 것입니다.
freq.plot(20,cumulative=False)
NLTK 텍스트 토큰화 사용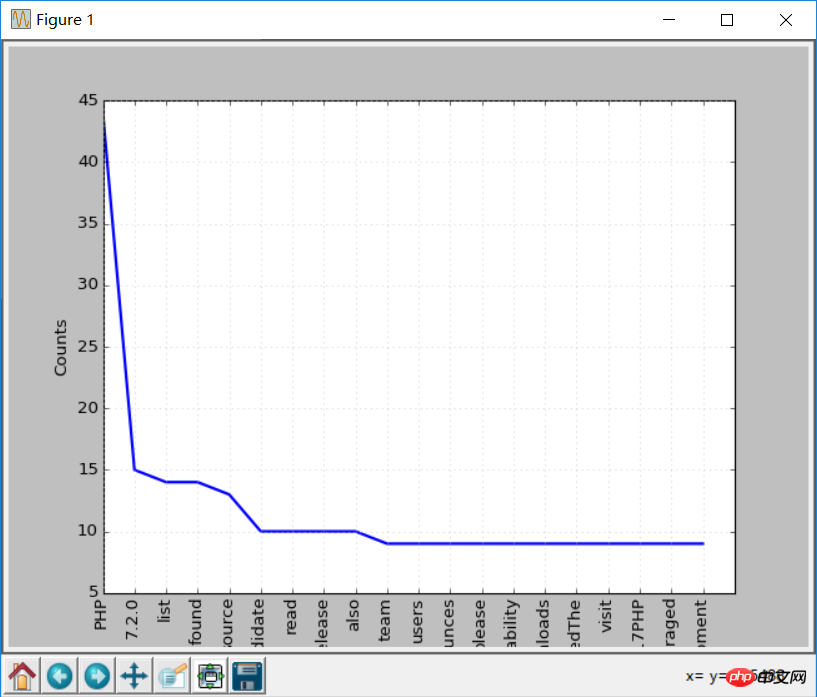
split 메서드를 사용하여 텍스트를 토큰으로 분할하기 전에는 이제 NLTK를 사용하여 텍스트를 토큰화합니다. 텍스트는 토큰화 없이는 처리할 수 없으므로 텍스트를 토큰화하는 것이 매우 중요합니다. 토큰화 과정은 큰 부분을 작은 부분으로 나누는 것을 의미합니다.
你可以将段落tokenize成句子,将句子tokenize成单个词,NLTK分别提供了句子tokenizer和单词tokenizer。
假如有这样这段文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
使用句子tokenizer将文本tokenize成句子:
from nltk.tokenize import sent_tokenize mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这是你可能会想,这也太简单了,不需要使用NLTK的tokenizer都可以,直接使用正则表达式来拆分句子就行,因为每个句子都有标点和空格。
那么再来看下面的文本:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
这样如果使用标点符号拆分,Hello Mr将会被认为是一个句子,如果使用NLTK:
from nltk.tokenize import sent_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这才是正确的拆分。
接下来试试单词tokenizer:
from nltk.tokenize import word_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(word_tokenize(mytext))
输出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
Mr.这个词也没有被分开。NLTK使用的是punkt模块的PunktSentenceTokenizer,它是NLTK.tokenize的一部分。而且这个tokenizer经过训练,可以适用于多种语言。
非英文Tokenize
Tokenize时可以指定语言:
from nltk.tokenize import sent_tokenize mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour." print(sent_tokenize(mytext,"french"))
输出结果如下:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]
同义词处理
使用nltk.download()安装界面,其中一个包是WordNet。
WordNet是一个为自然语言处理而建立的数据库。它包括一些同义词组和一些简短的定义。
您可以这样获取某个给定单词的定义和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())输出结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet包含了很多定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())结果如下:
the branch of information science that deals with natural language information
large Old World boas
可以像这样使用WordNet来获取同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)输出:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
反义词处理
也可以用同样的方法得到反义词:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)输出:
['large', 'big', 'big']
词干提取
语言形态学和信息检索里,词干提取是去除词缀得到词根的过程,例如working的词干为work。
搜索引擎在索引页面时就会使用这种技术,所以很多人为相同的单词写出不同的版本。
有很多种算法可以避免这种情况,最常见的是波特词干算法。NLTK有一个名为PorterStemmer的类,就是这个算法的实现:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('working')) print(stemmer.stem('worked'))
输出结果是:
work
work
还有其他的一些词干提取算法,比如 Lancaster词干算法。
非英文词干提取
除了英文之外,SnowballStemmer还支持13种语言。
支持的语言:
from nltk.stem import SnowballStemmer print(SnowballStemmer.languages) 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
你可以使用SnowballStemmer类的stem函数来提取像这样的非英文单词:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))单词变体还原
单词变体还原类似于词干,但不同的是,变体还原的结果是一个真实的单词。不同于词干,当你试图提取某些词时,它会产生类似的词:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('increases'))
结果:
increas
现在,如果用NLTK的WordNet来对同一个单词进行变体还原,才是正确的结果:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('increases'))
结果:
increase
结果可能会是一个同义词或同一个意思的不同单词。
有时候将一个单词做变体还原时,总是得到相同的词。
这是因为语言的默认部分是名词。要得到动词,可以这样指定:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('playing', pos="v"))
结果:
play
实际上,这也是一种很好的文本压缩方式,最终得到文本只有原先的50%到60%。
结果还可以是动词(v)、名词(n)、形容词(a)或副词(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))输出:
play
playing
playing
playing
词干和变体的区别
通过下面例子来观察:
from nltk.stem import WordNetLemmatizer from nltk.stem import PorterStemmer stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print(stemmer.stem('stones')) print(stemmer.stem('speaking')) print(stemmer.stem('bedroom')) print(stemmer.stem('jokes')) print(stemmer.stem('lisa')) print(stemmer.stem('purple')) print('----------------------') print(lemmatizer.lemmatize('stones')) print(lemmatizer.lemmatize('speaking')) print(lemmatizer.lemmatize('bedroom')) print(lemmatizer.lemmatize('jokes')) print(lemmatizer.lemmatize('lisa')) print(lemmatizer.lemmatize('purple'))
输出:
stone
speak
bedroom
joke
lisa
purpl
---------------------
stone
speaking
bedroom
joke
lisa
purple
词干提取不会考虑语境,这也是为什么词干提取比变体还原快且准确度低的原因。
个人认为,变体还原比词干提取更好。单词变体还原返回一个真实的单词,即使它不是同一个单词,也是同义词,但至少它是一个真实存在的单词。
如果你只关心速度,不在意准确度,这时你可以选用词干提取。
在此NLP教程中讨论的所有步骤都只是文本预处理。在以后的文章中,将会使用Python NLTK来实现文本分析。
相关推荐:
위 내용은 Python NLP에 대한 간략한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!