
Pandas 데이터 처리 예시 표시: 글로벌 상장 기업 데이터 수집
- 巴扎黑원래의
- 2017-07-22 11:39:263578검색
현재 Forbes의 2016년 글로벌 2000대 상장 기업 목록에 데이터가 있지만 원본 데이터는 표준화되지 않았으며 추가 사용 전에 처리가 필요합니다.
이 글에서는 실제 사례를 통해 데이터 구성에 팬더를 사용하는 방법을 소개합니다.
평소와 같이 먼저 내 운영 환경에 대해 이야기하겠습니다.
windows 7, 64-bit
python 3.5
pandas 버전 0.19.2
원본을 받은 후 데이터, 우리가 먼저 데이터를 살펴보고 어떤 데이터 결과가 필요한지 생각해 봅시다.
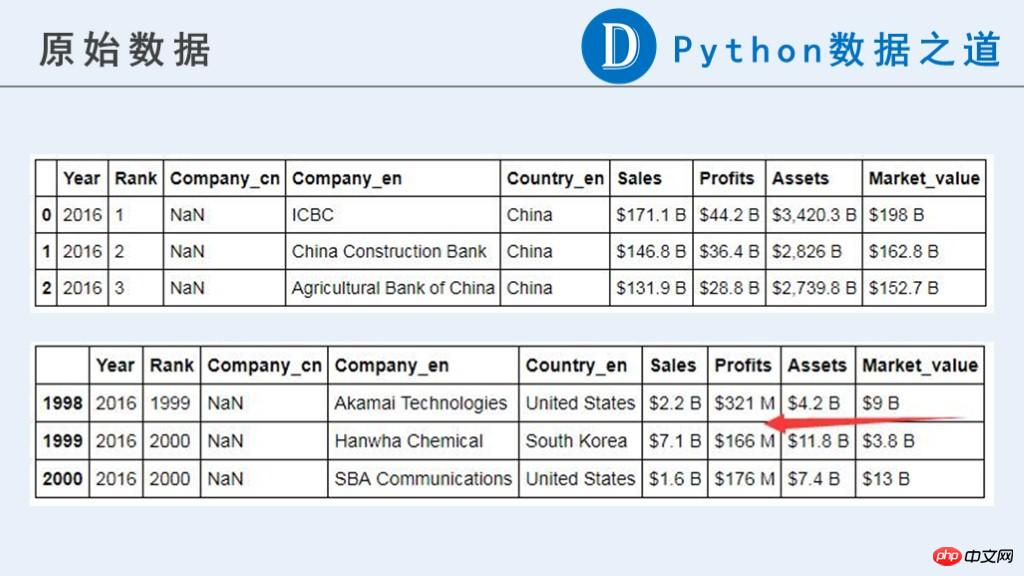
원시 데이터는 다음과 같습니다.
이 문서에서는 향후 사용을 위해 다음과 같은 예비 결과가 필요합니다.
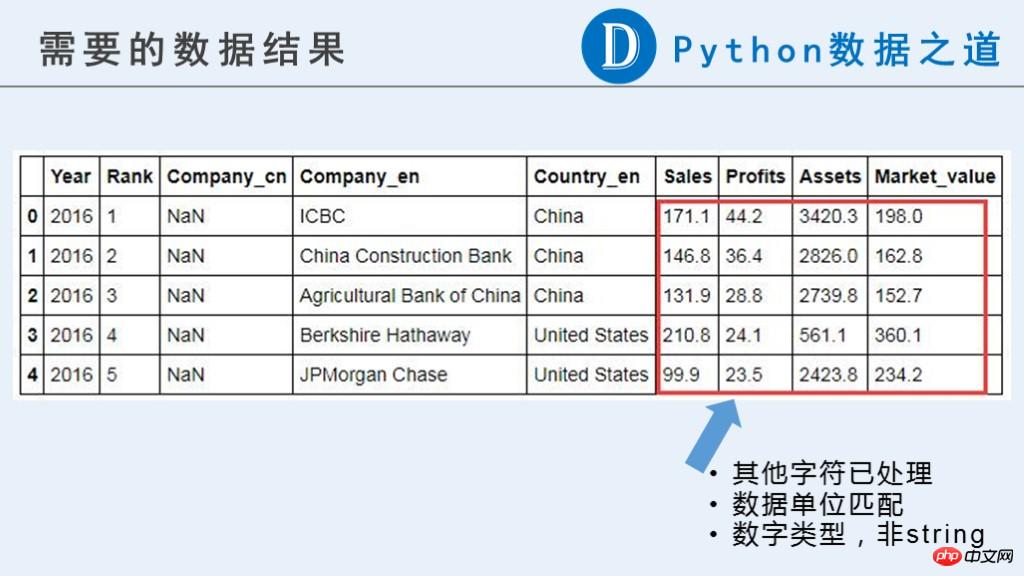
원래 데이터에서 기업과 관련된 데이터("매출", "이익", "자산", "시장_가치")는 현재 계산에 사용할 수 있는 숫자 유형이 아닌 것을 볼 수 있습니다.
원본 콘텐츠에는 통화 기호 "$", "-", 순수 문자로 구성된 문자열, 기타 비정상으로 간주되는 정보가 포함되어 있습니다. 게다가 이러한 데이터의 단위는 일관성이 없습니다. "B"(Billion, 10억)와 "M"(Million, 100만)으로 표시됩니다. 후속 계산 전에 단위 통일이 필요합니다.
1 처리 방법 Method-1
가장 먼저 떠오르는 처리 아이디어는 데이터 정보를 수십억('B')과 수백만('M')으로 분할하여 별도로 처리한 후 최종적으로 하나로 합치는 것입니다. 과정은 다음과 같습니다.
데이터 로드 및 열 이름 추가
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
데이터를 수십억('B') 단위로 가져오기
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b
데이터를 수백만('M') 단위로 가져오기
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m
이 방법은 비교적 이해하기 쉽지만 조작이 더 번거롭고, 특히 처리할 데이터 열이 많은 경우 시간이 많이 걸립니다.
여기서는 추가 처리에 대해 설명하지 않겠습니다. 물론 이 방법을 시도해 볼 수도 있습니다.
다음은 조금 더 간단한 방법입니다.
2 처리 방법 방법-2
2.1 데이터 로드
첫 번째 단계는 방법-1과 동일하게 데이터를 로드하는 것입니다.
다음은 'Sales' 열을 처리하는 방법입니다
2.2 관련 이상 문자 대체
먼저 달러 통화 기호 '$', 순수 알파벳 문자열 'undefine', '' 등 해당 이상 문자를 대체합니다. 비'. 여기서는 데이터 단위를 수십억 단위로 균일하게 구성하여 'B'를 직접 교체할 수 있도록 합니다. 그리고 'M'에는 더 많은 처리 단계가 필요합니다.
2.3 'M' 관련 데이터 처리
수백만 개의 "M" 단위가 포함된 데이터, 즉 "M"으로 끝나는 데이터를 처리하는 방법은 다음과 같습니다.
(1) 검색 조건 마스크를 설정합니다. ( 2) 문자열 "M"을 null 값으로 바꿉니다.
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df
3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
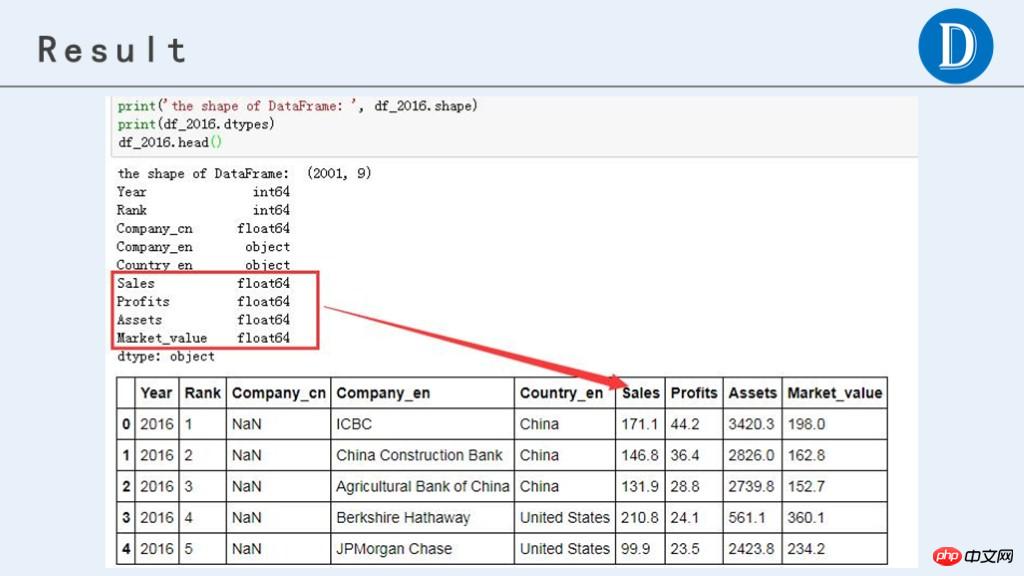
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
最终处理后,获得的数据结果如下:
위 내용은 Pandas 데이터 처리 예시 표시: 글로벌 상장 기업 데이터 수집의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!