
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 고가용성 솔루션 MMM에 대한 자세한 설명
MySQL 고가용성 솔루션 MMM에 대한 자세한 설명

- 黄舟원래의
- 2017-10-04 09:26:271992검색
MySQL 자체는 복제 장애 조치 솔루션을 제공하지 않습니다. MMM 솔루션을 통해 서버 장애 조치를 수행할 수 있으므로 mysql의 고가용성을 달성할 수 있습니다. MMM은 유동 IP 기능을 제공할 뿐만 아니라, 현재 마스터 서버가 중단되면 수동으로 동기화 구성을 변경할 필요 없이 백엔드 슬레이브 서버가 자동으로 새 마스터 서버로 전송되어 동기 복제를 수행합니다
1. MMM 소개:
MMM은 MySQL용 다중 마스터 복제 관리자입니다. mysql 다중 마스터 복제 관리자는 Perl 구현을 기반으로 하며 mysql 마스터-마스터 복제 구성의 모니터링, 장애 조치 및 관리를 위한 확장 가능한 스크립트 제품군입니다(단 하나의 노드) 언제든지 쓸 수 있음) MMM은 슬레이브 서버에서 읽기 로드 밸런싱을 수행할 수도 있으므로 복제에 사용되는 서버 그룹에서 가상 IP를 시작하는 데 사용할 수 있습니다. 또한 데이터 백업을 구현하고 노드 간 다시 시작할 수도 있습니다. . 동기화 기능을 위한 스크립트입니다. MySQL 자체는 복제 장애 조치 솔루션을 제공하지 않습니다. MMM 솔루션을 통해 서버 장애 조치를 수행할 수 있으므로 MySQL의 고가용성을 달성할 수 있습니다. MMM은 유동 IP 기능을 제공할 뿐만 아니라 현재 마스터 서버가 중단되는 경우에도 동기화 구성을 수동으로 변경할 필요 없이 백엔드 슬레이브 서버가 자동으로 새 마스터 서버로 전송되어 동기 복제를 수행합니다. 이 솔루션은 현재 비교적 성숙한 솔루션입니다. 자세한 내용은 공식 홈페이지를 참고하세요: http://mysql-mmm.org
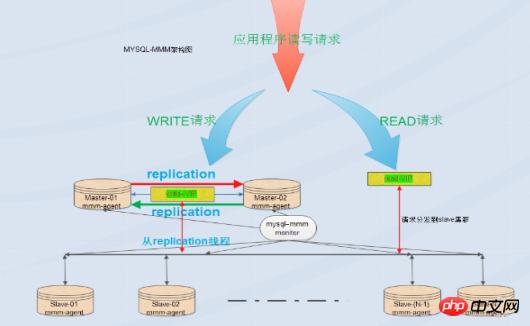
장점: 고가용성, 우수한 확장성, 장애 시 자동 전환, 마스터-마스터 동기화, 단 한 번의 데이터베이스 쓰기 작업이 동시에 제공되어 데이터 일관성이 보장됩니다. 마스터 서버가 중단되면 다른 마스터가 즉시 인계받고 다른 슬레이브 서버는 수동 개입 없이 자동으로 전환될 수 있습니다.
단점: 모니터 노드는 단일 지점이지만 이를 keepalived 또는 haertbeat와 결합하여 가용성을 높일 수도 있습니다. 최소 3개의 노드에는 호스트 수가 필요하고 읽기 및 쓰기 분리가 필요합니다. 리더는 프런트 엔드에 작성해야 합니다. 분리 프로그램을 작성합니다. 읽기와 쓰기 작업이 많은 비즈니스 시스템에서는 성능이 그다지 안정적이지 않으며 복제 지연, 전환 실패 등의 문제가 발생할 수 있습니다. MMM 솔루션은 데이터 보안 요구 사항이 높고 읽기 및 쓰기 작업이 바쁜 환경에는 적합하지 않습니다.
적용 가능한 시나리오:
MMM은 데이터베이스 액세스 규모가 크고 읽기와 쓰기가 분리될 수 있는 시나리오에 적합합니다.
Mmm의 주요 기능은 다음 세 가지 스크립트에 의해 제공됩니다.
mmm_mond는 모든 모니터링 작업을 담당하는 모니터링 데몬 프로세스로, 노드 제거를 결정합니다(mmm_mond 프로세스는 정기적인 하트비트 감지를 프로세스하며, 실패할 경우 쓰기 IP가
mmm_agentd는 mysql 서버에서 실행되는 에이전트 데몬으로 간단한 원격 서비스 세트를 통해 모니터링 노드에 제공됩니다.
mmm_control은 명령줄을 통해 mmm_mond 프로세스를 관리합니다.
전체 모니터링 프로세스 동안 관련 권한이 부여됩니다. 사용자를 mysql에 추가해야 합니다. 승인된 사용자에는 mmm_monitor 사용자와 mmm_agent 사용자가 포함됩니다. mmm의 백업 도구를 사용하려면 mmm_tools 사용자도 추가해야 합니다.
2. 배포 및 구현
1. 환경 소개
OS: centos7.2(64비트) 데이터베이스 시스템: mysql5.7.13
selinux 닫기
ntp 구성, 시간 동기화
| role
|
IP | hostname | Server-id | vip 쓰기 | vip 읽기 |
| Master1
|
192.168.31.83 | master1
| 1 | 192.168.31.2 | |
| Master2(백업) | 192.168.31.141 | master2 | 2 | 192.168. 31.3
|
|
| Slave1 | 192.168.31.250 | slave1 | 3 |
|
19 2.168.31.4 |
| Slave2 | 192.168.31.225 | slave2 | 4# 2.168.31.106 | monitor1 |
없음 |
|
2. 모든 호스트에서 /etc/hosts 파일을 구성하고 다음 콘텐츠를 추가합니다. 192.168.31.83 master1 전체 호스트 설치 Perl, Perl-develperl-cpan libart_lgpl.x86_64 rrdtool.x86_64 rrdtool-perl.x86_64 패키지 Perl 관련 라이브러리 설치 #cpan -i Algorithm::Diff Class::Singleton DBI DBD::mysql Log::Dispatch Log::Log4perl Mail::Send Net::Ping Proc::Daemon Time: :HiRes Params::Validate Net::ARP3. mysql5.7을 설치하고 master1, master2, 슬레이브1, 슬레이브2에서 복제를 구성합니다. 호스트master1과 master2는 서로의 마스터이자 슬레이브이고, 슬레이브1과 슬레이브2는 master1의 슬레이브입니다.각 mysql 구성 파일 /etc/my.cnf에 다음 내용을 추가합니다. server_id는 반복될 수 없습니다. master1 호스트: log-bin = mysql-bin binlog_format = mixed server-id = 1 relay-log = relay-bin relay-log-index = slave-relay-bin.index log-slave-updates = 1 auto-increment-increment = 2 auto-increment-offset = 1 master2主机: log-bin = mysql-bin binlog_format = mixed server-id = 2 relay-log = relay-bin relay-log-index = slave-relay-bin.index log-slave-updates = 1 auto-increment-increment = 2 auto-increment-offset = 2 slave1主机: server-id = 3 relay-log = relay-bin relay-log-index = slave-relay-bin.index read_only = 1 slave2主机: server-id = 4 relay-log = relay-bin relay-log-index = slave-relay-bin.index read_only = 1 my.cnf 수정을 완료한 후 systemctl restart mysqld를 통해 mysql 서비스를 다시 시작하세요. firewall-cmd --permanent --add-port=3306/tcp firewall-cmd --reload Master-slave 구성(master1 및 master2는 마스터로 구성되고, Slave1 및 Slave2는 슬레이브로 구성됨) master1의):master1 권한 부여: mysql> grant replication slave on *.* to rep@'192.168.31.%' identified by '123456'; master2에 대한 권한 부여: mysql> grant replication slave on *.* to rep@'192.168.31.%' identified by '123456'; master2, Slave1 및 Slave2를 master1의 슬레이브 라이브러리로 구성: master1에서 show master status를 실행하고 위치 지점을 가져옵니다. mysql> show master status; +------------------+----------+--------------+------------------+--------------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+---------------------------------------------------+ | mysql-bin.000001 | 452 | | | | +------------------+----------+--------------+------------------+-----------------------------------------------------+ master2,slave1 및slave2에서 mysql> change master to master_host='192.168.31.83',master_port=3306,master_user='rep',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=452; mysql>slave start; 실행 _Running 및 Slave_SQL_Running은 모두 yes입니다. , 그러면 마스터-슬레이브가 이미 구성되었습니다. mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.83 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 452 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes master1에서 실행: mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.83 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 452 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes 마스터 확인 -슬레이브 복제:master1 호스트: mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.83 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 452 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: YesSlave_IO_Running 및 Slave_SQL_Running이 모두 yes이면 마스터-슬레이브 구성은 OK입니다. 4 mysql-mmm 구성: mysql> show master status; +------------------+----------+--------------+------------------+--------------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+---------------------------------------------------+ | mysql-bin.000001 | 452 | | | | +------------------+----------+--------------+------------------+----------------------------------------------------+
mysql> change master to master_host='192.168.31.141',master_port=3306,master_user='rep',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=452; mysql> start slave; 참고1: 이전 마스터-슬레이브 복제와 마스터-슬레이브는 이미 괜찮기 때문에 master1 서버에서 실행했는데 괜찮았습니다. master2,slave1,slave2 DB에 모니터링 및 에이전트 계정이 있는지 확인 mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.141 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 452 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes 또는 mysql> grant super,replicationclient,process on *.* to 'mmm_agent'@'192.168.31.%' identified by '123456';참고 2: mmm_monitor 사용자: mmm 모니터링은 mysql 서버 프로세스의 상태를 확인하는 데 사용됩니다. mysql> grant replication client on *.* to 'mmm_monitor'@'192.168.31.%' identified by '123456'; 데이터베이스 서버(master1, master2, slave1,slave2) Agent mysql> select user,host from mysql.user where user in ('mmm_monitor','mmm_agent'); +-------------+----------------------------+ | user | host | +-------------+----------------------------+ | mmm_agent | 192.168.31.% | | mmm_monitor | 192.168.31.% | +-------------+------------------------------+
<host default> cluster_interfaceeno16777736#群集的网络接口 pid_path /var/run/mmm_agentd.pid#pid路径 bin_path /usr/lib/mysql-mmm/#可执行文件路径 replication_user rep#复制用户 replication_password 123456#复制用户密码 agent_usermmm_agent#代理用户 agent_password 123456#代理用户密码 </host> <host master1>#master1的host名 ip 192.168.31.83#master1的ip mode master#角色属性,master代表是主 peer master2#与master1对等的服务器的host名,也就是master2的服务器host名 </host> <host master2>#和master的概念一样 ip 192.168.31.141 mode master peer master1 </host> <host slave1>#从库的host名,如果存在多个从库可以重复一样的配置 ip 192.168.31.250#从的ip mode slave#slave的角色属性代表当前host是从 </host> <host slave2>#和slave的概念一样 ip 192.168.31.225 mode slave </host> <role writer>#writer角色配置 hosts master1,master2#能进行写操作的服务器的host名,如果不想切换写操作这里可以只配置master,这样也可以避免因为网络延时而进行write的切换,但是一旦master出现故障那么当前的MMM就没有writer了只有对外的read操作。 #chkconfig --add mysql-mmm-agent #chkconfigmysql-mmm-agent on #/etc/init.d/mysql-mmm-agent start 注:添加source /root/.bash_profile目的是为了mysql-mmm-agent服务能启机自启。 Daemon bin: '/usr/sbin/mmm_agentd' Daemon pid: '/var/run/mmm_agentd.pid' Starting MMM Agent daemon... Can't locate Proc/Daemon.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/sbin/mmm_agentd line 7. BEGIN failed--compilation aborted at /usr/sbin/mmm_agentd line 7. failed 解决方法: # cpanProc::Daemon # cpan Log::Log4perl # /etc/init.d/mysql-mmm-agent start Daemon bin: '/usr/sbin/mmm_agentd' Daemon pid: '/var/run/mmm_agentd.pid' Starting MMM Agent daemon... Ok # netstat -antp | grep mmm_agentd tcp 0 0 192.168.31.83:9989 0.0.0.0:* LISTEN 9693/mmm_agentd 配置防火墙 firewall-cmd --permanent --add-port=9989/tcp firewall-cmd --reload 编辑 monitor主机上的/etc/mysql-mmm/mmm_mon.conf includemmm_common.conf <monitor> ip 127.0.0.1##为了安全性,设置只在本机监听,mmm_mond默认监听9988 pid_path /var/run/mmm_mond.pid bin_path /usr/lib/mysql-mmm/ status_path/var/lib/misc/mmm_mond.status ping_ips192.168.31.83,192.168.31.141,192.168.31.250,192.168.31.225#用于测试网络可用性 IP 地址列表,只要其中有一个地址 ping 通,就代表网络正常,这里不要写入本机地址 auto_set_online 0#设置自动online的时间,默认是超过60s就将它设置为online,默认是60s,这里将其设为0就是立即online </monitor> <check default> check_period 5 trap_period 10 timeout 2 #restart_after 10000 max_backlog 86400 </check> check_period 描述:检查周期默认为5s <host default> monitor_usermmm_monitor#监控db服务器的用户 monitor_password 123456#监控db服务器的密码 </host> debug 0#debug 0正常模式,1为debug模式 启动监控进程: 在 /etc/init.d/mysql-mmm-agent的脚本文件的#!/bin/sh下面,加入如下内容 source /root/.bash_profile 添加成系统服务并设置为自启动 #chkconfig --add mysql-mmm-monitor #chkconfigmysql-mmm-monitor on #/etc/init.d/mysql-mmm-monitor start 启动报错: Starting MMM Monitor daemon: Can not locate Proc/Daemon.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/sbin/mmm_mond line 11. BEGIN failed--compilation aborted at /usr/sbin/mmm_mond line 11. failed 解决方法:安装下列perl的库 #cpanProc::Daemon #cpan Log::Log4perl [root@monitor1 ~]# /etc/init.d/mysql-mmm-monitor start Daemon bin: '/usr/sbin/mmm_mond' Daemon pid: '/var/run/mmm_mond.pid' Starting MMM Monitor daemon: Ok [root@monitor1 ~]# netstat -anpt | grep 9988 tcp 0 0 127.0.0.1:9988 0.0.0.0:* LISTEN 8546/mmm_mond 注1:无论是在db端还是在监控端如果有对配置文件进行修改操作都需要重启代理进程和监控进程。 检查集群状态: [root@monitor1 ~]# mmm_control show master1(192.168.31.83) master/ONLINE. Roles: writer(192.168.31.2) master2(192.168.31.141) master/ONLINE. Roles: reader(192.168.31.5) slave1(192.168.31.250) slave/ONLINE. Roles: reader(192.168.31.4) slave2(192.168.31.225) slave/ONLINE. Roles: reader(192.168.31.3) 如果服务器状态不是ONLINE,可以用如下命令将服务器上线,例如: #mmm_controlset_online主机名 例如:[root@monitor1 ~]#mmm_controlset_onlinemaster1 [root@master1 ~]# ipaddr show dev eno16777736 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdiscpfifo_fast state UP qlen 1000 link/ether 00:0c:29:6d:2f:82 brdff:ff:ff:ff:ff:ff inet 192.168.31.83/24 brd 192.168.31.255 scope global eno16777736 valid_lft forever preferred_lft forever inet 192.168.31.2/32 scope global eno16777736 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe6d:2f82/64 scope link valid_lft forever preferred_lft forever [root@master2 ~]# ipaddr show dev eno16777736 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdiscpfifo_fast state UP qlen 1000 link/ether 00:0c:29:75:1a:9c brdff:ff:ff:ff:ff:ff inet 192.168.31.141/24 brd 192.168.31.255 scope global dynamic eno16777736 valid_lft 35850sec preferred_lft 35850sec inet 192.168.31.5/32 scope global eno16777736 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe75:1a9c/64 scope link valid_lft forever preferred_lft forever [root@slave1 ~]# ipaddr show dev eno16777736 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdiscpfifo_fast state UP qlen 1000 link/ether 00:0c:29:02:21:19 brdff:ff:ff:ff:ff:ff inet 192.168.31.250/24 brd 192.168.31.255 scope global dynamic eno16777736 valid_lft 35719sec preferred_lft 35719sec inet 192.168.31.4/32 scope global eno16777736 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe02:2119/64 scope link valid_lft forever preferred_lft forever [root@slave2 ~]# ipaddr show dev eno16777736 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdiscpfifo_fast state UP qlen 1000 link/ether 00:0c:29:e2:c7:fa brdff:ff:ff:ff:ff:ff inet 192.168.31.225/24 brd 192.168.31.255 scope global dynamic eno16777736 valid_lft 35930sec preferred_lft 35930sec inet 192.168.31.3/32 scope global eno16777736 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fee2:c7fa/64 scope link valid_lft forever preferred_lft forever 在master2,slave1,slave2主机上查看主mysql的指向 mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.83 Master_User: rep Master_Port: 3306 Connect_Retry: 60 MMM高可用性测试: 服务器读写采有VIP地址进行读写,出现故障时VIP会漂移到其它节点,由其它节点提供服务。 [root@monitor1 ~]# mmm_control show master1(192.168.31.83) master/ONLINE. Roles: writer(192.168.31.2) master2(192.168.31.141) master/ONLINE. Roles: reader(192.168.31.5) slave1(192.168.31.250) slave/ONLINE. Roles: reader(192.168.31.4) slave2(192.168.31.225) slave/ONLINE. Roles: reader(192.168.31.3) 模拟master1宕机,手动停止mysql服务,观察monitor日志,master1的日志如下: [root@monitor1 ~]# tail -f /var/log/mysql-mmm/mmm_mond.log 2017/01/09 22:02:55 WARN Check 'rep_threads' on 'master1' is in unknown state! Message: UNKNOWN: Connect error (host = 192.168.31.83:3306, user = mmm_monitor)! Can't connect to MySQL server on '192.168.31.83' (111) 2017/01/09 22:02:55 WARN Check 'rep_backlog' on 'master1' is in unknown state! Message: UNKNOWN: Connect error (host = 192.168.31.83:3306, user = mmm_monitor)! Can't connect to MySQL server on '192.168.31.83' (111) 2017/01/09 22:03:05 ERROR Check 'mysql' on 'master1' has failed for 10 seconds! Message: ERROR: Connect error (host = 192.168.31.83:3306, user = mmm_monitor)! Can't connect to MySQL server on '192.168.31.83' (111) 2017/01/09 22:03:07 FATAL State of host 'master1' changed from ONLINE to HARD_OFFLINE (ping: OK, mysql: not OK) 2017/01/09 22:03:07 INFO Removing all roles from host 'master1': 2017/01/09 22:03:07 INFO Removed role 'writer(192.168.31.2)' from host 'master1' 2017/01/09 22:03:07 INFO Orphaned role 'writer(192.168.31.2)' has been assigned to 'master2' 查看群集的最新状态 [root@monitor1 ~]# mmm_control show master1(192.168.31.83) master/HARD_OFFLINE. Roles: master2(192.168.31.141) master/ONLINE. Roles: reader(192.168.31.5), writer(192.168.31.2) slave1(192.168.31.250) slave/ONLINE. Roles: reader(192.168.31.4) slave2(192.168.31.225) slave/ONLINE. Roles: reader(192.168.31.3) 从显示结果可以看出master1的状态有ONLINE转换为HARD_OFFLINE,写VIP转移到了master2主机上。 [root@monitor1 ~]# mmm_control checks all master1 ping [last change: 2017/01/09 21:31:47] OK master1 mysql [last change: 2017/01/09 22:03:07] ERROR: Connect error (host = 192.168.31.83:3306, user = mmm_monitor)! Can't connect to MySQL server on '192.168.31.83' (111) master1 rep_threads [last change: 2017/01/09 21:31:47] OK master1 rep_backlog [last change: 2017/01/09 21:31:47] OK: Backlog is null slave1 ping [last change: 2017/01/09 21:31:47] OK slave1mysql [last change: 2017/01/09 21:31:47] OK slave1 rep_threads [last change: 2017/01/09 21:31:47] OK slave1 rep_backlog [last change: 2017/01/09 21:31:47] OK: Backlog is null master2 ping [last change: 2017/01/09 21:31:47] OK master2 mysql [last change: 2017/01/09 21:57:32] OK master2 rep_threads [last change: 2017/01/09 21:31:47] OK master2 rep_backlog [last change: 2017/01/09 21:31:47] OK: Backlog is null slave2 ping [last change: 2017/01/09 21:31:47] OK slave2mysql [last change: 2017/01/09 21:31:47] OK slave2 rep_threads [last change: 2017/01/09 21:31:47] OK slave2 rep_backlog [last change: 2017/01/09 21:31:47] OK: Backlog is null 从上面可以看到master1能ping通,说明只是服务死掉了。 查看master2主机的ip地址: [root@master2 ~]# ipaddr show dev eno16777736 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdiscpfifo_fast state UP qlen 1000 link/ether 00:0c:29:75:1a:9c brdff:ff:ff:ff:ff:ff inet 192.168.31.141/24 brd 192.168.31.255 scope global dynamic eno16777736 valid_lft 35519sec preferred_lft 35519sec inet 192.168.31.5/32 scope global eno16777736 valid_lft forever preferred_lft forever inet 192.168.31.2/32 scope global eno16777736 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe75:1a9c/64 scope link valid_lft forever preferred_lft forever slave1主机: mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.141 Master_User: rep Master_Port: 3306 slave2主机: mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.31.141 Master_User: rep Master_Port: 3306 启动master1主机的mysql服务,观察monitor日志,master1的日志如下: [root@monitor1 ~]# tail -f /var/log/mysql-mmm/mmm_mond.log 2017/01/09 22:16:56 INFO Check 'mysql' on 'master1' is ok! 2017/01/09 22:16:56 INFO Check 'rep_backlog' on 'master1' is ok! 2017/01/09 22:16:56 INFO Check 'rep_threads' on 'master1' is ok! 2017/01/09 22:16:59 FATAL State of host 'master1' changed from HARD_OFFLINE to AWAITING_RECOVERY 从上面可以看到master1的状态由hard_offline改变为awaiting_recovery状态 [root@monitor1 ~]#mmm_controlset_onlinemaster1
[root@monitor1 ~]# mmm_control show master1(192.168.31.83) master/ONLINE. Roles: master2(192.168.31.141) master/ONLINE. Roles: reader(192.168.31.5), writer(192.168.31.2) slave1(192.168.31.250) slave/ONLINE. Roles: reader(192.168.31.4) slave2(192.168.31.225) slave/ONLINE. Roles: reader(192.168.31.3) 可以看到主库启动不会接管主,只到现有的主再次宕机。 附: 1、日志文件: 4、其它处理问题 작성기가 마스터에서 백업으로 전환되는 것을 원하지 않는 경우(쓰기 VIP 전환을 유발하는 마스터-슬레이브 지연 포함) /etc/mysql-mmm을 구성할 때 3612df8997eca9306e1f789dddf71f78 /mmm_common.conf backup 5. 요약 1. 외부 읽기 및 쓰기를 제공하는 가상 IP는 모니터 프로그램에 의해 제어됩니다. 모니터가 시작되지 않으면 DB 서버에 가상 IP가 할당되지 않습니다. 그러나 가상 IP가 할당된 경우 모니터 프로그램이 원래 할당된 가상 IP를 닫으면 외부 프로그램이 즉시 닫히지 않고 외부 프로그램이 종료됩니다. 프로그램은 계속 연결되고 액세스될 수 있습니다(네트워크가 다시 시작되지 않는 한). 이것의 장점은 모니터에 대한 안정성 요구 사항이 낮다는 것입니다. 그러나 이때 DB 서버 중 하나에 오류가 발생하지 않습니다. 즉, 원래의 가상 IP는 그대로 유지되며, 실패한 DB는 스위치를 처리할 수 없게 됩니다. 2. 에이전트 프로그램은 모니터 프로그램에 의해 제어되며 쓰기 전환, 슬레이브 라이브러리 전환 등의 작업을 처리합니다. 모니터 프로세스가 닫히면 에이전트 프로세스는 어떤 역할도 수행하지 않으며 자체적으로 오류를 처리할 수 없습니다. 3. 모니터 프로그램은 MySQL 데이터베이스를 포함한 db 서버의 상태, 서버 실행 여부, 복제 스레드가 정상인지 여부, 마스터-슬레이브 지연 등을 제어하는 데에도 사용됩니다. 오류를 처리하는 에이전트 프로그램입니다. 4. 모니터는 몇 초마다 DB 서버의 상태를 모니터링합니다. DB 서버가 오류에서 정상으로 변경된 경우 모니터는 60초 후에 자동으로 온라인 상태로 설정합니다(기본값은 60초이며 설정 가능). 다른 값으로) 클러스터 서버의 상태는 HARD_OFFLINE→AWAITING_RECOVERY→online |
위 내용은 MySQL 고가용성 솔루션 MMM에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!