
집 >데이터 베이스 >MySQL 튜토리얼 >mongoDB는 페이징을 어떻게 구현합니까?
mongoDB는 페이징을 어떻게 구현합니까?

- 零下一度원래의
- 2017-07-03 16:39:201964검색
이 글에서는 mongoDB구현 pagination의 두 가지 방법을 주로 소개하는데, 이는 일정한 참고값을 가지고 있습니다. 관심 있는 친구들은
mongoDB의 pagingquery를 Limit(), Skip(), Sort()를 통해 참고할 수 있습니다. 이 세 가지 기능을 결합하여 페이징 쿼리를 수행합니다. 다음은 내 테스트 데이터입니다
db.test.find().sort({"age":1});

방법첫 번째 페이지의 데이터를 쿼리합니다. db .test.find().sort({"age":1}).limit(2);
 두 번째 페이지의 데이터 쿼리: db.test.find().sort({"age" :1}).skip(2).limit(2);
두 번째 페이지의 데이터 쿼리: db.test.find().sort({"age" :1}).skip(2).limit(2);
 다른 페이지 수 등을 쿼리합니다. . .
다른 페이지 수 등을 쿼리합니다. . .
방법첫 번째 페이지의 데이터 쿼리: db.test.find().sort({"age":1}).limit(2);
위 숫자를 따르세요. 같은 방법입니다.
두 번째 페이지의 데이터 쿼리:
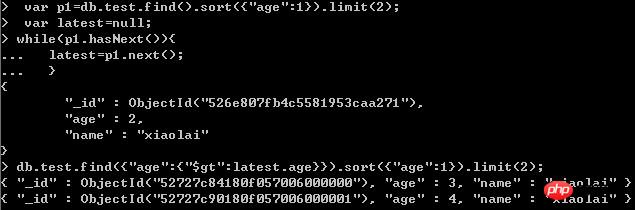 첫 번째 페이지에서 마지막 레코드의 값을 가져온 다음, 이전 레코드를 제외하여 새 레코드를 가져오는 것입니다.
첫 번째 페이지에서 마지막 레코드의 값을 가져온 다음, 이전 레코드를 제외하여 새 레코드를 가져오는 것입니다.
요약하면, 데이터의 양이 매우 큰 경우에는 첫 번째 방법을 사용하면 됩니다. 결국 비교적 간단한 방법이지만 데이터의 양이 비교적 큰 경우에는 이 방법을 사용하지 않기 때문에 두 번째 방법을 사용하는 것이 좋습니다. Skip() 기능을 사용해야 합니다. 건너뛰기가 너무 많아 녹음 효율성이 약간 낮습니다
고려한 결과 두 번째 방법은 페이지 건너뛰기에 적합하지 않으며 효율성도 그리 높지 않습니다대량 데이터의 경우 , 특별한 처리가 필요합니다.
다음 두 가지 방법이 있습니다.
첫 번째 방법
 뒤에 있는 통계 결과는 총 레코드 수를 추정할 수 있어야 합니다. 발견된 레코드의 비율에 따라
뒤에 있는 통계 결과는 총 레코드 수를 추정할 수 있어야 합니다. 발견된 레코드의 비율에 따라
Second One way
이렇게 하면 됩니다. ID에 따라 정렬되어 있다고 가정하면 해당 ID가 있는 페이지의 ID와 일련번호를 저장할 수 있습니다. redis/MemberCached, 이렇게 각 페이지에 10개의 레코드가 있다고 가정합니다.
id 페이지
1 1
2 1
. . .
10 1
11 2
12 2
. . . .
20 2
이런 식으로 첫 페이지를 확인하면 바로 10개의 데이터를 검색할 수 있습니다
1억 개의 데이터가 있고, 하나의 레코드 ID가 4바이트를 차지하고, 다른 정보는 1바이트를 차지하고, 하나의 레코드가 5바이트를 차지합니다
1 0000 0000 *5/(1024*1024)=476MB
이 접근 방식은 시간 대비 공간을 사용합니다. 일반적으로 데이터베이스 쿼리 시간의 대부분은 데이터베이스에 연결하는 데 소비됩니다. 캐시는 쿼리 속도를 크게 높일 수 있습니다
위 내용은 mongoDB는 페이징을 어떻게 구현합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!