
Java의 바이너리 및 비트 연산에 대한 자세한 설명

- 零下一度원래의
- 2017-07-16 16:58:514057검색
1. 표현 방법:
자바 언어에서는 이진수를 2의 보수로 표현하며, 가장 높은 비트가 부호 비트이고, 양수의 부호 비트는 0, 음수의 부호 비트는 1입니다. 보완코드의 표현은 다음 요구사항을 충족해야 합니다.
(1) 양수의 가장 높은 비트는 0이고, 나머지 비트는 값 자체(이진수)를 나타냅니다.
(2) 음수의 경우 숫자의 절대값의 보수를 비트 단위로 반전한 다음 전체 숫자에 1을 더합니다.
2.비트 연산자
비트 연산표현은 정수형의 이진수에 대한 비트 연산을 구현하는 피연산자와 비트 연산자로 구성됩니다. 비트 연산자는 논리 연산자(~, &, | 및 ^ 포함)와 시프트 연산자(>>, << 및 >>> 포함)로 나눌 수 있습니다.
1) 왼쪽 이동 연산자(<<)는 연산자 왼쪽에 있는 피연산자를 연산자 오른쪽에 지정된 자릿수(낮은 비트에 0 채우기)만큼 왼쪽으로 이동할 수 있습니다.
2) "부호 있는" 오른쪽 이동 연산자(>>)는 연산자 왼쪽에 있는 피연산자를 연산자 오른쪽에 지정된 자릿수만큼 오른쪽으로 이동합니다. "부호 있는" 오른쪽 시프트 연산자는 "부호 확장"을 사용합니다. 값이 양수이면 상위 비트에 0이 삽입되고, 값이 음수이면 상위 비트에 1이 삽입됩니다.
3) Java에는 "0 확장"을 사용하는 "부호 없는" 오른쪽 시프트 연산자(>>>)도 추가되었습니다. 양수인지 음수인지에 관계없이 상위 비트에는 0이 삽입됩니다. 이 연산자는 C 또는 C++에서는 사용할 수 없습니다.
4) char, byte 또는 short가 시프트되는 경우 시프트가 수행되기 전에 자동으로 int로 변환됩니다. 오른쪽의 하위 5비트만 사용됩니다. 이렇게 하면 int 내에서 비현실적인 자릿수를 이동하는 것을 방지할 수 있습니다. 긴 값을 처리하면 최종 결과도 길어집니다. 이때, 이동이 Long 값에서 미리 만들어진 자릿수를 초과하는 것을 방지하기 위해 오른쪽의 하위 6비트만을 사용하게 됩니다. 그러나 "부호 없는" 오른쪽 시프트를 수행할 때 문제가 발생할 수도 있습니다. 바이트 또는 짧은 값에 대해 오른쪽 시프트 연산을 수행하면 결과가 올바르지 않을 수 있습니다(특히 Java 1.0 및 Java 1.1). 자동으로 int 유형으로 변환되고 오른쪽으로 이동됩니다. 그러나 "0 확장"은 발생하지 않으므로 이 경우 -1의 결과를 얻습니다.
바이너리는 컴퓨팅 기술에서 널리 사용되는 숫자 시스템입니다. 바이너리 데이터는 0과 1의 두 자리 숫자로 표현되는 숫자입니다. 기본은 2이고, 캐리 규칙은 "2 대 1"이며, 빌림 규칙은 "1을 빌려서 2와 같다"입니다. 이는 18세기 독일의 수학 철학의 대가인 라이프니츠에 의해 발견되었습니다. 현재의 컴퓨터 시스템은 기본적으로 이진법을 사용하고 있으며, 데이터는 주로 2의 보수 코드 형태로 컴퓨터에 저장된다. 컴퓨터의 이진 시스템은 매우 작은 스위치로, "켜짐"은 1을 나타내고 "꺼짐"은 0을 나타냅니다.
그러면 Java에서 바이너리는 어떤 모습일까요? 그 신비한 베일을 함께 밝혀봅시다.
1. Java에 내장된 기본 변환
10진수를 2진수로, 2진수를 10진수로 변환하는 기본적인 계산 방법은 여기서 다루지 않습니다.
Java에는 다양한 염기를 변환하는 데 도움이 되는 여러 메서드가 내장되어 있습니다. 아래 그림과 같이(정수 형태를 예로 들면 다른 유형도 동일함):
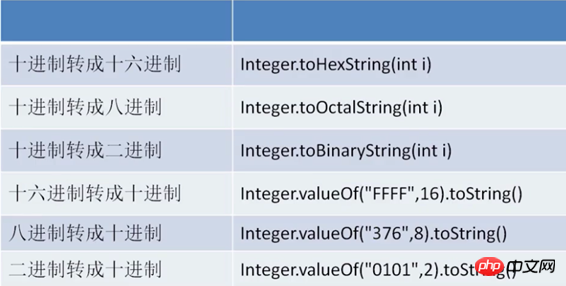
1, 십진수에서 다른 진수로 변환:
1 二进制:Integer.toHexString(int i);2 八进制:Integer.toOctalString(int i);3 十六进制:Integer.toBinaryString(int i);
2, 다른 진수에서 십진수로 변환:
1 二进制:Integer.valueOf("0101",2).toString;2 八进制:Integer.valueOf("376",8).toString;3 十六进制:Integer.valueOf("FFFF",16).toString;
3, Integer 클래스의 parseInt() 메서드와 valueOf() 메서드를 사용하여 다른 진수를 10진수로 변환할 수 있습니다.
parseInt() 메서드의 반환 값은 int 유형인 반면 valueOf()의 반환 값은 Integer 개체라는 차이점이 있습니다.
2. 기본 비트 연산
2진수는 10진수와 마찬가지로 더하기, 빼기, 곱하기, 나누기를 할 수 있지만 더 간단한 연산 방법인 비트 연산도 있습니다. 예를 들어, 컴퓨터에서 int 유형의 크기는 32비트이므로 32비트 이진수로 표현할 수 있으므로 비트 연산을 사용하여 int 유형 값을 계산할 수 있습니다. 물론 일부를 계산하는 데 일반적인 방법을 사용할 수도 있습니다. 데이터, 여기서는 주로 비트 연산 방법을 소개합니다. 우리는 비트 연산이 일반적인 연산 방법과 비교할 수 없는 힘을 가지고 있다는 것을 알게 될 것입니다. 비트 연산에 대한 더 많은 응용을 보려면 다음 블로그 게시물 "Magic Bit Operations"로 이동하세요.
먼저 비트 연산의 기본 연산자 를 살펴보겠습니다.
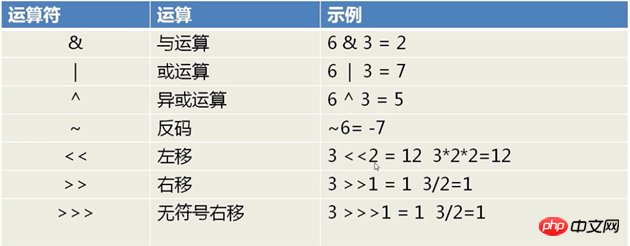
이점:
특정 상황 계산이 쉽고 빠르며 폭넓게 지원됩니다
산술 방법을 사용하면 속도가 느리고 논리가 복잡해집니다
비트별 연산은 하나의 언어에만 국한되지 않고 컴퓨터의 기본 연산 방식입니다
>>>>>>>>>>> >>>>>>>>>>>>>>>>>>> >>>>>>>>> 결과는 1
0&0=0; 1&0=0;예: 51&5는 0011 0011 & 0000 0101 =0000 0001 따라서 51&5=1입니다.
특별 사용법
(1)
지우세요.모든 이진 비트가 0이더라도 단위를 0으로 지우려면 비트가 모두 0인 값과 AND하면 결과는 0이 됩니다. (2)
숫자에서 지정된 위치를 가져옵니다.예: X=10101110이라고 가정하고 X의 하위 4자리를 취하고 X&0000 1111=0000 1110을 사용하여 구합니다.
방법: x에서 원하는 비트에 해당하는 숫자를 찾습니다. 숫자의 해당 비트는 1이고 나머지 비트는 0입니다. 이 숫자와 x에 대해 AND 연산을 수행하여 x에서 지정된 비트를 가져옵니다. (2) Bitwise OR |
둘 중 하나가 1이면 결과는 1입니다.
0|0=0; 1|0=1; 1|1=1;예: 51|5는 0000 0101 =0011 0111입니다. 55
특수 용도
는 종종 데이터의 특정 위치를
위해 사용됩니다.방법: 1로 설정할 x의 비트에 해당하는 숫자를 찾습니다. 숫자의 해당 비트는 1이고 나머지 비트는 0입니다. 이 숫자는 x를 기준으로 하거나 x의 일부 위치를 1로 설정합니다.
(3) XOR^두 개의 해당 비트가 "배타적"(다른 값)이면 비트 결과는 1이고, 그렇지 않으면 0
0^0=0입니다. 1^ 0=1; 1^1=0;예: 51^5는 0011 0011 ^ 0000 0101 =0011 0110 따라서 51^5=54
특수 사용법
(1)
독점 또는 1을 사용하여특정 비트를 뒤집으려면
방법: 에서 해당 비트에 해당하는 숫자를 찾습니다. 예: X=1010 1110, 아래 네 자리 숫자를 뒤집습니다. (2)
0과 배타적 OR, 원래 값 유지예:
C=A;A=B;B=C;2 두 변수의 교환을 실현하려면 덧셈과 뺄셈을 사용하세요.
A=A+B;B=A-B;A=A-B;
3.비트 사용 XOR 연산으로 구현되며 이는 가장 효율적인
원칙입니다. 숫자 XOR 자체는 0입니다. B(4) 부정 및 연산~이진수를 비트 단위로 반전합니다. 즉, 0을 1로, 1을 0~1=0; ~0=1
(5) 왼쪽 시프트< <피연산자의 모든 이진 비트를 특정 비트 수만큼 왼쪽으로 이동합니다(왼쪽의 이진 비트는 삭제되고 오른쪽에 0이 추가됨)예: 2<<1 =4 10<<1=100
왼쪽으로 시프트할 때 버려지는 상위 비트에 1이 없으면 왼쪽으로 시프트되는 각 비트는 숫자에 2를 곱하는 것과 같습니다.
예: 11(1011)<<2= 0010 1100=2211(00000000 00000000 00000000 1011) 32비트 형성
(6) 오른쪽 시프트>>
숫자의 모든 이진수를 특정 비트 수만큼 오른쪽으로 이동합니다. 양수는 왼쪽에 0을, 음수는 1을 추가하고 오른쪽은 버립니다. . 오른쪽으로 이동할 때 반올림하는 상위 비트가 1이 아닌 경우(즉, 음수가 아닌 경우) 피연산자가 오른쪽으로 이동할 때마다 숫자를 2로 나누는 것과 같습니다.
왼쪽에 0을 추가할지 1을 추가할지 여부는 이동되는 숫자가 양수인지 음수인지에 따라 달라집니다.
예: 4>>2=4/2/2=1
-14 (예: 1111 0010)>>2 =1111 1100=-4
(7) 부호 없는 오른쪽 시프트 연산> ;>
각 비트는 지정된 자릿수만큼 오른쪽으로 이동합니다. 가 오른쪽으로 이동한 후 왼쪽의 빈 비트는 0으로 채워지고 오른쪽의 비트는 제거되어 버려집니다.
예: -14>>>2
(예: 11111111 11111111 11111111 11110010)>>>2
=(00111111 11 111111 11111111 11111100)=1073741820
>>>>>>>>>>>>>>>>>>>>>>>> ;>>>>>>>>>>>>>>>>>>>>>>> ;> ;>>>
위에서 언급한 음수의 이진 비트 표현은 양수와 약간 다르기 때문에 비트 연산도 양수와 다릅니다.
음수는 양수의 보수 형태로 표현됩니다!
위에서 언급한 -14를 예로 들어 원본 코드, 역코드, 보완 코드를 간략하게 설명합니다.
원본 코드
정수를 절대값에 따라 이진수로 변환한 것을 원본 코드라고 합니다
예: 00000000 00000000 00000000 00001110은 14의 원본 코드입니다.
역코드
이진수를 비트 단위로 뒤집어서 나오는 새로운 이진수를 원래 이진수의 1의 보수라고 합니다.
예: 00000000 00000000 00000000 00001110,
get 11111111 11111111 11111111 11110001
의 각 비트를 부정합니다.참고: 이 둘은 서로를 보완합니다
보수 더하기 1을 보수라고 합니다
11111111 11111111 11111111 11110001 +1=
11111111 11111111 11111111 111100 10
이제 -14의 이진 표현을 얻었습니다. 이제 왼쪽으로 이동합니다
?분석: 이 이진수의 첫 번째 비트는 1이며 이는 2의 보수 형식임을 나타냅니다. 이제 보수를 원래 코드(양수 값)로 변환해야 합니다.
원래 코드 변환의 반대입니다. 보수로 보수를 원래 코드로 변환 코드 단계:역 코드를 얻으려면 보수 빼기 1: (11000111) 처음 24비트는 1이며 여기서 생략됨 역 코드는 다음으로 반전됩니다. 원래 코드(즉, 음수의 양수 값)를 구합니다(00111000)
- 양수 값을 계산하면 양수 값은 56
- 양수 값의 반대 숫자를 취해 결과를 얻습니다. -56
- 결론: -14<<2 = -56 3. 자바 시스템 산술의 발전
자바에서는 바이너리가 많이 사용되나요?
일반적인 개발에서는 "기본 변환"과 "비트 연산"이 많이 사용되지 않으며 Java는 상위 수준 작업을 처리합니다.
파일 읽기 및 쓰기, 데이터 통신 등 크로스 플랫폼에서 자주 사용됩니다.
시나리오를 살펴보겠습니다.
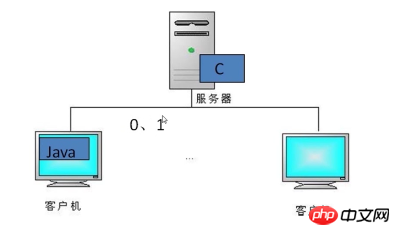
클라이언트와 서버가 모두 Java 언어로 작성된 프로그램인 경우 클라이언트가 객체 데이터를 보낼 때 데이터를 직렬화하여 직렬화할 수 있고 서버는 시퀀스 변환된 데이터 후에 데이터를 역직렬화하고 내부의 개체 데이터를 읽을 수 있습니다.
클라이언트 방문 횟수가 증가함에 따라 서버의 성능을 고려하지 않습니다. 실제로 가능한 해결책은 서버의 Java 언어를 C 언어로 변경하는 것입니다.
C 언어는 Java 언어보다 빠르게 반영됩니다. 이때 클라이언트가 직렬화된 데이터를 전달하면 서버 측의 C 언어가 이를 구문 분석할 수 없게 됩니다. 서버가 이러한 언어를 구문 분석할 수 있도록 데이터를 이진수(0,1)로 변환할 수 있습니다.
>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>>>>>> >>>>>>> Java에는 네 가지 기본 데이터 유형이 있습니다: Int 데이터 유형: 바이트(8비트, -128~127), 짧은(16비트) ), int(32bit), long(64bit) float 데이터 유형: 단정밀도(float, 32bit), 배정밀도(double, 64bit) Boolean 유형 변수에는 true 및 false 값이 있습니다(둘 다 1bit입니다). ) char 데이터 유형: 유니코드 문자, 16bit 해당 클래스 유형: Integer, Float, Boolean, Character, Double, Short, Byte, Long >>>> >>>>>>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>>>>>> 로 변환예: int type 8143 (00000000 00000000 00011111 11001111) =>byte[] b=[-49,31,0,0 ] First ( 하위) 바이트: 8143>>0*8 & 0xff=(11001111)=207 (또는 부호 있는 -49) 두 번째(최하위) 바이트: 8143>>1*8 &0xff=(00011111)= 31 세 번째(하위) 바이트: 8143>>2*8 &0xff=00000000=0 네 번째(하위) 바이트: 8143>> ;3*8 &0xff=00000000=0 위(낮은 끝)가 오른쪽에서 왼쪽으로 시작되는 것을 확인했습니다. 그렇다면 낮은 끝은 무엇인가요? 빅 엔디안과 스몰 엔디안의 관점에서 설명해보자. Little-Endian 방식(Little-Endian) 하위 비트 바이트는 값의 시작 주소인 메모리의 하위 주소 끝에 배열되고, 상위 비트 바이트는 메모리의 상위 주소 쪽 Big-Endian) high바이트가 메모리에 배열됩니다. low주소 쪽이 값의 시작 주소이고 low바이트는 메모리에 배열되어 있습니다. highaddress end 왜 크고 작은 엔디안 모드가 있나요? 이것은 컴퓨터 시스템에서 바이트를 단위로 사용하기 때문입니다. 각 주소 단위는 바이트에 해당하고 바이트는 8비트입니다. 하지만 C 언어에는 8비트 char 외에도 16비트 short 유형과 32비트 long 유형도 있습니다(특정 컴파일러에 따라 다름). 16비트나 32비트 프로세서 등의 비트는 레지스터 폭이 1바이트보다 크기 때문에 여러 바이트를 배열해야 하는 문제가 있을 수밖에 없다. 이는 빅엔디안 저장 모드와 리틀엔디안 저장 모드로 이어집니다. 예를 들어, 16비트 짧은 유형 x의 메모리 주소는 0x0010이고 x의 값은 0x1122입니다. 그러면 0x11이 상위 바이트이고 0x22가 하위 바이트입니다. 빅엔디안 모드의 경우 낮은 주소인 0x0010에 0x11을 넣고, 높은 주소인 0x0011에 0x22를 넣습니다. 리틀 엔디안 모드는 정반대입니다. 일반적으로 사용되는 X86 구조는 리틀 엔디안 모드인 반면 KEIL C51은 빅 엔디안 모드입니다. 많은 ARM과 DSP는 리틀 엔디안 모드에 있습니다. 일부 ARM 프로세서는 하드웨어별로 빅엔디안 또는 리틀엔디안 모드를 선택할 수도 있습니다. 예: 32비트 숫자 0x12 34 56 78(16진수) 빅 엔디안 모드 CPU(주소 0x4000에서 시작한다고 가정)의 저장 방법은 메모리 주소 0x4000 0x4001 0x4002 0x4003 存放内容 0x78 0x56 0x34 0x12 在Little-Endian模式CPU的存放方式(假设从地址0x4000开始存放)为 内存地址 0x4000 0x4001 0x4002 0x4003 存放内容 0x12 0x34 0x56 0x78 1.字符串->字节数组 2.字节数组->字符串 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 两种类型转化为字节的方法都介绍了,下面写个小例子检验一下: 运行结果: 结束语:最近偷懒了,没有好好学习,好几天没写文了,哎,还请大家多多监督! 위 내용은 Java의 바이너리 및 비트 연산에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
(1) 데이터 유형을 byte
(二)字符串转化为字节
1 String s;2 byte[] bs=s.getBytes();
1 Byte[] bs=new byte[int];2 String s =new String(bs);或3 String s=new String(bs,encode);//encode指编码方式,如utf-8
1 public class BtyeTest { 2 /* 3 * int整型转为byte字节 4 */ 5 public static byte[] intTOBtyes(int in){ 6 byte[] arr=new byte[4]; 7 for(int i=0;i<4;i++){ 8 arr[i]=(byte)((in>>8*i) & 0xff); 9 }10 return arr;11 }12 /*13 * byte字节转为int整型14 */15 public static int bytesToInt(byte[] arr){16 int sum=0;17 for(int i=0;i<arr.length;i++){18 sum+=(int)(arr[i]&0xff)<<8*i;19 }20 return sum;21 }22 public static void main(String[] args) {23 // TODO Auto-generated method stub24 byte[] arr=intTOBtyes(8143);25 for(byte b:arr){26 System.out.print(b+" ");27 }28 System.out.println();29 System.out.println(bytesToInt(arr));30 31 //字符串与字节数组32 String str="云开的立夏de博客园";33 byte[] barr=str.getBytes();34 35 String str2=new String(barr);36 System.out.println("字符串转为字节数组:");37 for(byte b:barr){38 System.out.print(b+" ");39 40 }41 System.out.println();42 43 System.out.println("字节数组换位字符串:"+str2);44 45 46 }47 48 }
