
Java Virtual Machine의 재활용 메커니즘 연구
- 一个新手원래의
- 2017-09-07 15:38:411806검색
1: 개요
가비지 컬렉션(Garbage Collection, GC)에 대해 말하면 많은 사람들이 자연스럽게 Java와 연관시킬 것입니다. Java에서 프로그래머는 동적 메모리 할당 및 가비지 수집에 대해 걱정할 필요가 없습니다. 이름에서 알 수 있듯이 가비지 수집은 가비지가 차지하는 공간을 해제하는 것입니다. 이 모든 작업은 JVM에 맡겨집니다. 이 기사에서는 주로 다음 세 가지 질문에 답합니다.
1. 어떤 메모리를 재활용해야 합니까? (어떤 물건이 "쓰레기"로 간주될 수 있나요?)
2. 재활용하는 방법은 무엇인가요? (일반적으로 사용되는 가비지 수집 알고리즘)
3. 재활용에는 어떤 도구가 사용되나요? (가비지 수집기)
2. JVM 가비지 판별 알고리즘
일반적으로 사용되는 가비지 판별 알고리즘에는 참조 카운팅 알고리즘과 도달성 분석 알고리즘이 포함됩니다.
1. 참조 계산 알고리즘
Java는 참조를 통해 객체와 연결됩니다. 즉, 객체를 조작하려면 참조를 통해 수행해야 합니다. 참조 카운터를 개체에 추가합니다. 참조가 있을 때마다 카운터 값이 1씩 증가하고, 참조가 만료되면 카운터 값이 1씩 감소합니다. 더 이상, 즉 해당 개체가 재활용을 위해 "쓰레기"로 간주될 수 있음을 나타냅니다.
참조 카운터 알고리즘은 구현이 간단하고 효율성이 높지만 순환 참조 문제를 해결할 수 없습니다(객체 A는 객체 B를 참조하고 객체 A는 객체 A를 참조하지만 객체 A와 B는 더 이상 참조되지 않습니다). 다른 개체) 동시에 카운터의 증가 및 감소로 인해 추가 오버헤드가 많이 발생하므로 JDK1.1 이후에는 이 알고리즘이 더 이상 사용되지 않습니다. 코드:
public class Main {
public static void main(String[] args) {
MyTest test1 = new MyTest();
MyTest test2 = new MyTest();
test1.obj = test2;
test2.obj = test1;//test1与test2存在相互引用
test1 = null;
test2 = null;
System.gc();//回收
}
}
class MyTest{
public Object obj = null;
}test1과 test2에 최종적으로 null이 할당되었지만, 이는 test1과 test2가 가리키는 객체에 더 이상 접근할 수 없다는 뜻이지만, 서로를 참조하기 때문에 참조 횟수가 0이 아니므로 가비지입니다. . 수집가는 절대로 해당 항목을 회수하지 않습니다. 프로그램을 실행한 후 메모리 분석을 통해 이 두 객체의 메모리가 실제로 재활용된다는 것을 알 수 있습니다. 이는 또한 현재 주류 JVM이 참조 카운터 알고리즘을 가비지 결정 알고리즘으로 사용하지 않음을 보여줍니다.
2. 도달성 분석 알고리즘(루트 검색 알고리즘)
루트 검색 알고리즘은 일부 "GC Roots" 개체를 시작점으로 사용하여 이러한 노드에서 아래쪽으로 검색하며 검색을 통해 전달된 경로가 참조 체인이 됩니다
(참조 Chain) , 객체가 GC Roots의 참조 체인으로 연결되어 있지 않으면 해당 객체를 사용할 수 없음을 의미합니다.
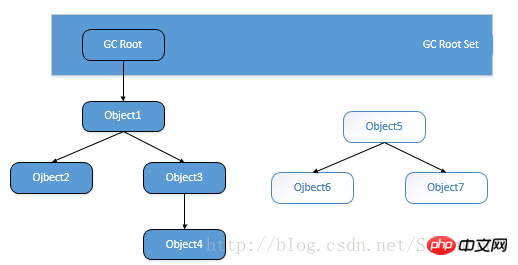
GC 루트 개체에는 다음이 포함됩니다.
a) 가상 머신 스택(스택 프레임의 로컬 변수 테이블)에서 참조되는 개체입니다.
b) 메소드 영역의 클래스 정적 속성이 참조하는 객체입니다.
c) 메서드 영역에서 상수가 참조하는 개체입니다.
d) 네이티브 메서드 스택에서 JNI(일반적으로 네이티브 메서드라고 함)가 참조하는 개체입니다.
도달 가능성 분석 알고리즘에서 도달할 수 없는 객체는 현재로서는 일시적으로 "일시 중지" 단계에 있습니다. 객체가 실제로 소멸되었다고 선언하려면 최소한 두 가지 표시 프로세스를 거쳐야 합니다. 도달성 분석 후 객체가 GC 루트에 연결된 참조 체인이 없다는 것을 발견하면 처음으로 표시되고 한 번 필터링됩니다. 필터링 조건은 객체가 finalize() 메서드를 실행해야 하는지 여부입니다. 개체가 finalize() 메서드를 포함하지 않거나 finalize() 메서드가 가상 머신에 의해 호출된 경우 가상 머신은 두 상황을 모두 "실행할 필요 없음"으로 처리합니다. 객체의 finalize() 메서드는 시스템에 의해 자동으로 한 번만 실행된다는 점에 유의하세요.
이 개체가 finalize() 메서드를 실행해야 한다고 결정되면 이 개체는 F-Queue라는 대기열에 배치되고 나중에 실행할 가상 머신 스레드에 의해 우선 순위가 낮은 Finalizer에 의해 자동으로 생성됩니다. 그것. 여기서 소위 "실행"이란 가상 머신이 이 메소드를 트리거하지만 실행이 완료될 때까지 기다리지 않는다는 것을 의미합니다. 그 이유는 객체가 finalize() 메소드에서 느리게 실행되거나 무한대로 실행되기 때문입니다. 루프가 발생하면 F-Queue 대기열의 다른 개체가 영구적으로 대기하거나 전체 메모리 재활용 시스템이 중단될 수도 있습니다. 따라서 finalize() 메서드를 호출한다고 해서 이 메서드의 코드가 완전히 실행될 수 있다는 의미는 아닙니다.
finalize() 메서드는 객체가 죽음의 운명에서 벗어날 수 있는 마지막 기회입니다. 객체가 finalize에서 성공적으로 저장되기를 원하는 경우 GC는 F-Queue에 객체를 표시합니다. () - 참조 체인의 개체와의 연결을 다시 설정하기만 하면 됩니다. 예를 들어 자신(이 키워드)을 개체의 클래스 변수 또는 멤버 변수에 할당하면 "정보"에서 제거됩니다. 두 번째로 표시되면 재활용됩니다. "컬렉션, 개체가 이 시점에서 이스케이프되지 않은 경우 기본적으로 실제로 재활용됩니다. 다음 코드에서 객체의 finalize()가 실행되지만 여전히 유지될 수 있음을 볼 수 있습니다.
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finalize()方法最多只会被系统自动调用一次
*/ public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, i am still alive :)");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
}
}실행 결과:
finalize mehtod executed! yes, i am still alive :) no, i am dead :(
从运行结果可以看出,SAVE_HOOK对象的finalize()方法确实被GC收集器调用过,且在被收集前成功逃脱了。
另外一个值得注意的地方是,代码中有两段完全一样的代码片段,执行结果却是一次逃脱成功,一次失败,这是因为任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行,因此第二段代码的自救行动失败了。
三、JVM垃圾回收算法
常用的垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法
1、标记—清除算法(Mark-Sweep)(DVM 使用的算法)
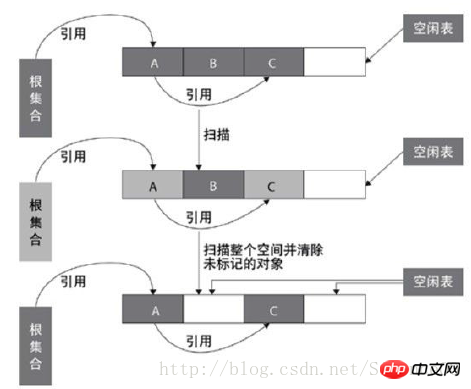
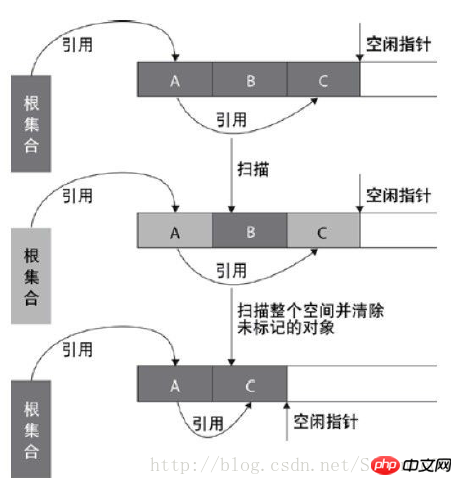
标记—清除算法包括两个阶段:“标记”和“清除”。在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。
2、复制算法(Copying)
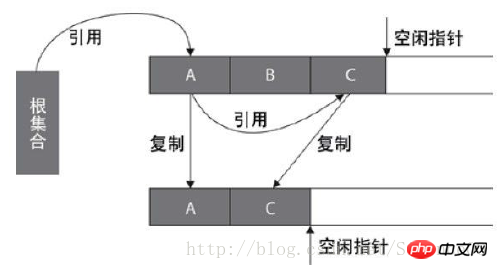
复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM 用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
3、标记—整理算法(Mark-Compact)
标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
4、分代收集(Generational Collection)
分代收集是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
四、垃圾收集器
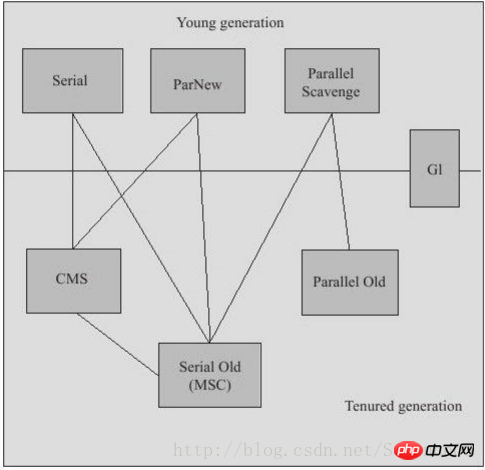
如果说垃圾收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。上面说过,各个平台虚拟机对内存的操作各不相同,因此本章所讲的收集器是基于JDK1.7Update14之后的HotSpot虚拟机。这个虚拟机包含的所有收集器如图:
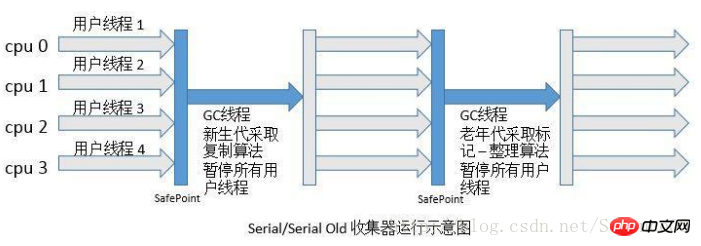
1、Serial收集器
Serial收集器是最基本、发展历史最悠久的收集器,曾经(在JDK 1.3.1之前)是虚拟机
新生代收集的唯一选择。大家看名字就会知道,这个收集器是一个单线程的收集器,但它
的“单线程”的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,
更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
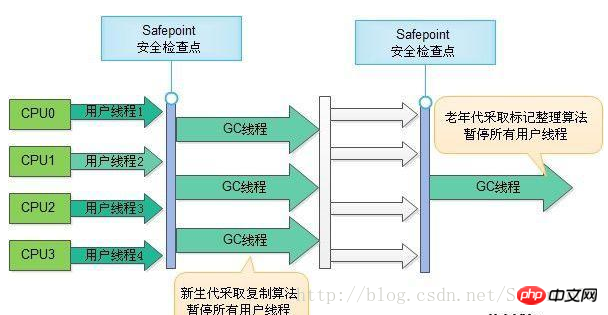
2、ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之
外,其余行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX:
PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对
象分配规则、回收策略等都与Serial收集器完全一样,在实现上,这两种收集器也共用了相
当多的代码。
3. 병렬 Scavenge Collector
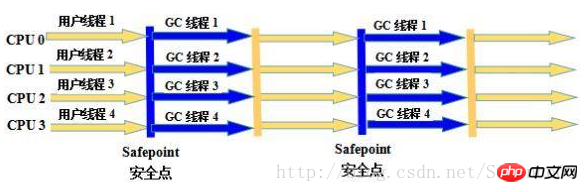
Parallel Scavenge Collector의 특징은 다른 수집기와는 달리 제어 가능한 처리량(처리량)을 달성하는 것입니다. 소위 처리량은 CPU가 사용자 코드를 실행하는 데 소비한 시간과 소비된 총 CPU 시간의 비율입니다. 즉, 처리량 = 사용자 코드 실행 시간/(사용자 코드 실행 시간 + 가비지 수집 시간)입니다. 처리량과 밀접한 관계로 인해 병렬 Scavenge 수집기는 종종 "처리량 우선" 수집기라고도 합니다.
4. Serial Old 컬렉터
Serial Old는 Serial 컬렉터의 구세대 버전이기도 하며 "mark-sort" 알고리즘을 사용합니다. 이 수집기의 주요 의미는 클라이언트 모드의 가상 머신에서도 사용된다는 것입니다. 서버 모드인 경우 두 가지 주요 용도가 있습니다. 하나는 JDK 1.5 및 이전 버전[1]의 병렬 Scavenge 수집기와 함께 사용되는 것이고, 다른 하나는 CMS 수집기에 대한 백업 계획으로 사용되는 것입니다. 동시 수집에서 ConcurrentMode 실패가 발생할 때 사용됩니다.
5. Parallel Old 컬렉터
Parallel Old는 멀티 스레딩 및 "마크 정렬" 알고리즘을 사용하는 Parallel Scavenge 컬렉터의 구세대 버전입니다.
이 컬렉터는 JDK 1.6에서만 제공되었습니다.
6. CMS 수집기
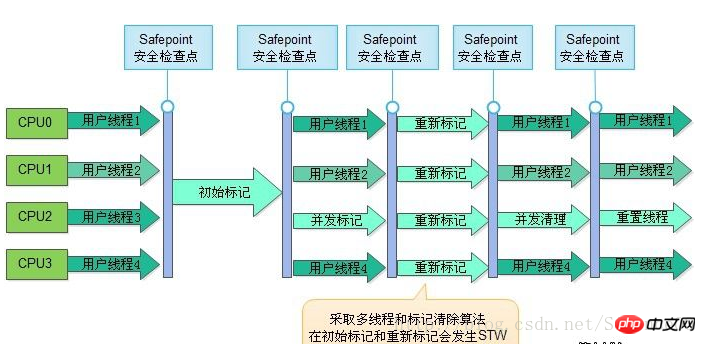
CMS(Concurrent Mark Sweep) 수집기는 가장 짧은 재활용 휴지 시간을 얻는 것을 목표로 하는 수집기입니다. 현재 Java 애플리케이션의 대부분은 인터넷 웹사이트나 B/S 시스템의 서버에 집중되어 있습니다. 이러한 애플리케이션은 서비스의 응답 속도에 특히 주의를 기울이고 있으며, 시스템 정지 시간을 최대한 단축하여 사용자에게 제공할 수 있기를 바랍니다. 더 나은 경험.
작업 프로세스는 다음을 포함하여 4단계로 나뉩니다.
a) 초기 표시(CMS 초기 표시)
b) 동시 표시(CMS 동시 표시)
c) 비고(CMS 설명)
d) 동시 스윕(CMS 동시 스윕)
CMS 수집기에는 세 가지 단점이 있습니다.
1 CPU 리소스에 민감합니다. 일반적으로 동시에 실행되는 프로그램은 CPU 수에 민감합니다.
2 떠다니는 쓰레기를 처리할 수 없습니다. 동시 정리 단계에서는 사용자 스레드가 계속 실행 중이므로 이때 생성된 가비지를 정리할 수 없습니다.
3 마크 스윕 알고리즘으로 인해 대량의 공간 조각화가 발생합니다.
7. G1 수집기
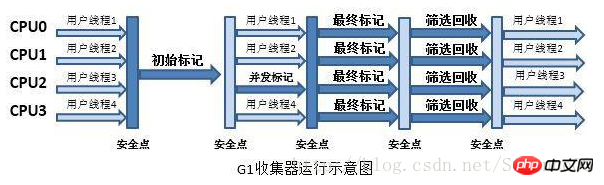
G1은 서버 측 애플리케이션용 가비지 수집기입니다.
G1 수집기의 작동은 대략 다음과 같은 단계로 나눌 수 있습니다.
a) 초기 마킹(Initial Marking)
b) 동시 마킹(Concurrent Marking)
c) 최종 마킹(Final Marking)
d) 선별 및 재활용 (라이브) 데이터 집계 및 대피)
위 내용은 Java Virtual Machine의 재활용 메커니즘 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!