
Python 반복자와 생성기에서 쉽게 혼동되는 개념

- 零下一度원래의
- 2017-07-17 09:58:131445검색
반복자와 생성기
반복자와 생성기는 Python에서 일반적으로 사용되며 쉽게 혼동되는 두 가지 개념입니다. 오늘은 이를 정리하고 일반적으로 사용되는 몇 가지 예를 제공하겠습니다.
for 문 및 반복 가능 객체(반복 가능 객체):
for i in [1, 2, 3]:
print(i)
obj = {"a": 123, "b": 456}
for k in obj:
print(k)
for 문에서 반복하는 데 사용할 수 있는 이러한 개체는 반복 가능한 개체입니다. for 문을 통해 반복할 수 있는 내장 데이터 유형(목록, 튜플, 문자열, 사전 등) 외에도 일련의 요소를 포함하는 컨테이너를 직접 만들 수도 있으며 각 요소는 반복될 수 있습니다. for 문을 통해 순차적으로 출력됩니다. 이 A 컨테이너는 반복자입니다.
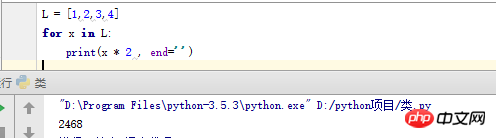
for 루프는 시퀀스, 튜플 및 문자열을 포함하여 Python의 모든 시퀀스 유형에 사용할 수 있습니다. 예:
>>> for x in [1,2,3,4]: print(x * 2,end='')
...
2468
>>> x in (1,2,3,4): print(x * 2,end='')
...
2468
>>> for y in 'python': print(y * 2 , end =' ')
...
pp yy tt hh oo nn
사실 for 루프는 이보다 훨씬 더 일반적입니다. 모든 반복 가능한 객체와 함께 사용할 수 있습니다. for는 반복 도구로 생각할 수 있으며 목록 구문 분석, 멤버십 테스트 및 내장 기능 매핑과 같은 몇 가지 예가 있습니다.
File iterator
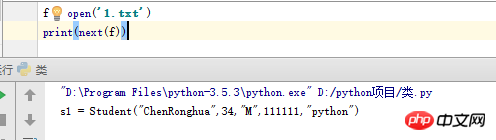
File에는 호출될 때마다 파일의 다음 줄을 반환하는 __next__라는 메서드가 있습니다. 파일 끝에 도달하면 __next__가 빈 문자열을 반환하는 대신 내장된 StopIteration 예외를 발생시킨다는 점은 주목할 가치가 있습니다.
예:
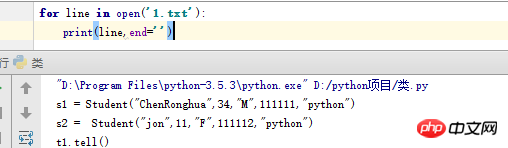
줄 문자열에 이미 하나가 있기 때문에 여기서 인쇄에서는 항상 n을 추가하기 위해 end=''를 사용합니다(이것이 없으면 출력은 두 줄로 구분됩니다).
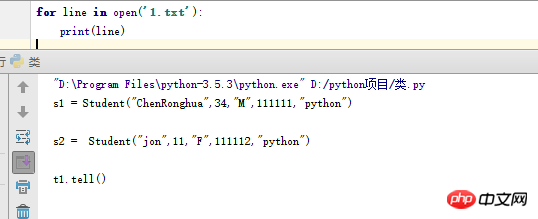
이 방법으로 파일을 읽으면 세 가지 장점이 있습니다.
1. 간단한 쓰기 방법
2. 빠른 실행 속도
3. 메모리 사용량 측면에서도 최고입니다.
원래 방법과 동일하지만, for 루프는 파일을 메모리에 로드하고 줄 문자열 목록을 만드는 파일의 readlines 메서드를 호출합니다.
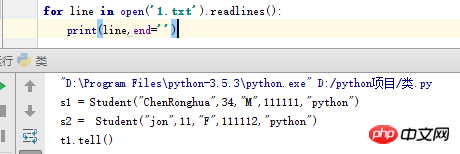
두 가지 효과는 동일하지만 후자는 파일을 메모리에 한 번에 로드하는 경우 파일이 너무 크면 컴퓨터 메모리 공간이 부족하여 작동하지 않을 수도 있습니다. 이전 반복자 버전에는 이 문제가 없습니다. (Python3에서는 유니코드 텍스트를 지원하도록 i/o를 다시 작성하여 이를 좀 덜 명확하게 만들고 시스템에 대한 의존도를 줄입니다.)
물론 while 루프로 구현할 수도 있지만 상대적으로 말하면 while은 여전히 for보다 느립니다.
수동 반복: iter 및 next
코드의 수동 반복을 지원하기 위해 Python3은 객체의 __next__ 메서드를 자동으로 사용하는 내장 함수 next도 제공합니다. 반복 가능한 객체 z가 주어지면 next(z)를 호출하는 것은 z.__next__()와 동일하지만 전자가 훨씬 더 간단합니다. 예를 들면 다음과 같습니다.
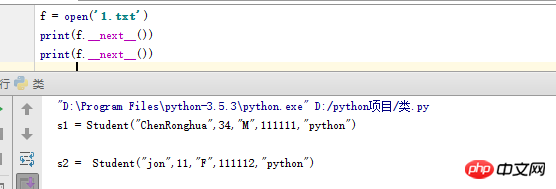
기술적인 관점에서 for 루프가 시작되면 반복 가능한 객체에서 반복자를 얻기 위해 iter 내장 함수를 제공하고 반환된 객체에는 다음이 포함됩니다. 다음 방법이 필요합니다.
목록 및 기타 여러 내장 객체는 반복자를 여러 번 열 수 있도록 지원하므로 반복자 자체가 아닙니다. 이러한 객체의 경우 iter를 호출하여 반복을 시작해야 합니다.
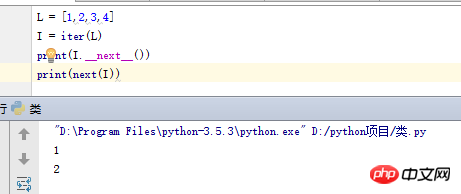
기술적으로 for 루프는 여기에서 사용된 next(I) 대신 I.__next__의 내부 등가물을 호출합니다
이제 우리는 사이의 자동 동등성을 보여줍니다. 수동 반복:
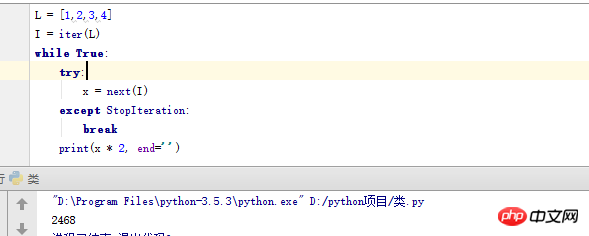
액션을 실행하고 작업 중 발생하는 예외를 캡처하는 try 문에 대해서는 나중에 기사를 게시하여 자세히 설명하겠습니다.
위 내용은 Python 반복자와 생성기에서 쉽게 혼동되는 개념의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!