
Python의 map() 함수 메소드 예

- 黄舟원래의
- 2017-10-03 05:45:031758검색
map()은 Python에 내장된 고차 함수입니다. 함수 f와 목록을 받고, 함수 f를 목록의 각 요소에 차례로 적용하여 새로운 목록을 얻어 반환합니다. 다음 글은 주로 파이썬에서 map() 함수를 사용하는 방법을 소개합니다. 필요하신 분들은 참고하시면 됩니다.
머리말
파이썬에는 map() 함수가 있는데 좀 화려하네요. 느끼다. 이 기사에서는 Python에서 map() 함수의 사용에 대해 자세히 소개하고 참고 및 학습을 위해 공유합니다. 아래에서는 자세한 소개를 살펴보겠습니다.
아마도요. 당신은 이미 GOOGLE의 가장 수익성이 높은 Qian의 논문을 보았습니다: "MapReduce: Simplified Data Process on Large Clusters" Google의 MapReduce 논문은 다음과 같이 말했습니다: 우리의 추상화는 Lisp 및 기타 여러 기능적 언어에 존재하는 맵 및 축소 프리미티브에서 영감을 받았습니다.
그렇다면 map()은 정확히 무엇을 하는 걸까요?
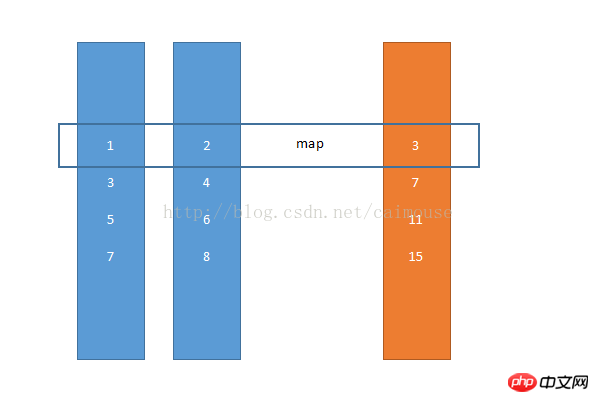
사실 map() 함수는 하나의 데이터 세트와 다른 데이터 세트 사이의 매핑 관계로 중간에 요소가 줄어들거나 추가되지 않습니다. 따라서 파이썬에서는 map() 함수가 여러 리스트 객체에서 요소를 순서대로 꺼낸 후 이를 함수에 넣어 연산하고 결과를 계산하는 함수입니다. 이는 병렬 관계이며 요소를 줄이지 않습니다.
예:
#python 3. 6
#蔡军生
#http://blog.csdn.net/caimouse/article/details/51749579
#
def sum(x, y):
return x + y
list1 = [1, 3, 5, 7]
list2 = [2, 4, 6, 8]
result = map(sum, list1, list2)
print([x for x in result])
출력 결과는 다음과 같습니다.
[3, 7, 11, 15]
마찬가지로 지도 기능도 가능합니다 클러스터 서버를 이용하여 많은 양의 데이터를 분할한 후, 각 데이터 조각을 서로 다른 컴퓨터에 넣어 병렬 처리를 하고, 동일한 매핑 관계를 계산하여 데이터 수가 늘어나거나 줄어들지 않는다는 아이디어입니다. 그런 다음 이러한 처리된 데이터는 축소 프로세스를 위해 함께 수집됩니다.
요약
위 내용은 Python의 map() 함수 메소드 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!