
Python 크롤링 기사 예제 튜토리얼
- 巴扎黑원래의
- 2017-08-07 17:37:451908검색
이 기사는 주로 Python을 사용하여 산문 웹사이트에서 기사를 크롤링하는 관련 정보를 소개합니다. 기사의 소개는 매우 자세하며 필요한 모든 사람을 위한 특정 참고 자료와 학습 가치가 있습니다.
이 기사는 주로 Python 크롤링 산문 네트워크 기사에 대한 관련 내용을 소개합니다. 자세한 소개를 살펴보겠습니다.
렌더링은 다음과 같습니다.

python 2.7 구성
bs4 requests
설치 pip를 사용하여 sudo pip install bs4 설치sudo pip install bs4
sudo pip install requests
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。
内容是:
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
然后test.py的代码为:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来
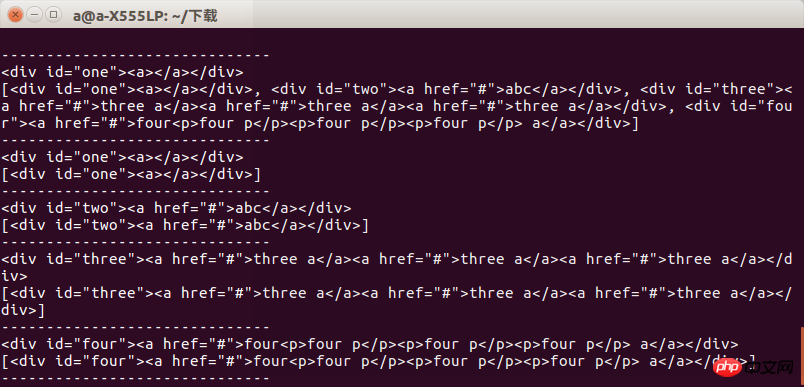
所以我们在使用时候要注意到底要的是什么,否则会出现报错
接下来就是通过requests 获取网页信息了,我不太懂别人为什么要写heard跟其他的东西
我直接进行网页访问,通过get方式获取散文网几个分类的二级网页然后通过一个组的测试,把所有的网页爬取一遍
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=i这部分的代码中我没有对res.status_code
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
bs4 사용에 대한 간략한 설명입니다. find_all
find와 find_all의 차이점은 반환되는 내용이 다르다는 것입니다. find는 일치하는 첫 번째 태그를 반환하고 태그의 내용은
find_all이 목록을 반환합니다
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
test.py의 코드는
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
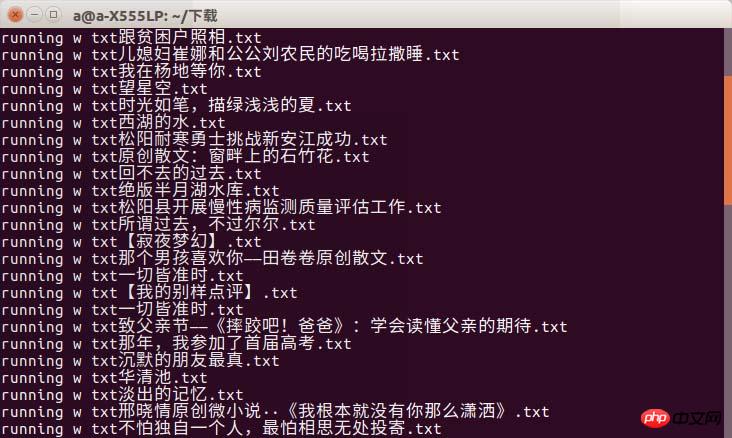
실행 후 지정된 태그를 가져오면 결과를 볼 수 있습니다. 두 태그를 가져오면 두 태그의 차이점이 표시됩니다

그래서 사용할 때 필요한 것에 주의를 기울여야 합니다. 그렇지 않으면 오류가 발생합니다
 다음 단계는 요청을 통해 웹페이지 정보를 얻는 것입니다. 다른 사람들이 왜 들었는지 그리고 다른 것들을 쓰는지 잘 이해합니다
다음 단계는 요청을 통해 웹페이지 정보를 얻는 것입니다. 다른 사람들이 왜 들었는지 그리고 다른 것들을 쓰는지 잘 이해합니다
직접 진행하겠습니다. 웹 페이지 액세스의 경우 get 메소드를 사용하여 prose.com에서 여러 카테고리의 보조 웹 페이지를 얻은 다음 그룹 테스트를 통과하여 모든 웹 페이지를 크롤링합니다
🎜🎜🎜f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()🎜이 부분의 코드에서는
res.status_code를 수정하지 않았습니다. 200이 아닌 경우 오류가 표시되지 않고 크롤링된 콘텐츠가 손실된다는 문제가 있습니다. 그러다가 Sanwen.net/rizhi/&p=1🎜🎜🎜웹페이지를 분석했는데 p의 최대값은 10입니다. 이해가 안 되네요. 지난번에 디스크를 크롤링했을 때 100페이지였네요. 나중에요. 그런 다음 get 메소드를 통해 각 페이지의 내용을 가져옵니다. 🎜🎜🎜각 페이지의 내용을 가져온 후 작성자와 제목을 분석합니다. 🎜🎜🎜🎜rrreee🎜 제목을 가져올 때 문제가 있습니다. 글을 쓸 때 제목에 슬래시를 추가하는 이유는 무엇입니까? 한개도 아니고 2개가 더 있습니다. 나중에 파일을 작성할 때 이 문제로 인해 파일명이 틀리게 되어 정규식을 작성해 드렸습니다. 🎜🎜🎜마지막 단계는 각 페이지 분석을 통해 글 주소를 얻은 뒤, 원래는 웹페이지 주소를 변경해서 하나씩 직접 얻고 싶었는데, 문제를 해결합니다. 🎜🎜🎜🎜rrreee🎜마지막으로 파일을 작성하고 저장하면 ok🎜🎜🎜🎜rrreee🎜산문 네트워크에서 산문을 가져오는 기능이 3가지인데, 문제는 제가 모른다는 것입니다. 왜 일부 산문이 손실되었는지. 기사는 400개 정도만 얻을 수 있습니다. 이 기사는 Prose.com의 기사와 많이 다르지만 실제로는 페이지 단위로 얻을 수 있습니다. 물론 웹 페이지를 접속할 수 없게 만들어야 할 것 같아요🎜🎜🎜🎜rrreee🎜렌더링을 깜빡할 뻔했어요🎜🎜🎜🎜🎜🎜타임아웃 현상이 생길 수도 있겠네요. .. 대학에 가면 반드시 일어날 것이라고 말할 수 있습니다. 좋은 네트워크를 선택하십시오! 🎜위 내용은 Python 크롤링 기사 예제 튜토리얼의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!