
Python에서 Django와 함께 haystack을 사용하는 방법: 전체 텍스트 검색 프레임워크의 예

- 黄舟원래의
- 2017-10-03 06:00:562221검색
아래 편집기는 전체 텍스트 검색 프레임워크(예제 설명)인 Python 및 Django에서 haystack을 사용하는 방법에 대한 기사를 제공합니다. 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리도록 하겠습니다. 에디터를 따라가서 함께 살펴볼까요
haystack: 전체 텍스트 검색 프레임워크
whoosh: 순수 Python으로 작성된 전체 텍스트 검색 엔진
jieba: 무료 중국어 단어 분할 패키지
먼저 이 세 가지 패키지를 설치하세요
pip install django-haystack
pip install whoosh
pip install jieba
1 settings.py 파일을 수정하고 애플리케이션 haystack을 설치하세요,
2 . settings.py 파일에서
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3에서 검색 엔진을 구성합니다. 템플릿 디렉터리 아래에 "search/indexes/blog/" 디렉터리를 만들고 블로그 애플리케이션 이름
#Specify 아래에 blog_text.txt 파일을 만듭니다. index
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
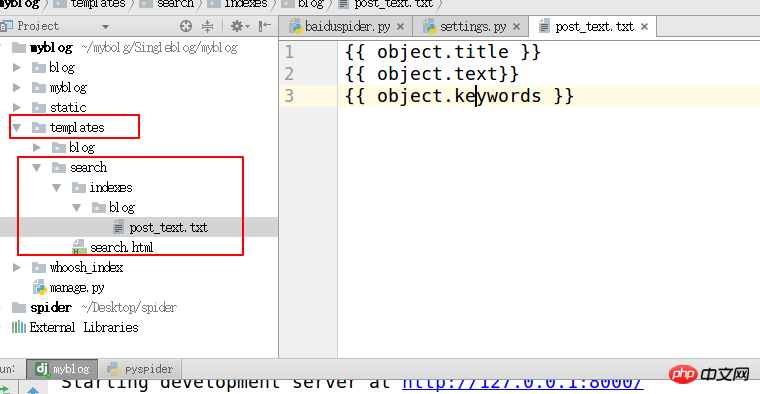
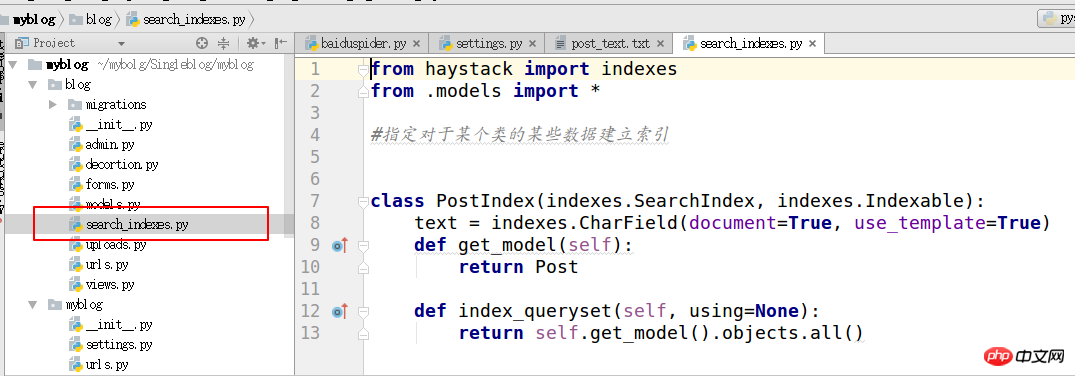
4의 속성 search_indexes
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
5.
1. haystack 파일 수정
2. 가상 환경 py_django에서 haystack 디렉터리를 찾으세요. 이 디렉터리는 사용 중인 Python 환경에 따라 다릅니다.
3.site-packages/haystack/backends/ ChineseAnalyzer.py라는 파일을 만들고 중국어 단어 분할을 위해 다음 코드를 작성합니다
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()6.
1. whoosh_backend.py 파일을 복사하여 변경합니다. 중국어 단어 분할 모듈을 다음 이름의 복사된 파일로 가져옵니다
whoosh_cn_backend.py
from . ChineseAnalyzer import ChineseAnalyzer
2. 단어 분석 클래스를 Chinese로 변경합니다
analyzer=StemmingAnalyzer()를 찾아 다음으로 변경합니다. analyzer= ChineseAnalyzer()
7. 마지막 단계는 초기 인덱스 데이터를 생성하는 것입니다
pythonmanage.pybuild_index
8.templates/indexes/에 검색 템플릿을 생성하고 search.html 템플릿을 생성합니다
. 페이지가 매겨지고 뷰가 템플릿에 전달됩니다. 컨텍스트는 다음과 같습니다.
query: 검색 키워드
page: 현재 페이지의 페이지 개체
paginator: paginator 개체
9. 애플리케이션 보기
from haystack.generic_views import SearchView
사용자 정의 컨텍스트를 템플릿에 전달할 수 있도록 get_context_data 메서드를 재정의하는 클래스를 정의하세요.
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
이 URL을 애플리케이션의 URL 파일에 추가하고 클래스를 보기 메서드 .as_view()로 사용하세요.
url('^search/$', views.BlogSearchView.as_view())
위 내용은 Python에서 Django와 함께 haystack을 사용하는 방법: 전체 텍스트 검색 프레임워크의 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!