
Python 설계 계산기 기능 구현의 전체 예제 공유

- 黄舟원래의
- 2017-08-20 10:53:124025검색
이 글에서는 Python에서 설계하고 구현한 계산기 기능을 주로 소개하고, Python3.5의 정규 연산, 문자열 연산, 수치 연산 및 기타 관련 연산 기법을 분석하여 계산기 기능을 완전한 예제 형식으로 구현했습니다. to this article
예제에서는 Python으로 설계하고 구현한 계산기 기능을 설명합니다. 참조를 위해 모든 사람과 공유하세요. 세부 사항은 다음과 같습니다.
PYTHON을 사용하여 다음과 같은 계산기 기능을 설계하고 처리합니다.
1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/(16-3*2))
나의 기본 아이디어 계산 처리는 다음과 같습니다.
문제 해결 아이디어는 내부 괄호 연산을 먼저 처리해야 한다는 것입니다 - 외부 괄호 연산 - 곱셈과 나눗셈 먼저, 덧셈과 뺄셈의 원리:
1. 사용자가 입력한 문자열을 보고 계산식에 괄호가 있는지 판단합니다. 가능하면 먼저 계산식을 정규화하고 먼저 가장 안쪽 레이어의 각 데이터를 얻은 다음 하나씩 계산합니다.
규칙성
inner = re.search("\([^()]*\)", calc_input)2. 괄호 안의 계산식을 변경합니다. 계산된 결과는 원래 초기 수식의 위치를 대체합니다. 반복 연산자는 계산 전에 별도로 처리됩니다.
def del_double(str):
str = str.replace("++", "+")
str = str.replace("--", "-")
str = str.replace("+-","-")
str = str.replace("- -","-")
str = str.replace("+ +","+")
return str3. 그런 다음 안쪽에서 바깥쪽으로 괄호를 제거하고 위치 바꾸기를 수행합니다
calc_input = calc_input.replace(inner.group(), str(ret))
계산된 결과를 원래 계산식으로 바꿉니다
4. 괄호 없이 얻어지고 계산 제어 기능이 결합되어 계산을 위해 호출됩니다. 중간에 주목해야 할 것은 음수와 숫자 및 *를 함께 처리하면 나머지는 꽤 좋습니다.
특정 논리 다이어그램은 다음과 같습니다.
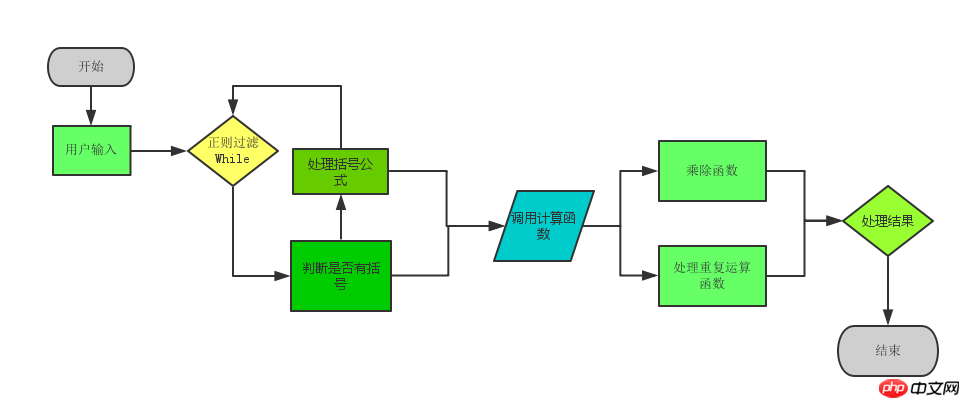 다음은 전체 코드입니다.
다음은 전체 코드입니다.
#!/usr/bin/env python3.5
# -*-coding:utf8-*-
import re
a =r'1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/(16-3*2))'
# */运算函数
def shengchu(str):
calc = re.split("[*/]",str) #用*/分割公式
OP = re.findall("[*/]",str) #找出所有*和/号
ret = None
for index,i in enumerate(calc):
if ret:
if OP[index-1] == "*":
ret *= float(i)
elif OP[index-1] == "/":
ret /= float(i)
else:
ret = float(i)
return ret
# 去掉重复运算,和处理特列+-符号
def del_double(str):
str = str.replace("++", "+")
str = str.replace("--", "-")
str = str.replace("+-","-")
str = str.replace("- -","-")
str = str.replace("+ +","+")
return str
# 计算主控制函数
def calc_contrl(str):
tag = False
str = str.strip("()") # 去掉最外面的括号
str = del_double(str) # 调用函数处理重复运算
find_ = re.findall("[+-]",str) # 获取所有+- 操作符
split_ = re.split("[+-]",str) #正则处理 以+-操作符进行分割,分割后 只剩*/运算符
if len(split_[0].strip()) == 0: # 特殊处理
split_[1] = find_[0] + split_[1] # 处理第一个数字前有“-”的情况,得到新的带符号的数字
# 处理第一个数字前为负数“-",时的情况,可能后面的操作符为“-”则进行标记
if len(split_) == 3 and len(find_) ==2:
tag =True
del split_[0] # 删除原分割数字
del find_[0]
else:
del split_[0] # 删除原分割数字
del find_[0] # 删除原分割运算符
for index, i in enumerate(split_):
# 去除以*或/结尾的运算数字
if i.endswith("* ") or i.endswith("/ "):
split_[index] = split_[index] + find_[index] + split_[index+1]
del split_[index+1]
del find_[index]
for index, i in enumerate(split_):
if re.search("[*/]",i): # 先计算含*/的公式
sub_res = shengchu(i) #调用剩除函数
split_[index] = sub_res
# 再计算加减
res = None
for index, i in enumerate(split_):
if res:
if find_[index-1] == "+":
res += float(i)
elif find_[index-1] == "-":
# 如果是两个负数相减则将其相加,否则相减
if tag == True:
res += float(i)
else:
res -= float(i)
else:
# 处理没有括号时会出现i 为空的情况
if i != "":
res = float(i)
return res
if __name__ == '__main__':
calc_input = input("请输入计算公式,默认为:%s:" %a).strip()
try:
if len(calc_input) ==0:
calc_input = a
calc_input = r'%s'%calc_input # 做特殊处理,保持字符原形
flag = True # 初始化标志位
result = None # 初始化计算结果
# 循环处理去括号
while flag:
inner = re.search("\([^()]*\)", calc_input)# 先获取最里层括号内的单一内容
#print(inner.group())
# 有括号时计算
if inner:
ret = calc_contrl(inner.group()) # 调用计算控制函数
calc_input = calc_input.replace(inner.group(), str(ret)) # 将运算结果,替换原处理索引值处对应的字符串
print("处理括号内的运算[%s]结果是:%s" % (inner.group(),str(ret)))
#flag = True
# 没有括号时计算
else:
ret = calc_contrl(calc_input)
print("最终计算结果为:%s"% ret)
#结束计算标志
flag = False
except:
print("你输入的公式有误请重新输入!")보충:
PYTHON 정규식 개요:
패턴
설명
^
문자열의 시작과 일치합니다.
$
문자열의 끝과 일치합니다.
.
은 개행 문자를 제외한 모든 문자와 일치합니다. re.DOTALL 플래그가 지정되면 개행 문자를 포함한 모든 문자와 일치할 수 있습니다.
[...]
은 별도로 나열된 문자 그룹을 나타내는 데 사용됩니다. [amk]는 'a', 'm' 또는 'k
[^...]
과 일치합니다. not in [ 문자 ]: [^abc]는 a, b, c를 제외한 문자와 일치합니다.
re*
은 0개 이상의 표현식과 일치합니다.
re+
은 1개 이상의 표현식과 일치합니다.
re?
탐욕스럽지 않은 방식으로 이전 정규식으로 정의된 0 또는 1개의 조각과 일치합니다.
re{n}
re{n,}
정확히 이전 n개와 일치합니다. 표현.
re{ n, m}
는 이전 정규식으로 정의된 조각의 n ~ m 배와 일치합니다. 욕심 많은 방식으로
a | b
는 a 또는 b
(re) G는 괄호 안의 표현식과 일치하며 그룹
(?imx)
을 나타냅니다. 정규식에는 i, m 또는 x의 세 가지 선택적 플래그가 포함되어 있습니다. 괄호 안의 영역에만 영향을 미칩니다.
(?-imx)
i, m 또는 x 선택적 플래그를 끄는 정규식입니다. 괄호 안의 영역에만 영향을 미칩니다.
(?: re)
(...)과 유사하지만 그룹을 나타내지는 않습니다.
(?imx: re)
괄호 안에 i, m 또는 x 선택적 플래그 사용
(?-imx: re)
괄호 안에 i, m 또는 x 선택적 플래그를 사용하지 마세요.
(?#...)
Comments.
(?= re) 앞으로 양수 구분 기호. ... 로 표시된 포함된 정규식이 현재 위치와 성공적으로 일치하면 성공하고, 그렇지 않으면 실패합니다. 그러나 포함된 표현식을 시도한 후에는 일치 엔진이 전혀 개선되지 않으며 패턴의 나머지 부분은 여전히 구분 기호의 오른쪽을 시도해야 합니다.
(?! re)
앞으로 음수 구분 기호를 사용하세요. 양수 구분 기호와 달리 포함된 표현식이 문자열의 현재 위치에서 일치할 수 없으면 성공합니다.
(?> re)
독립적인 패턴이 일치하므로 역추적할 필요가 없습니다.
w
영숫자와 일치
W
영숫자가 아닌 문자와 일치
s
모든 공백 문자와 일치하며, [tnrf]와 동일합니다.
S 비어 있는 항목과 일치합니다. 문자
d
는 [0-9]에 해당하는 모든 숫자와 일치합니다.
D
은 숫자가 아닌 모든 숫자와 일치합니다.
A
문자열의 시작과 일치합니다
Z 문자열의 끝과 일치합니다. 줄바꿈이 있는 경우 줄바꿈 이전의 문자열 끝만 일치합니다. c
z
는 문자열
G
의 끝과 일치하며 마지막 일치가 완료된 위치와 일치합니다.
b
은 단어와 공백 사이의 위치를 나타내는 단어 경계와 일치합니다. 예를 들어, 'erb'는 "never"의 'er'와 일치하지만 "동사"의 'er'와는 일치하지 않습니다.
B
단어가 아닌 경계와 일치합니다. 'erB'는 "동사"의 'er'와 일치하지만 "never"에서는 일치하지 않습니다.
n, t 등
은 개행 문자와 일치합니다. 탭 문자와 일치합니다. 등.
1...9
은 n번째 그룹의 하위 표현식과 일치합니다.
10
일치하는 경우 n번째 그룹의 하위 표현식과 일치합니다. 그렇지 않으면 8진수 문자 코드의 표현을 참조합니다.
위 내용은 Python 설계 계산기 기능 구현의 전체 예제 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!