
Java 프레임워크 사용법 소개
- 巴扎黑원래의
- 2017-07-18 15:45:503237검색
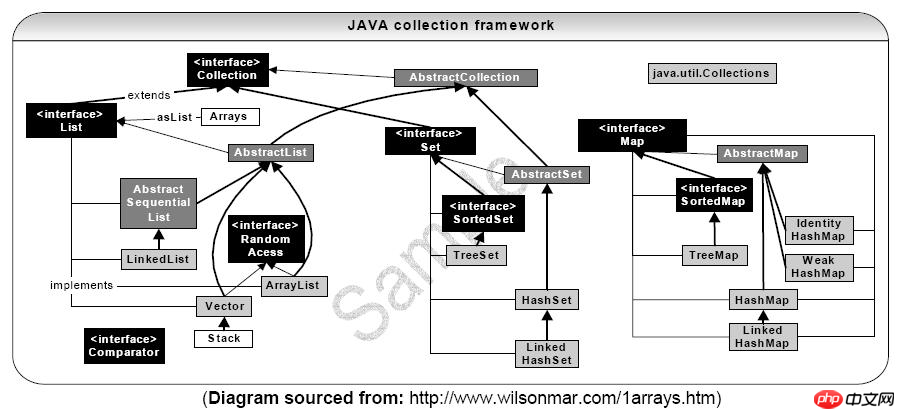
Collection 인터페이스
Collection은 가장 기본적인 컬렉션 인터페이스입니다. 컬렉션은 개체 집합, 즉 컬렉션의 요소를 나타냅니다.
Collection 인터페이스를 구현하는 모든 클래스는 두 개의 표준 생성자를 제공해야 합니다. 매개 변수가 없는 생성자는 빈 컬렉션을 만드는 데 사용되고, Collection 매개 변수가 있는 생성자는 새 컬렉션을 만드는 데 사용됩니다. 요소를 전달된 컬렉션으로 사용합니다. 후자의 생성자를 사용하면 사용자가 컬렉션을 복사할 수 있습니다.
컬렉션의 각 요소를 어떻게 탐색하나요? Collection의 실제 유형에 관계없이 반복자를 반환하는 iterator() 메서드를 지원합니다. 이 반복자를 사용하여 컬렉션의 각 요소를 순회하고 액세스할 수 있습니다. Iterator를 통한 순회는 순서가 없습니다.
일반적인 사용법은 다음과 같습니다:
1 Iterator it = collection.iterator(); // 获得一个迭代子2 while(it.hasNext()) {3 Object obj = it.next(); // 得到下一个元素4 }List 인터페이스
List는 순서가 지정된 컬렉션입니다 이 인터페이스를 사용하면 각 요소의 삽입 위치를 정밀하게 제어할 수 있습니다. 사용자는 Java 배열과 유사한 인덱스(배열 첨자와 유사한 목록의 요소 위치)를 사용하여 목록의 요소에 액세스할 수 있습니다.
List는 Collection 인터페이스에 필요한 iterator() 메서드 외에도 ListIterator 인터페이스를 반환하는 listIterator() 메서드도 제공합니다. 이는 표준 Iterator 인터페이스와 비교할 때 ListIterator에는 add()와 같은 몇 가지 메서드가 더 있습니다. , 요소 추가, 삭제, 설정 및 앞으로 또는 뒤로 이동이 가능합니다.
List 인터페이스를 구현하는 일반적인 클래스는 LinkedList, ArrayList, Vector 및 Stack입니다.
LinkedList 클래스
LinkedList는 null 요소를 허용하는 List 인터페이스를 구현합니다. 또한 LinkedList는 추가 가져오기, 제거 및 삽입 메서드를 제공합니다. 이러한 작업을 통해 LinkedList를 스택, 큐 또는 데크로 사용할 수 있습니다.
LinkedList에는 동시성이 없습니다. 여러 스레드가 동시에 LinkedList에 액세스하는 경우 액세스 동기화를 직접 구현해야 합니다. 또 다른 해결책은 목록을 생성할 때 동기화된 목록을 구성하는 것입니다. List list = Collections.synchronizedList(new LinkedList(...));
ArrayList class
ArrayList는 가변 크기 배열을 구현합니다. null을 포함한 모든 요소를 허용합니다. ArrayList에는 동시성이 없습니다.
size, isEmpty, get, set 메소드 실행 시간은 일정합니다. 그러나 add 메서드의 비용은 상각 상수이며, n 요소를 추가하려면 O(n) 시간이 필요합니다. 다른 방법에는 선형 실행 시간이 있습니다.
각 ArrayList 인스턴스에는 요소를 저장하는 데 사용되는 배열의 크기인 용량(Capacity)이 있습니다. 이 용량은 새 요소가 추가됨에 따라 자동으로 증가하지만 증가 알고리즘은 정의되지 않습니다. 많은 수의 요소를 삽입해야 하는 경우 삽입 전에 verifyCapacity 메소드를 호출하여 ArrayList의 용량을 늘려 삽입 효율성을 높일 수 있습니다.
Vector 클래스
Vector는 ArrayList와 매우 유사하지만 Vector는 동기화됩니다. Vector에 의해 생성된 Iterator는 ArrayList에 의해 생성된 Iterator와 동일한 인터페이스를 가지지만 Vector는 동기화되기 때문에 Iterator가 생성되어 사용 중일 때 다른 스레드가 Vector의 상태를 변경합니다(예: 일부 요소 추가 또는 제거). , Iterator 메서드를 호출하면 ConcurrentModificationException이 발생하므로 예외를 catch해야 합니다.
Stack 클래스
Stack은 Vector에서 상속받고 후입선출 스택을 구현합니다. Stack은 Vector를 스택으로 사용할 수 있는 5가지 추가 메서드를 제공합니다. 기본적인 push, pop 메소드와 peek 메소드는 스택의 맨 위에 요소를 가져오고,empty 메소드는 스택이 비어 있는지 테스트하며, search 메소드는 스택에서 요소의 위치를 감지합니다. 스택은 생성된 후 빈 스택입니다.
Vector, ArrayList 및 LinkedList 비교
1. Vector는 스레드 동기화되므로 스레드로부터 안전하지만 ArrayList 및 LinkedList는 스레드로부터 안전하지 않습니다. 스레드 안전 요소를 고려하지 않는 경우 일반적으로 ArrayList 및 LinkedList를 사용하는 것이 더 효율적입니다.
2.ArrayList와 Vector는 동적 배열을 기반으로 데이터 구조를 구현하고 LinkedList는 연결 목록 데이터 구조를 기반으로 합니다.
3. 컬렉션의 요소 수가 현재 컬렉션 배열의 길이보다 큰 경우 Vector의 증가율은 현재 배열 길이의 100%이고 ArrayList의 증가율은 50%입니다. 현재 배열 길이 데이터가 컬렉션에 사용되는 경우 상대적으로 많은 양의 데이터의 경우 벡터를 사용하면 반대로 ArrayList를 사용하면 이점이 있습니다.
3. 특정 위치에서 데이터를 찾으면 Vector와 ArrayList는 O(1)의 동일한 시간을 사용하는 반면 LinkedList는 순회 검색이 필요하므로 O(i) 시간이 소요되므로 효율적이지 않습니다. 처음 두 개.
4. 그리고 지정된 위치의 데이터를 이동하고 삭제하는데 걸리는 시간이 전체 길이가 0(n-i)n이라면 이동하는 데 30초가 걸리므로 이때 LinkedList를 사용하는 것을 고려해야 합니다. 지정된 위치의 데이터는 0(1)입니다.
5. 데이터를 지정된 위치에 삽입하려면 ArrayList가 데이터를 이동해야 하기 때문에 LinedList가 유리합니다.
Set 인터페이스
Set은 중복 요소를 포함하지 않는 컬렉션입니다. 즉, 두 요소 e1과 e2는 e1.equals(e2)=false를 가지며 Set은 최대 하나를 갖습니다. 널 요소.
분명히 Set 생성자에는 전달된 Collection 매개 변수가 중복 요소를 포함할 수 없다는 제약 조건이 있습니다.
참고: 변경 가능한 객체는 주의해서 다뤄야 합니다. Set의 변경 가능한 요소가 상태를 변경하여 Object.equals(Object)=true가 되면 몇 가지 문제가 발생합니다.
Map 인터페이스
Map은 Collection 인터페이스를 상속하지 않으며 Map은 값 매핑에 키를 제공한다는 점에 유의하세요. Map은 동일한 키를 포함할 수 없으며 각 키는 하나의 값에만 매핑될 수 있습니다.
맵 인터페이스는 세 가지 종류의 세트 뷰를 제공합니다. 맵의 콘텐츠는 키 세트 세트, 값 세트 세트 또는 키-값 매핑 세트로 간주될 수 있습니다.
Hashtable 클래스
Hashtable은 Map 인터페이스를 상속하고 키-값 매핑의 해시 테이블을 구현합니다. null이 아닌 모든 객체를 키 또는 값으로 사용할 수 있습니다.
데이터를 추가하려면 put(key, value)을 사용하고, 데이터를 제거하려면 get(key)을 사용하세요. 이 두 가지 기본 작업의 시간 비용은 일정합니다.
Hashtable은 초기 용량과 부하율이라는 두 가지 매개변수를 통해 성능을 조정합니다. 일반적으로 기본 부하 계수 0.75는 시간과 공간 간의 균형을 더 잘 유지합니다. 로드 비율을 높이면 공간을 절약할 수 있지만 해당 검색 시간이 늘어나 가져오기 및 넣기와 같은 작업에 영향을 미칩니다.
키로 사용되는 개체는 해시 함수를 계산하여 해당 값의 위치를 결정하므로 키로 사용되는 모든 개체는 hashCode 및 equals 메서드를 구현해야 합니다. hashCode 및 equals 메소드는 루트 클래스 Object에서 상속됩니다.
해시테이블은 동기식입니다.
HashMap 클래스
HashMap은 HashMap이 비동기식이며 null, 즉 null 값과 null 키를 허용한다는 점을 제외하면 Hashtable과 유사합니다. 그러나 HashMap을 컬렉션으로 처리할 때(values() 메서드는 컬렉션을 반환할 수 있음) 반복 하위 작업의 시간 오버헤드는 HashMap의 용량에 비례합니다. 따라서 반복 연산의 성능이 매우 중요하다면 HashMap의 초기 용량을 너무 높게 설정하거나 부하율을 너무 낮게 설정하지 마십시오.
TreeMap 클래스
HashMap은 해시코드를 사용하여 순서가 지정되지 않은 콘텐츠를 빠르게 검색하는 반면, TreeMap의 모든 요소는 특정 고정 순서를 유지하고 순서가 지정됩니다.
Map에서 요소를 삽입, 삭제 및 찾으려면 HashMap이 최선의 선택입니다. 그러나 자연 순서나 사용자 정의 순서로 키를 반복하려면 TreeMap이 더 좋습니다. HashMap을 사용하려면 추가된 키 클래스가 hashCode() 및 equals() 구현을 명확하게 정의해야 합니다.
TreeMap에는 트리가 항상 균형 잡힌 상태이기 때문에 튜닝 옵션이 없습니다.
WeakHashMap 클래스
WeakHashMap은 키에 대한 "약한 참조"를 구현하는 향상된 HashMap입니다. 키가 더 이상 외부에서 참조되지 않으면 해당 키는 GC에서 재활용될 수 있습니다.
요약
스택, 큐 등과 관련된 작업이 포함된 경우 요소의 빠른 삽입 및 삭제를 위해 List 사용을 고려해야 하며, 빠른 임의 액세스가 필요한 경우 LinkedList를 사용해야 합니다. 요소에는 ArrayList를 사용해야 합니다.
프로그램이 단일 스레드 환경에 있거나 하나의 스레드에서만 액세스가 수행되는 경우 여러 스레드가 동시에 클래스를 작동할 수 있는 경우 더 효율적인 비동기 클래스를 고려하고 동기화된 클래스를 사용해야 합니다. .
해시 테이블의 작동에 특히 주의하세요. 키로 사용되는 개체는 equals 및 hashCode 메서드를 올바르게 덮어써야 합니다.
Map을 사용할 때는 HashMap 또는 HashTable을 사용하여 검색, 업데이트, 삭제 및 추가하는 것이 가장 좋습니다. Map을 자연 순서 또는 사용자 정의 키 순서로 탐색할 때는 TreeMap을 사용하는 것이 가장 좋습니다. ArrayList 대신 List를 반환하는 등 실제 유형 대신 인터페이스를 반환하므로 나중에 ArrayList를 LinkedList로 교체해야 하는 경우 클라이언트 코드를 변경할 필요가 없습니다. 이것은 추상화를 위한 프로그래밍입니다.
위 내용은 Java 프레임워크 사용법 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!