
Python 텍스트 특징 추출 및 벡터화 알고리즘 학습 예제에 대한 자세한 설명

- 小云云원래의
- 2017-12-23 17:05:575308검색
우리가 방금 놀란의 블록버스터 "인터스텔라"를 보았다고 가정해 보겠습니다. 어떻게 기계가 영화에 대한 관객의 평가가 "긍정적"인지 "부정적"인지 자동으로 분석하도록 할 수 있습니까? 이런 유형의 문제는 감정 분석 문제입니다. 이러한 유형의 문제를 처리하는 첫 번째 단계는 텍스트를 기능으로 변환하는 것입니다. 이 글은 주로 Python 텍스트 특징 추출 및 벡터화 알고리즘을 자세히 소개합니다. 관심 있는 친구들이 참고할 수 있기를 바랍니다.
그래서 이 장에서는 첫 번째 단계인 텍스트에서 특징을 추출하고 벡터화하는 방법만 배웁니다.
중국어 처리에는 단어 분할이 포함되므로 이 기사에서는 간단한 예를 사용하여 Python의 기계 학습 라이브러리를 사용하여 영어에서 특징을 추출하는 방법을 설명합니다.
1. 데이터 준비
Python의 sklearn.datasets는 디렉토리에서 분류된 모든 텍스트 읽기를 지원합니다. 그러나 디렉터리는 하나의 폴더와 하나의 레이블 이름 규칙에 따라 배치되어야 합니다. 예를 들어, 이 기사에서 사용된 데이터 세트에는 총 2개의 레이블이 있으며 하나는 "net"이고 다른 하나는 "pos"이며 각 디렉터리 아래에는 6개의 텍스트 파일이 있습니다. 디렉토리는 다음과 같습니다:
neg
1.txt
2.txt
......
pos
1.txt
2.txt
....
12개 파일의 내용은 다음과 같습니다.
neg: shit. waste my money. waste of money. sb movie. waste of time. a shit movie. pos: nb! nb movie! nb! worth my money. I love this movie! a nb movie. worth it!
2. 텍스트 특징
이 영어 단어에서 감정적 태도를 추출하고 분류하는 방법은 무엇입니까?
가장 직관적인 방법은 단어를 추출하는 것입니다. 일반적으로 많은 키워드가 화자의 태도를 반영할 수 있다고 믿어집니다. 예를 들어, 위의 간단한 데이터 세트에서 "똥"이라고 말하는 모든 것이 부정 범주에 속해야 함을 쉽게 찾을 수 있습니다.
물론, 위의 데이터 세트는 단순히 설명의 편의를 위해 설계된 것입니다. 실제로 단어에는 모호한 태도가 있는 경우가 많습니다. 그러나 부정적인 범주에 단어가 더 많이 나타날수록 부정적인 태도를 표현할 가능성이 더 커진다고 믿을 만한 이유가 여전히 있습니다.
또한 일부 단어는 감정 분류에 의미가 없다는 것을 확인했습니다. 예를 들어, 위 데이터에는 "of", "I"와 같은 단어가 있습니다. 이러한 유형의 단어에는 "Stop_Word"(불용어)라는 이름이 있습니다. 그러한 단어는 완전히 무시되거나 계산되지 않을 수 있습니다. 분명히 이러한 단어를 무시하면 단어 빈도 레코드의 저장 공간이 최적화되고 구성 속도가 빨라집니다.
각 단어의 단어 빈도를 중요한 특징으로 활용하는 데에도 문제가 있습니다. 예를 들어 위 데이터에서 'movie'는 12개의 샘플에서 5번 등장하지만 긍정과 부정의 출현 횟수는 거의 동일해 차이가 없다. 그리고 "worth"가 두 번 나오긴 하는데, pos 카테고리에서만 확실히 강한 색감을 가지고 있어서 구별성이 매우 높습니다.
따라서 각 단어를 더 자세히 고려하려면 TF-IDF(용어 빈도-역문서 빈도, 용어 빈도 및 역문서 빈도)를 도입해야 합니다.
TF(용어 빈도)의 계산은 매우 간단합니다. 이는 문서 t에 대한 특정 단어 Nt가 문서에 나타나는 빈도입니다. 예를 들어, "I love this movie"라는 문서에서 "love"라는 단어의 TF는 1/4입니다. 불용어 "I"와 "it"를 제거하면 1/2이 됩니다.
IDF(Inverse Document Frequency)의 의미는 특정 단어 t에 대해 해당 단어가 나타나는 문서의 수 Dt가 전체 테스트 문서 D의 비율을 차지한다는 의미이며 자연로그를 구합니다.
예를 들어 'movie'라는 단어는 총 5번 등장하고, 총 문서 개수는 12개이므로 IDF는 ln(5/12)입니다.
물론 IDF는 드물게 등장하지만 감정적인 색채가 강한 단어를 강조하는 것입니다. 예를 들어, "movie"와 같은 단어의 IDF는 ln(12/5)=0.88이며, 이는 "love"=ln(12/1)=2.48의 IDF보다 훨씬 작습니다.
TF-IDF은 단순히 이 둘을 곱하는 것입니다. 이렇게 해서 각 문서에서 각 단어의 TF-IDF를 찾는 것이 우리가 추출한 텍스트 특징값이다.
3. 벡터화
위의 기초를 바탕으로 문서를 벡터화할 수 있습니다. 먼저 코드를 살펴보고 벡터화의 의미를 분석해 보겠습니다.
# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
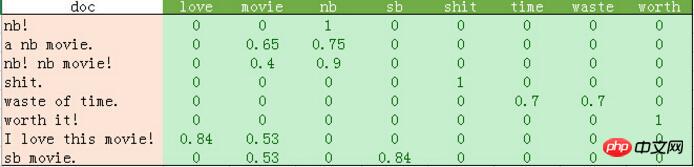
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3. count_vec.fit_transform의 결과는 거대한 행렬입니다. 위 표에는 0이 많이 있음을 알 수 있으므로 sklearn은 내부 구현을 위해 희소 행렬을 사용합니다. 이 예의 데이터는 작습니다. 독자들이 관심이 있다면 코넬 대학의 기계 학습 연구자들이 사용한 실제 데이터를 시험해 볼 수 있습니다: http://www.cs.cornell.edu/people/pabo/movie-review-data/. 이 웹사이트는 약 200만 개에 달하는 여러 데이터베이스를 포함하여 약 700개의 긍정적인 사례와 부정적인 사례가 포함된 많은 데이터 세트를 제공합니다. 이런 종류의 데이터는 규모가 크지 않으며 그래도 1분 안에 완료할 수 있으므로 시도해 보시기 바랍니다. 그러나 이러한 데이터 세트에는 잘못된 문자 문제가 있을 수 있다는 점에 유의하세요. 따라서 count_vec을 생성할 때 이러한 불법 문자를 무시하기 위해 decode_error = 'ignore'가 전달됩니다.
위 표의 결과는 8개 샘플에 8개 특성을 학습한 결과입니다. 이 결과는 다양한 분류 알고리즘을 사용하여 분류될 수 있습니다.
관련 추천:
Python 텍스트 유사성 계산의 편집 거리에 대한 자세한 설명
자세한 설명 예 Python은 간단한 웹 페이지 이미지 캡처를 구현합니다
위 내용은 Python 텍스트 특징 추출 및 벡터화 알고리즘 학습 예제에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!