
Python3 기본 크롤러 소개
- 一个新手원래의
- 2017-09-25 10:53:482476검색
python3 기본 크롤러 시작하는 방법
블로그 작성이 처음이라 조금 긴장되니까 싫으면 댓글 달지 마세요.
혹시 부족한 부분이 있다면 독자님들께서 지적해 주시면 수정하도록 하겠습니다.
学习爬虫之前你需要了解(个人建议,铁头娃可以无视): - **少许网页制作知识,起码要明白什么标签...** - **相关语言基础知识。比如用java做爬虫起码会用Java语言,用python做爬虫起码要会用python语言...** - **一些网络相关知识。比如TCP/IP、cookie之类的知识,明白网页打开的原理。** - **国家法律。知道哪些能爬,哪些不能爬,别瞎爬。**
제목에서 알 수 있듯이 이 문서의 모든 코드는 python3.6.X를 사용합니다.
먼저 설치해야 합니다(pip3 install xxxx 그러면 한 번의 클릭으로 괜찮습니다)
requests 모듈
BeautifulSoup 모듈(또는 lxml 모듈)
이 두 라이브러리는 매우 강력합니다. , 요청은 웹 페이지를 보내는 데 사용됩니다. 웹 페이지 요청 및 열기, beautifulsoup 및 lxml은 콘텐츠를 구문 분석하고 원하는 것을 추출하는 데 사용됩니다. BeautifulSoup은 정규식을 선호하고 lxml은 XPath를 선호합니다. 나는 beautifulsoup 라이브러리를 사용하는 데 더 익숙하기 때문에 이 기사에서는 lxml에 대해 너무 자세히 설명하지 않고 beautifulsoup 라이브러리를 주로 사용합니다. (사용하기 전에 문서를 읽는 것이 좋습니다)
크롤러의 주요 구조:
관리자: 크롤링하려는 주소를 관리합니다.
다운로더: 웹페이지 정보를 다운로드합니다.
필터: 다운로드한 웹페이지 정보에서 필요한 콘텐츠를 필터링합니다.
저장소: 다운로드한 항목을 저장하고 싶은 곳에 저장하세요. (실제 상황에 따라 선택사항입니다.)
기본적으로 제가 접한 모든 웹 크롤러는 sracpy부터 urllib까지 이 구조를 벗어날 수 없습니다. 이 구조만 알면 외울 필요가 없다. 글을 쓸 때 최소한 무엇을 쓰고 있는지 알 수 있고, 버그가 생겼을 때 어디에 디버그해야 할지 알 수 있다는 장점이 있다.
앞에 말도 안 되는 내용이 많아요... 본문은 다음과 같습니다.
이 글에서는 크롤링 https://baike.baidu.com/item/Python을 사용합니다(예로 Python의 Baidu 항목).
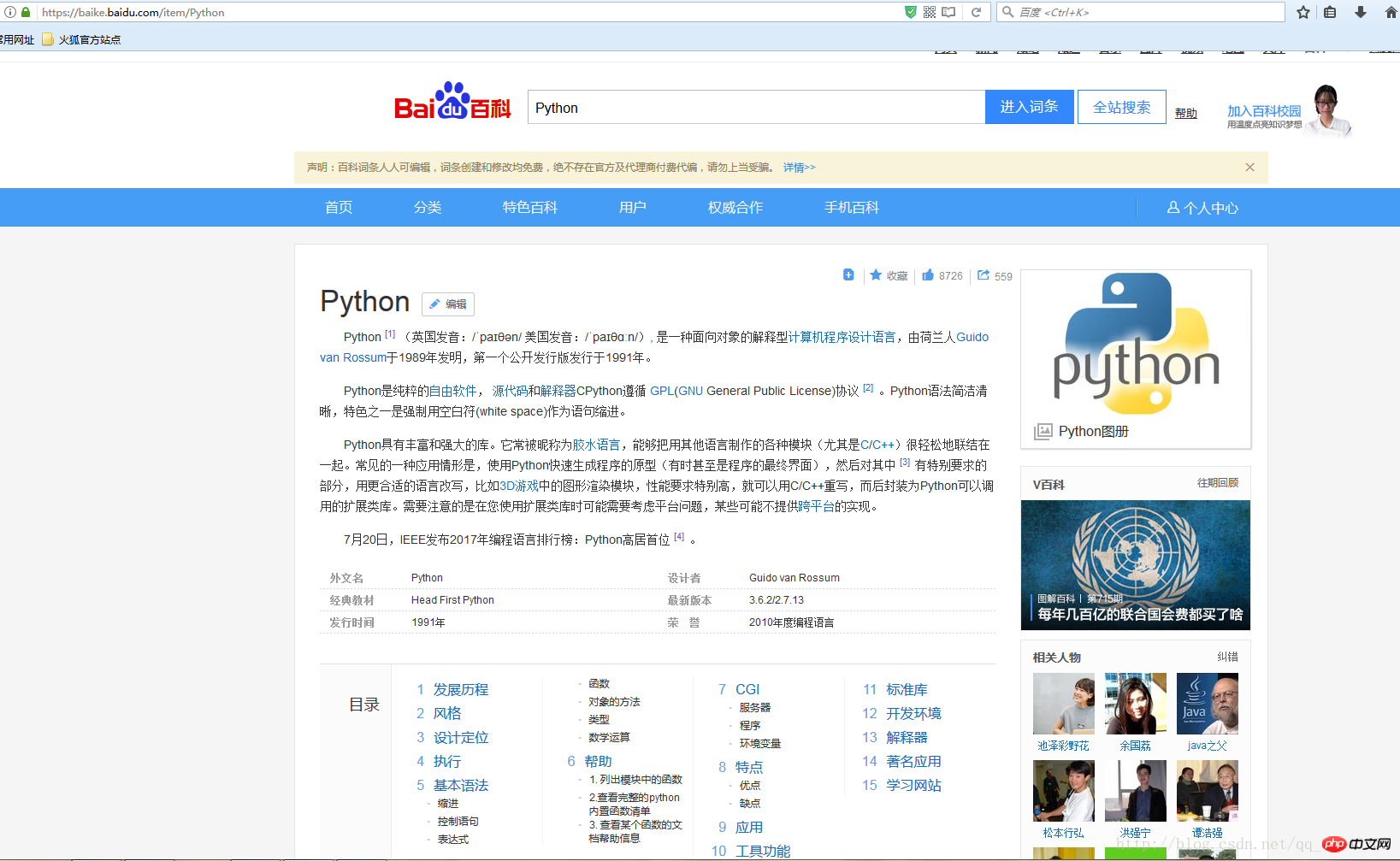
(스크린샷 찍는게 너무 번거로워서..이 글에 사진만 있을거에요)
파이썬 항목 내용을 크롤링하려면 우선 크롤링하려는 URL을 알아야 합니다. :
url = 'https://baike.baidu.com/item/Python'
이 페이지만 크롤링하면 되니까 관리자님은 괜찮습니다 .
html = request.urlopen(url)
urlopen() 함수를 호출하면 다운로더는 괜찮습니다
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary')Find_all 함수와 함께 Beautifulsoup 라이브러리의 beautifulsoup 함수를 사용하면 파서는 괜찮습니다.
여기서 find_all 함수의 반환 값은 다음과 같습니다. 목록. 따라서 출력은 루프로 인쇄되어야 합니다.
이 예제는 저장할 필요가 없으므로 직접 인쇄할 수 있으므로
for content in baike: print (content.get_text())
get_text()를 사용하여 라벨의 텍스트를 추출합니다.
위 코드 정리:
import requestsfrom bs4 import BeautifulSoupfrom urllib import requestimport reif __name__ == '__main__':
url = 'https://baike.baidu.com/item/Python'
html = request.urlopen(url)
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary') for content in baike: print (content.get_text())바이두 백과사전 항목이 나타납니다.
비슷한 방법으로 일부 소설, 사진, 헤드라인 등도 크롤링할 수 있으며 결코 항목에만 국한되지 않습니다.
이 기사를 마친 후 이 프로그램을 작성할 수 있다면 축하합니다. 시작하신 것입니다. 코드를 절대 외우지 마세요.
단계가 생략되었습니다...전체 과정이 좀 거칠네요...미안해요...빠졌네요( ̄ー ̄)...
위 내용은 Python3 기본 크롤러 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!