
Python에서 Numpy와 Pandas 사용 소개
- 巴扎黑원래의
- 2017-09-13 10:04:382888검색
최근에는 연이어 데이터를 비교해야 하는데, 계산을 위해 Numpy와 Pandas를 사용해야 합니다. 다음 글에서는 Python 학습 튜토리얼에서 Numpy와 Pandas 사용 관련 정보를 주로 소개합니다. . 기사에서는 예제 코드를 통해 자세히 소개하고 있으며, 필요한 친구들이 참고할 수 있습니다.
머리말
이 글은 주로 Python에서 Numpy와 Pandas의 사용에 대한 관련 정보를 소개하고 참고 및 학습을 위해 공유합니다. 아래에서는 자세히 설명하지 않겠습니다. 자세한 소개.
그들은 무엇인가요?
NumPy는 Python 언어용 확장 라이브러리입니다. 고급 및 대규모 차원 배열 및 행렬 연산을 지원하며 배열 연산을 위한 수많은 수학 함수 라이브러리도 제공합니다.
Pandas는 데이터 분석 작업을 해결하기 위해 만들어진 NumPy 기반 도구입니다. Pandas는 대규모 데이터 세트를 효율적으로 조작하는 데 필요한 도구를 제공하기 위해 여러 라이브러리와 일부 표준 데이터 모델을 통합합니다. Pandas는 데이터를 빠르고 쉽게 처리할 수 있는 다양한 기능과 방법을 제공합니다.
List, Numpy 및 Pandas
Numpy 및 List
는 동일합니다.
는 아래 첨자를 사용하여 모든 요소에 액세스할 수 있습니다. 예를 들어 a[0]
은 모두 액세스할 수 있습니다. 예를 들어, a[1:3]
은 for 루프를 사용하여 탐색할 수 있습니다
차이점:
-
Numpy의 각 요소 유형은 동일해야 하지만 여러 유형의 요소가 가능합니다.
Numpy는 평균, 표준, 합계, 최소, 최대 등과 같은 많은 기능을 캡슐화하여 사용하기 더 편리합니다.
Numpy는 다차원 배열이 될 수 있습니다.
Numpy C로 구현되었으며 작업이 더 빠릅니다
Pandas는 Numpy
와 동일합니다.
액세스 요소는 동일하며 아래 첨자를 사용할 수 있으며 슬라이스 액세스도 사용할 수 있습니다
For 루프를 사용하여 순회할 수 있습니다.
mean, std, sum, min, max 등과 같은 편리한 함수가 많이 있습니다.
벡터 연산을 수행할 수 있습니다
. 더 빠르게
차이점: Pandas에는 설명 기능과 같이 Numpy에 없는 몇 가지 메서드가 있습니다. 주요 차이점은 Numpy는 List의 향상된 버전과 같고 Pandas는 목록과 사전의 모음과 같으며 Pandas에는 색인이 있다는 것입니다.
Numpy 사용법
1. 기본 작업
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
#求标准差 print p1.std()
0.816496580928
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
2. 벡터 연산
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
3. 인덱스 배열
먼저 아래 그림을 보시면서 이해하시기 바랍니다
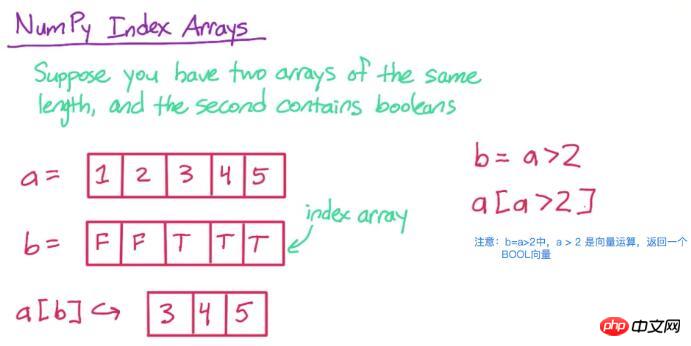
그럼 코드로 구현해 보겠습니다
a = np.array([1, 2, 3, 4, 5]) print a
[1 2 3 4 5]
b = a > 2 print b
[False False True True True]
print a[b]
a[b], a에서 해당 b 위치가 True인 요소만 유지됩니다
4.
먼저 일련의 연산을 살펴보겠습니다.[3 4 5]
a = np.array([1, 2, 3, 4]) b = a a += np.array([1, 1, 1, 1]) print b
[2 3 4 5]
a = np.array([1, 2, 3, 4]) b = a a = a + np.array([1, 1, 1, 1]) print b위 결과에서 볼 수 있듯이 +=는 원래 배열을 변경하지만 +는 변경하지 않습니다. 그 이유는 다음과 같습니다.
- +=: 내부 계산이므로 새 배열을 생성하지 않습니다. 원래 배열의 요소를 변경합니다.
- +: 내부 계산이며 새 배열을 생성합니다. 새로운 배열. 원래 배열의 요소는 Numpy의 슬라이스로 수정되지 않습니다 위에서 본 것처럼 List의 요소를 변경하면 원래 배열에 영향을 주지 않으며 Numpy가 조각의 요소를 변경하면 원래 배열도 변경됩니다. 이는 Numpy의 슬라이스 프로그래밍이 새 배열을 생성하지 않으며 해당 슬라이스를 수정하면 원래 배열 데이터도 변경되기 때문입니다. 이 메커니즘을 사용하면 Numpy를 기본 배열 작업보다 빠르게 만들 수 있지만 프로그래밍할 때는 주의를 기울여야 합니다. 6. 2차원 배열의 연산
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
위 내용은 Python에서 Numpy와 Pandas 사용 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!