
Jingdong 도서 크롤링을 위한 Python3 실용적인 크롤러에 대한 자세한 그래픽 및 텍스트 설명

- 黄舟원래의
- 2017-10-09 10:22:373120검색
저는 최근 python3을 배우고 있습니다. 다음 글에서는 Jingdong book 그림 크롤링을 위한 Python3 실용적인 크롤러에 대한 관련 정보를 주로 소개하고 있으며, 이는 모든 사람의 학습이나 작업에 대한 특정 참조 학습 가치를 가지고 있습니다. 필요한 친구들은 와서 아래를 살펴보세요.
머리말
최근 직장에서 JD.com의 책 사진과 제품 사진을 모두 로컬 컴퓨터에 다운로드해야 하는 상황이 발생했습니다. 매우 큰 프로젝트이므로 Python 웹 크롤러로 구현할 수 있습니다. 다음으로 이미지 크롤러를 구현하겠습니다.
분석 구현
먼저 크롤링할 첫 번째 웹페이지를 엽니다. 이 웹페이지는 크롤링할 시작 페이지로 사용됩니다. JD.com을 열고 책 카테고리를 선택합니다. 모든 유형의 책이 많기 때문에 모든 프로그래밍 언어의 책 이미지를 크롤링하기로 선택합니다. 웹사이트는 https://list.jd.com/list.html?cat입니다. =1713, 3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
사진과 같이 :
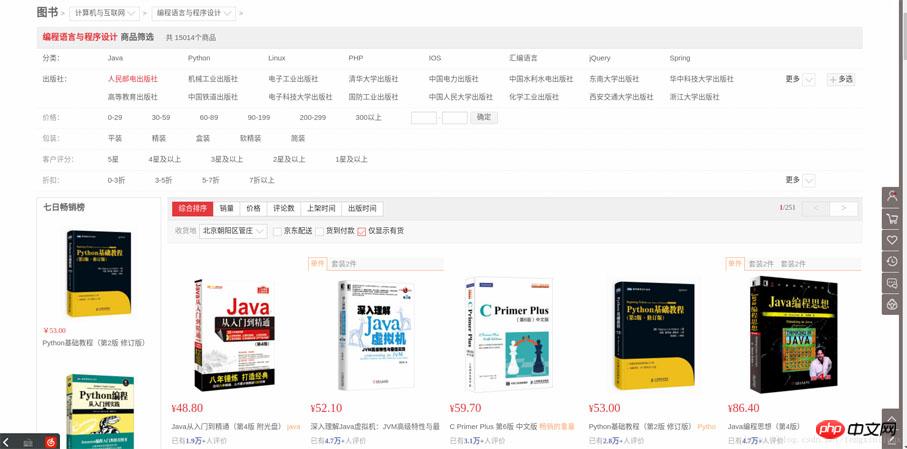
입력하시면 총 251페이지를 보실 수 있습니다.
그렇다면 첫 페이지 외에 다른 페이지도 자동으로 크롤링하려면 어떻게 해야 할까요?
"다음 페이지"를 클릭하면 URL의 변경 사항을 확인할 수 있습니다. 다음 페이지를 클릭한 후 URL이 https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main으로 변경된 것을 확인했습니다.
여기에서 얻을 페이지는 URL, 즉 GET을 통해 요청한 페이지로 식별되는 것을 알 수 있습니다. 이 GET 요청에는 여러 필드가 있으며 그 중 하나는 페이지이고 해당 값은 2입니다. 여기에서 URL의 주요 정보를 얻을 수 있습니다: https://list.jd.com/list.html ? 고양이=1713,3287,3797&페이지=2. 다음으로 추측을 바탕으로 page=2를 page=6으로 변경하고 6페이지에 성공적으로 진입할 수 있음을 확인했습니다.
이로부터 자동으로 여러 페이지를 얻는 방법을 생각할 수 있습니다. for 루프를 사용하여 구현할 수 있습니다. 각 루프 후에 해당 URL의 페이지 필드가 1씩 증가합니다. 즉, 자동으로 다음 페이지로 전환됩니다. 다음 페이지.
각 페이지에서 해당 이미지를 추출해야 합니다. 정규식을 사용하여 소스 코드에서 이미지의 링크 부분을 일치시킨 다음 urllib.request.urlretrieve()를 통해 해당 링크 이미지를 로컬에 저장할 수 있습니다.
하지만 이 웹 페이지의 사진에는 목록에 있는 제품의 사진이 포함되어 있을 뿐만 아니라 그 옆에 관련 없는 사진도 포함되어 있어 첫 번째 정보를 먼저 필터링할 수 있다는 문제가 있습니다. 필터링하면 중간에 있는 제품 목록 부분이 제거되고 데이터의 다른 부분은 필터링됩니다. 그림과 같이 마우스 오른쪽 버튼을 클릭하면 웹 페이지의 소스 코드를 볼 수 있습니다.
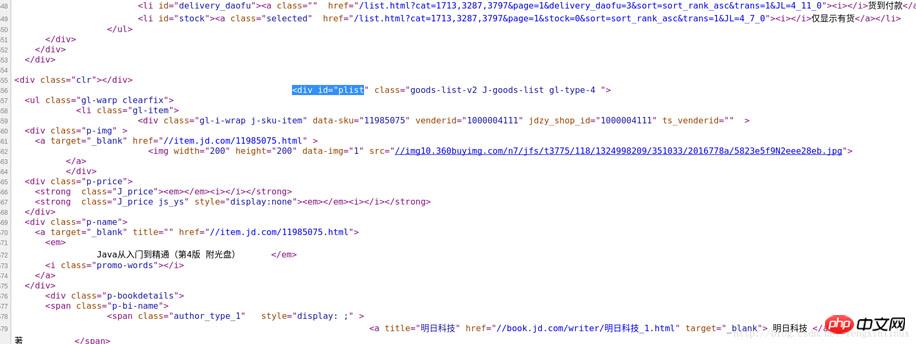
제품 목록의 첫 번째 제품 이름 "JAVA from Beginner"를 통해 소스 코드에서 해당 위치를 빠르게 찾을 수 있습니다. to Master"를 확인한 후 제품 목록의 특수 로고를 보면 그 위에 "
그렇다면 유효한 정보는 어디에서 끝나나요?
마지막 책의 소스 코드를 검색해도 마찬가지입니다. 이 페이지의 제품 목록에서 소스 코드 위치를 빠르게 찾아 분석할 수 있습니다. 코드는 그림과 같이 식별자로 사용됩니다.
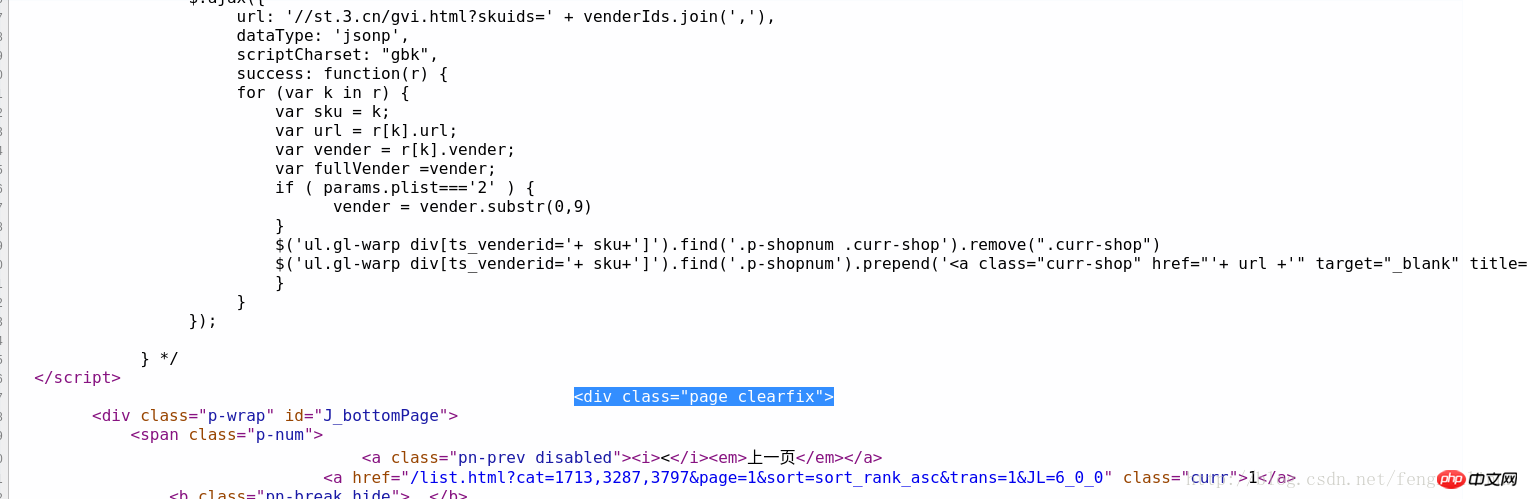
그래서 원하는 경우 첫 번째 필터링을 수행하기 위해 정규식은 다음과 같이 구성될 수 있습니다.
<p id="plist".+? <p class="page clearfix">
첫 번째 정보 필터링 후 남는 것은 이미지 링크입니다. 다음 단계는 이미지 링크 정보를 필터링하는 것입니다.
이번에는 웹 페이지에서 해당 이미지의 소스 코드를 관찰해야 합니다.
사진 1:
<img width="200" height="200" data-img="1" src="//img13.360buyimg.com/n7/jfs/t6130/167/771989293/235186/608d0264/592bf167Naf49f7f6.jpg">
사진 2:
<img width="200" height="200" data-img="1" src="//img10.360buyimg.com/n7/g14/M03/0E/0D/rBEhV1Im1n8IAAAAAAcHltD_3_8AAC0FgC-1WoABweu831.jpg">
두 사진 코드를 비교해보니 기본 형식은 동일하지만 사진의 링크 URL이 다르기 때문에 이번에는 구성을 해보겠습니다. 이 규칙에 따라 이미지 링크를 추출하는 정규식:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">
刚开始到这里,我以为就结束了,后来在爬取的过程中我发现每一页都少爬取了很多图片,再次查看源码发现,每页后面的几十张图片又是另一种格式:
<img width="200" height="200" data-img="1" src-img="//img10.360buyimg.com/n7/jfs/t3226/230/618950227/110172/7749a8bc/57bb23ebNfe011bfe.jpg">
所以,完整的正则表达式应该是这两种格式的或:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|
到这里,我们根据该正则表达式,就可以提取出一个页面中所有想要爬取的图片链接。
所以,根据上面的分析,我们可以得到该爬虫的编写思路与过程,具体如下:
建立一个爬取图片的自定义函数,该函数负责爬取一个页面下的我们想爬取的图片,爬取过程为:首先通过
urllib.request.utlopen(url).read()读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤,过滤完成之后,在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有的目标图片的链接,并将这些链接地址存储的一个列表中,随后遍历该列表,分别将对应链接通过urllib.request.urlretrieve(imageurl,filename=imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理。通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为url='https://list.jd.com/list.html?cat=1713,3287,3797&page=' + str(i)
完整的代码如下:
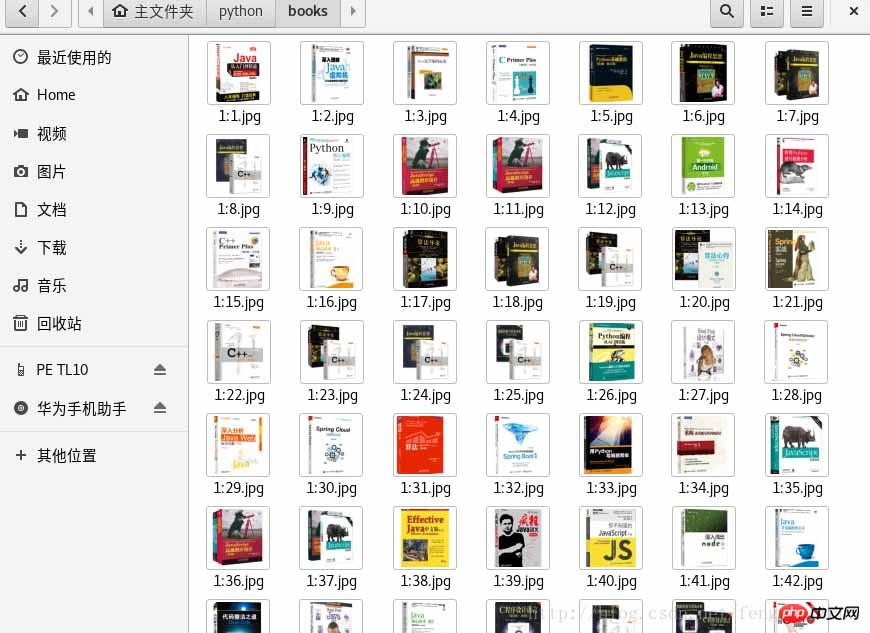
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import re import urllib.request import urllib.error import urllib.parse sum = 0 def craw(url,page): html1=urllib.request.urlopen(url).read() html1=str(html1) pat1=r'<p id="plist".+? <p class="page clearfix">' result1=re.compile(pat1).findall(html1) result1=result1[0] pat2=r'<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|' imagelist=re.compile(pat2).findall(result1) x=1 global sum for imageurl in imagelist: imagename='./books/'+str(page)+':'+str(x)+'.jpg' if imageurl[0]!='': imageurl='http://'+imageurl[0] else: imageurl='http://'+imageurl[1] print('开始爬取第%d页第%d张图片'%(page,x)) try: urllib.request.urlretrieve(imageurl,filename=imagename) except urllib.error.URLError as e: if hasattr(e,'code') or hasattr(e,'reason'): x+=1 print('成功保存第%d页第%d张图片'%(page,x)) x+=1 sum+=1 for i in range(1,251): url='https://list.jd.com/list.html?cat=1713,3287,3797&page='+str(i) craw(url,i) print('爬取图片结束,成功保存%d张图'%sum)
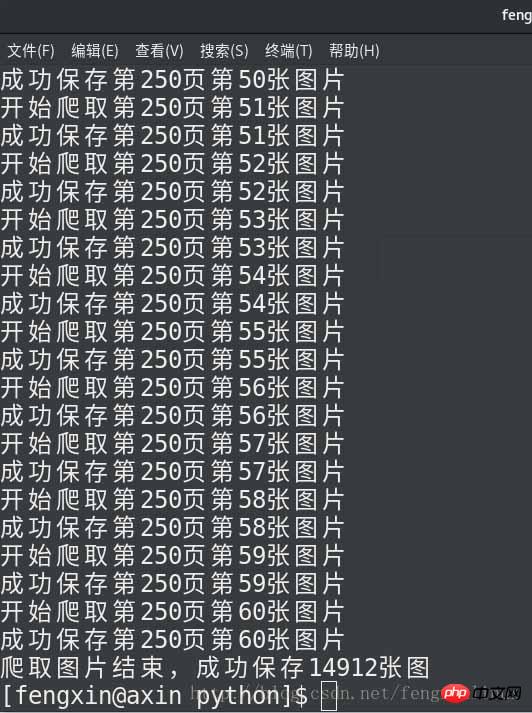
运行结果如下:
总结
위 내용은 Jingdong 도서 크롤링을 위한 Python3 실용적인 크롤러에 대한 자세한 그래픽 및 텍스트 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!