
HashMap의 구현 원리 분석

- 零下一度원래의
- 2017-07-03 11:57:582278검색
이 기사에서는 HashMap의 구현 원리를 분석하고 크기 조정으로 인해 무한 루프 및 Fast-fail과 같은 스레드에 안전하지 않은 동작이 발생할 수 있는 방법을 분석합니다. 동시에 소스 코드와 결합하여 JDK 1.7 및 JDK 1.8의 ConcurrentHashMap 구현 원리를 데이터 구조, 주소 지정 방법, 동기화 방법, 크기 계산 등의 관점에서 분석합니다. 스레드에 안전하지 않은 HashMap 우리 모두 알고 있듯이 HashMap은 스레드로부터 안전하지 않습니다. HashMap의 스레드 불안정성은 크기 조정 중 무한 루프와 반복자 사용 시 빠른 실패에 주로 반영됩니다.
참고: 이 장의 코드는 JDK 1.7.0_67
HashMap 작동 원리를 기반으로 합니다.
HashMap 데이터 구조
일반적으로 사용되는 기본 데이터 구조에는 주로 배열과 연결 목록이 포함됩니다. 배열 저장 범위는 연속적이고 메모리를 많이 차지하며 주소 지정이 쉽고 삽입 및 삭제가 어렵습니다. 연결된 목록은 저장 간격이 분리되어 있고 메모리를 덜 차지하며 주소 지정이 어렵고 삽입 및 삭제가 쉽습니다.
HashMap은 해시 테이블의 효과를 달성하는 것을 목표로 하며 O(1) 수준 추가, 삭제, 수정 및 쿼리를 달성하려고 합니다. 구체적인 구현에서는 배열과 연결 목록을 모두 사용합니다. 가장 바깥쪽 레이어는 배열이고 배열의 각 요소는 연결 목록의 헤드라고 간주할 수 있습니다.
HashMap 주소 지정 방법
새로 삽입된 데이터나 읽을 데이터에 대해 HashMap은 배열 길이에 대한 Key 모듈로의 해시 값을 취하고 그 결과를 배열의 Entry 인덱스로 사용합니다. 컴퓨터에서는 모듈로 비용이 비트 연산 비용보다 훨씬 높으므로 HashMap에서는 배열 길이가 2의 N승이어야 합니다. 이때 Key의 해시 값은 2^N-1로 AND 처리되며, 그 효과는 모듈로와 동일합니다. HashMap은 사용자가 HashMap 용량을 지정할 때 2의 N승 정수를 전달할 필요가 없으며 대신 Integer.highestOneBit을 통해 지정된 정수보다 작은 가장 큰 2^N 값을 계산합니다. .
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16); return i - (i >>> 1);
}Key의 해시값 분포는 해시 테이블의 모든 데이터 분포나 해시 충돌 가능성을 직접적으로 결정하므로 Key hashCode 구현 불량을 방지하기 위해(예: 하위 비트는 동일함) 상위 비트는 다르며 2^N-1로 AND한 후의 결과는 동일합니다.) JDK 1.7의 HashMap은 다음 방법을 사용하여 최종 해시 값의 이진 형식으로 1을 최대한 균등하게 분산시킵니다. 해시 충돌을 최대한 줄입니다.
int h = hashSeed; h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
resize 무한 루프
전송 방법
HashMap의 크기가 용량*loadFactor를 초과하는 경우 HashMap을 확장해야 합니다. 구체적인 방법은 원래 용량의 두 배 길이로 새 어레이를 생성하여 새 용량이 여전히 2의 N승이 되도록 보장함으로써 위의 주소 지정 방법을 계속 적용할 수 있도록 하는 것입니다. 동시에 다음 전송 방법을 통해 모든 원본 데이터를 새 배열에 다시 삽입(재해시)해야 합니다.
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) {while(null != e) {
Entry<K,V> next = e.next; if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
} int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}이 메서드는 스레드 안전성을 보장하지 않으며 여러 스레드에서 동시에 호출할 경우 무한 루프가 발생할 수 있습니다. 실행과정은 다음과 같습니다. 2단계에서 볼 수 있듯이 전송 중에 연결된 목록의 순서가 반전됩니다.
원본 배열의 요소를 트래버스합니다.
연결된 목록의 각 노드를 트래버스합니다. 전송할 다음 요소를 가져오려면 next를 사용하고, e를 새 배열의 헤드로 전송하고 헤드 보간을 사용하여 삽입합니다. 노드
연결된 목록 노드가 모두 전송될 때까지 2번을 반복합니다.
모든 요소가 전송될 때까지 1번을 반복합니다.
단일 스레드 재해시
단일 스레드의 경우 재해시는 문제가 없습니다. 아래 그림은 단일 스레드 조건에서 rehash 프로세스를 보여줍니다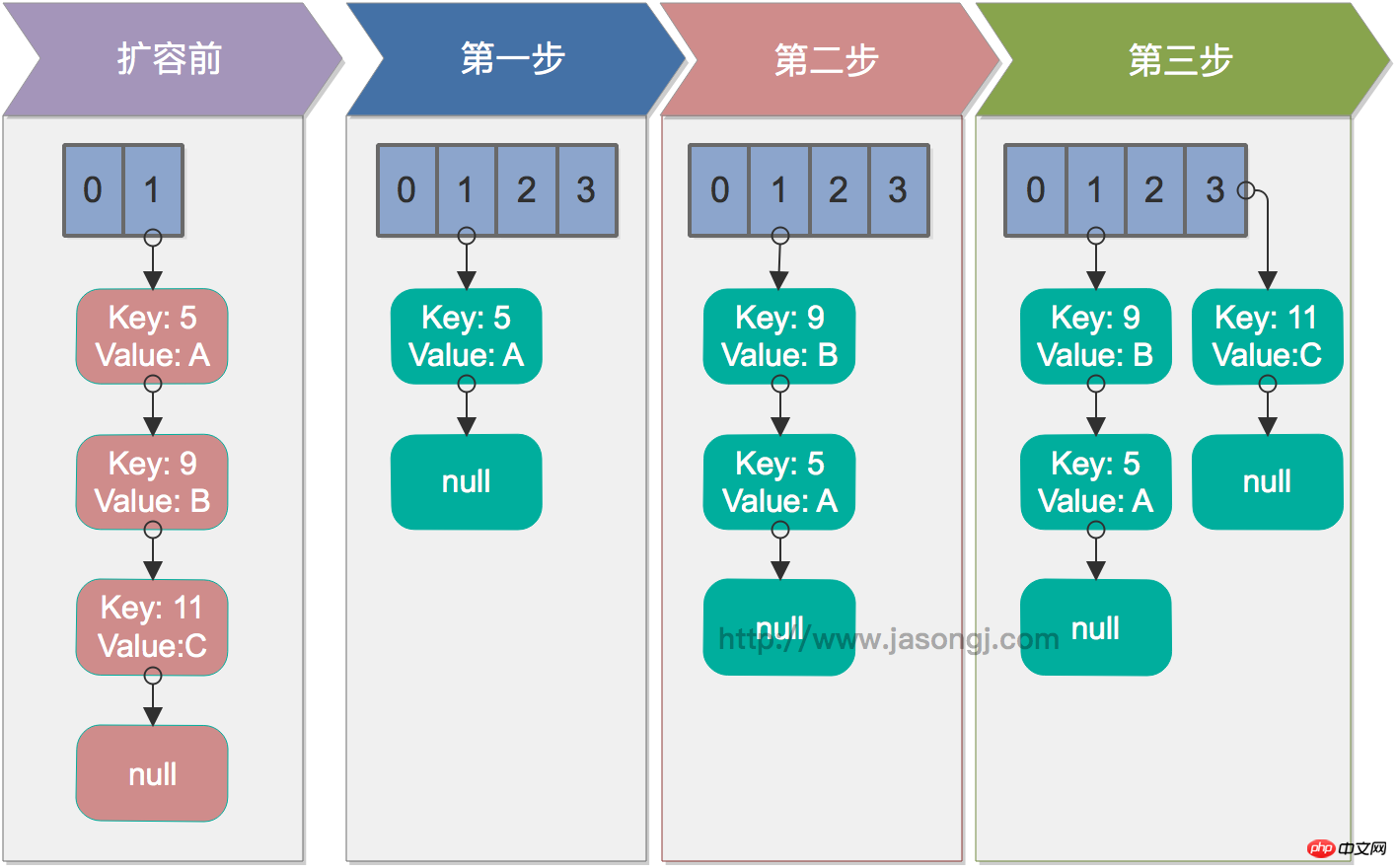
다중 스레드 동시성에서 rehash
두 스레드가 동시에 put 작업을 실행하고 rehash를 트리거하고 전송 메서드를 실행하고 가정합니다. 스레드가 전송에 들어간다는 것 next = e.next 메소드를 실행한 후, 스레드 스케줄링에 의해 할당된 타임 슬라이스가 모두 사용되었기 때문에 "일시 중지"됩니다. 이때 스레드 2는 전송 메소드의 실행을 완료합니다. 현재 상태는 다음과 같습니다.
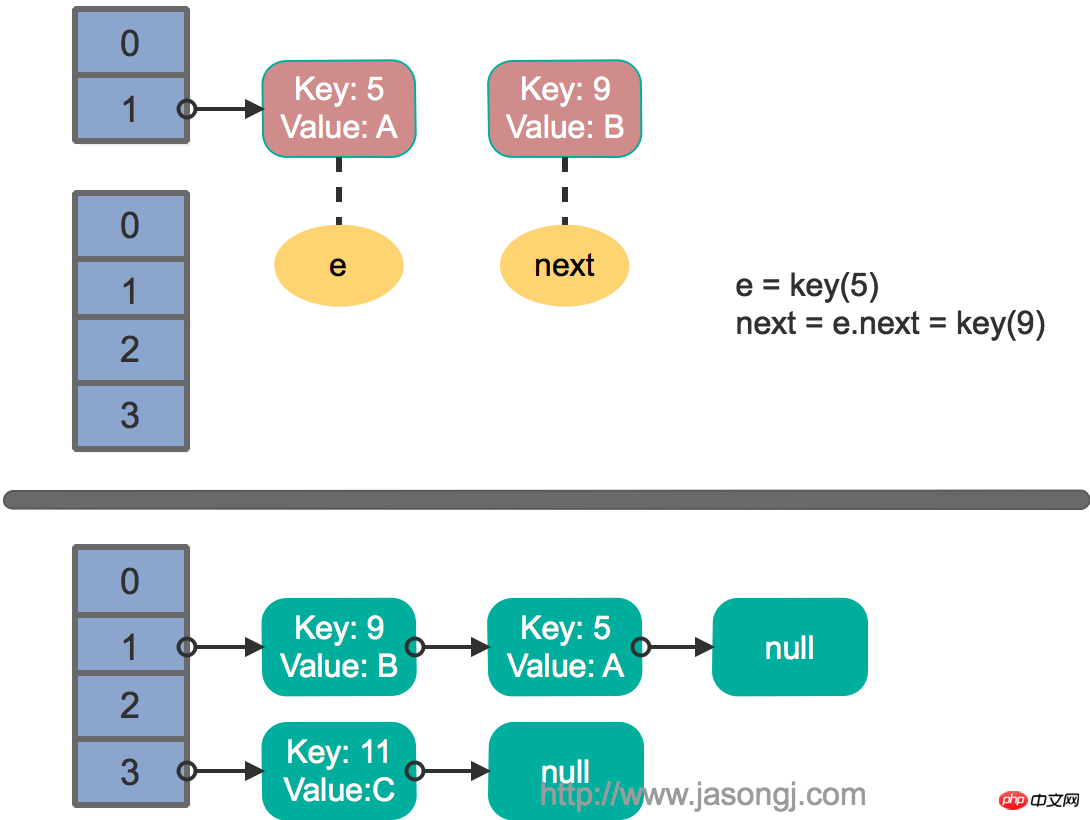
그런 다음 스레드 1이 활성화되어 첫 번째 루프 라운드의 나머지 부분을 계속 실행합니다.
e.next = newTable[1] = nullnewTable[1] = e = key(5) e = next = key(9)
结果如下图所示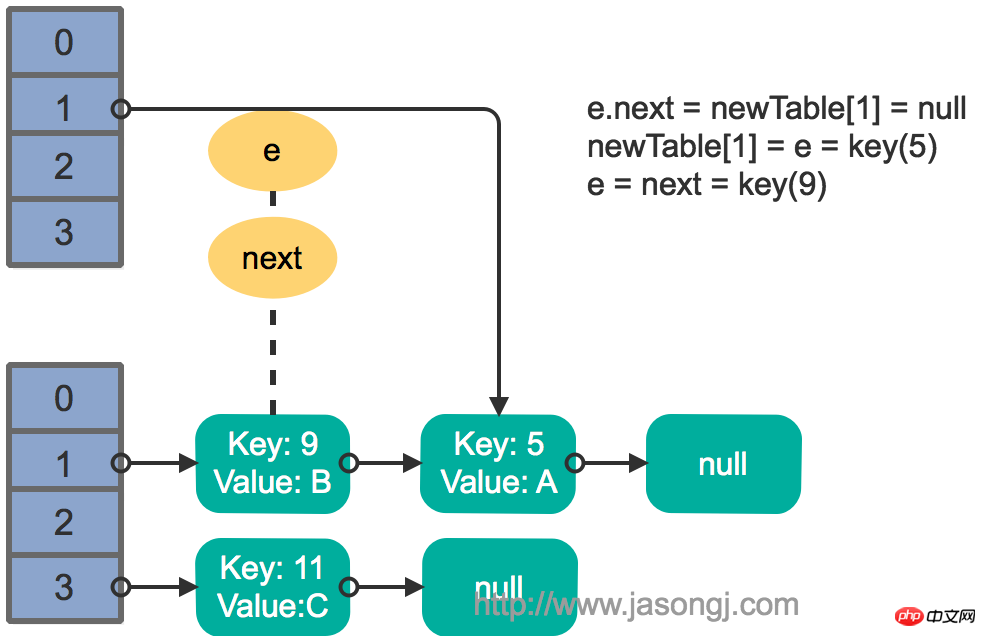
接着执行下一轮循环,结果状态图如下所示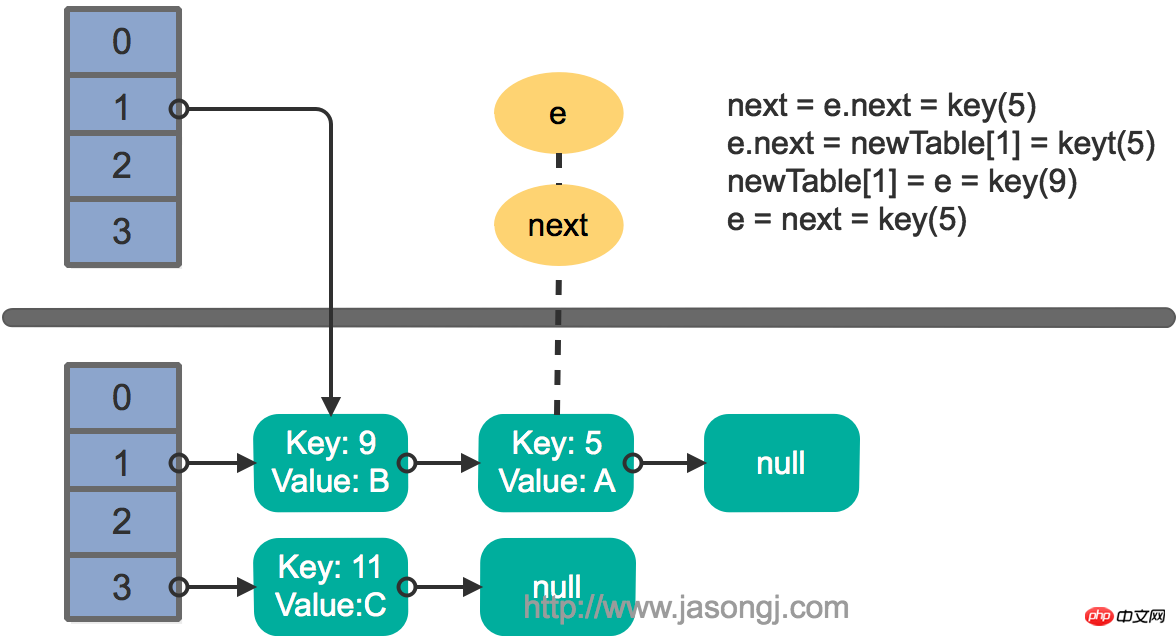
继续下一轮循环,结果状态图如下所示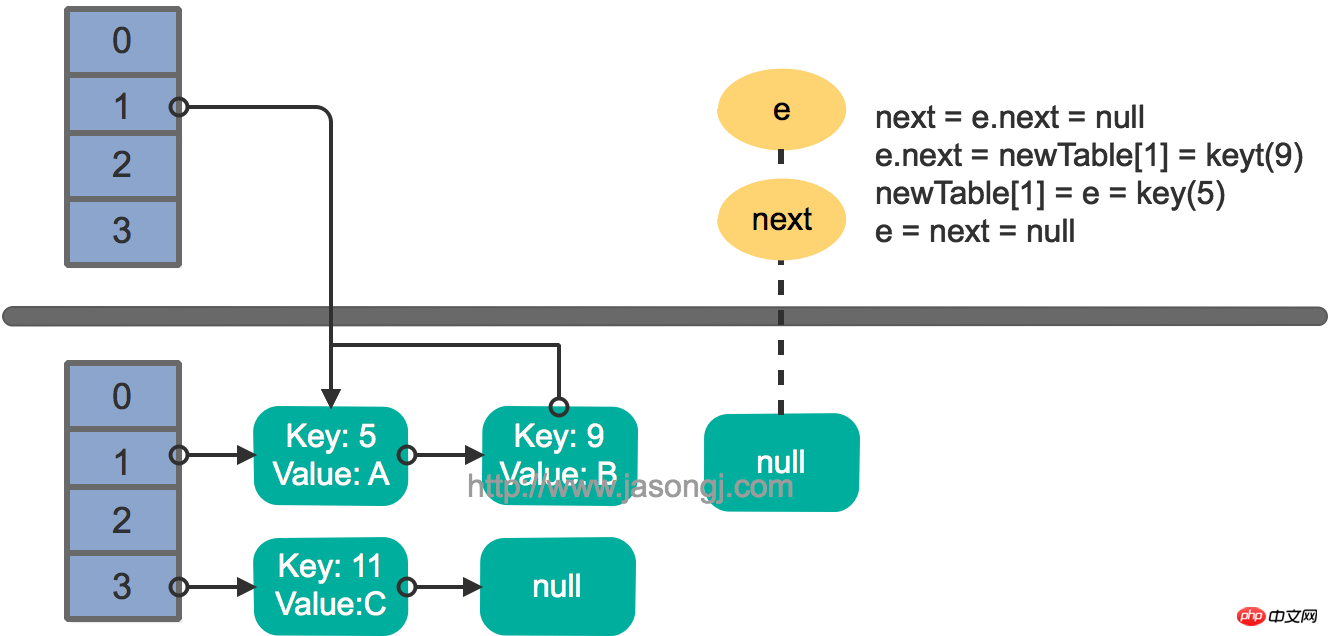
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
Fast-fail
产生原因
在使用迭代器的过程中如果HashMap被修改,那么ConcurrentModificationException将被抛出,也即Fast-fail策略。
当HashMap的iterator()方法被调用时,会构造并返回一个新的EntryIterator对象,并将EntryIterator的expectedModCount设置为HashMap的modCount(该变量记录了HashMap被修改的次数)。
HashIterator() {
expectedModCount = modCount; if (size > 0) { // advance to first entry
Entry[] t = table; while (index < t.length && (next = t[index++]) == null)
;
}
}在通过该Iterator的next方法访问下一个Entry时,它会先检查自己的expectedModCount与HashMap的modCount是否相等,如果不相等,说明HashMap被修改,直接抛出ConcurrentModificationException。该Iterator的remove方法也会做类似的检查。该异常的抛出意在提醒用户及早意识到线程安全问题。
线程安全解决方案
单线程条件下,为避免出现ConcurrentModificationException,需要保证只通过HashMap本身或者只通过Iterator去修改数据,不能在Iterator使用结束之前使用HashMap本身的方法修改数据。因为通过Iterator删除数据时,HashMap的modCount和Iterator的expectedModCount都会自增,不影响二者的相等性。如果是增加数据,只能通过HashMap本身的方法完成,此时如果要继续遍历数据,需要重新调用iterator()方法从而重新构造出一个新的Iterator,使得新Iterator的expectedModCount与更新后的HashMap的modCount相等。
多线程条件下,可使用Collections.synchronizedMap方法构造出一个同步Map,或者直接使用线程安全的ConcurrentHashMap。
Java 7基于分段锁的ConcurrentHashMap
注:本章的代码均基于JDK 1.7.0_67
数据结构
Java 7中的ConcurrentHashMap的底层数据结构仍然是数组和链表。与HashMap不同的是,ConcurrentHashMap最外层不是一个大的数组,而是一个Segment的数组。每个Segment包含一个与HashMap数据结构差不多的链表数组。整体数据结构如下图所示。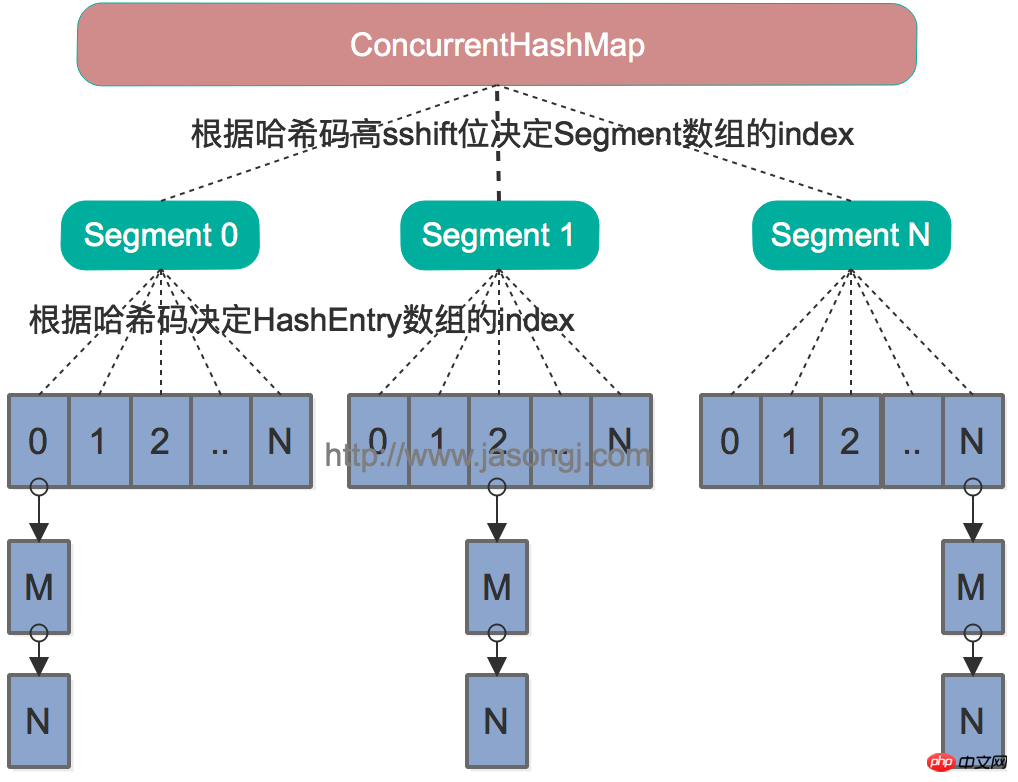
寻址方式
在读写某个Key时,先取该Key的哈希值。并将哈希值的高N位对Segment个数取模从而得到该Key应该属于哪个Segment,接着如同操作HashMap一样操作这个Segment。为了保证不同的值均匀分布到不同的Segment,需要通过如下方法计算哈希值。
private int hash(Object k) { int h = hashSeed; if ((0 != h) && (k instanceof String)) {return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14); return h ^ (h >>> 16);
}同样为了提高取模运算效率,通过如下计算,ssize即为大于concurrencyLevel的最小的2的N次方,同时segmentMask为2^N-1。这一点跟上文中计算数组长度的方法一致。对于某一个Key的哈希值,只需要向右移segmentShift位以取高sshift位,再与segmentMask取与操作即可得到它在Segment数组上的索引。
int sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];同步方式
Segment继承自ReentrantLock,所以我们可以很方便的对每一个Segment上锁。
对于读操作,获取Key所在的Segment时,需要保证可见性(请参考如何保证多线程条件下的可见性)。具体实现上可以使用volatile关键字,也可使用锁。但使用锁开销太大,而使用volatile时每次写操作都会让所有CPU内缓存无效,也有一定开销。ConcurrentHashMap使用如下方法保证可见性,取得最新的Segment。
Segment<K,V> s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)
获取Segment中的HashEntry时也使用了类似方法
HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE)
对于写操作,并不要求同时获取所有Segment的锁,因为那样相当于锁住了整个Map。它会先获取该Key-Value对所在的Segment的锁,获取成功后就可以像操作一个普通的HashMap一样操作该Segment,并保证该Segment的安全性。
同时由于其它Segment的锁并未被获取,因此理论上可支持concurrencyLevel(等于Segment的个数)个线程安全的并发读写。
获取锁时,并不直接使用lock来获取,因为该方法获取锁失败时会挂起(参考可重入锁)。事实上,它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
这里使用自旋锁是因为自旋锁的效率比较高,但是它消耗CPU资源比较多,因此在自旋次数超过阈值时切换为互斥锁。
size操作
put、remove和get操作只需要关心一个Segment,而size操作需要遍历所有的Segment才能算出整个Map的大小。一个简单的方案是,先锁住所有Sgment,计算完后再解锁。但这样做,在做size操作时,不仅无法对Map进行写操作,同时也无法进行读操作,不利于对Map的并行操作。
为更好支持并发操作,ConcurrentHashMap会在不上锁的前提逐个Segment计算3次size,如果某相邻两次计算获取的所有Segment的更新次数(每个Segment都与HashMap一样通过modCount跟踪自己的修改次数,Segment每修改一次其modCount加一)相等,说明这两次计算过程中无更新操作,则这两次计算出的总size相等,可直接作为最终结果返回。如果这三次计算过程中Map有更新,则对所有Segment加锁重新计算Size。该计算方法代码如下
public int size() { final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation }
sum = 0L;
size = 0;
overflow = false; for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {
sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0)
overflow = true;
}
} if (sum == last)break;
last = sum;
}
} finally {if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();
}
} return overflow ? Integer.MAX_VALUE : size;
}不同之处
ConcurrentHashMap与HashMap相比,有以下不同点
ConcurrentHashMap线程安全,而HashMap非线程安全
HashMap允许Key和Value为null,而ConcurrentHashMap不允许
HashMap不允许通过Iterator遍历的同时通过HashMap修改,而ConcurrentHashMap允许该行为,并且该更新对后续的遍历可见
Java 8基于CAS的ConcurrentHashMap
注:本章的代码均基于JDK 1.8.0_111
数据结构
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示
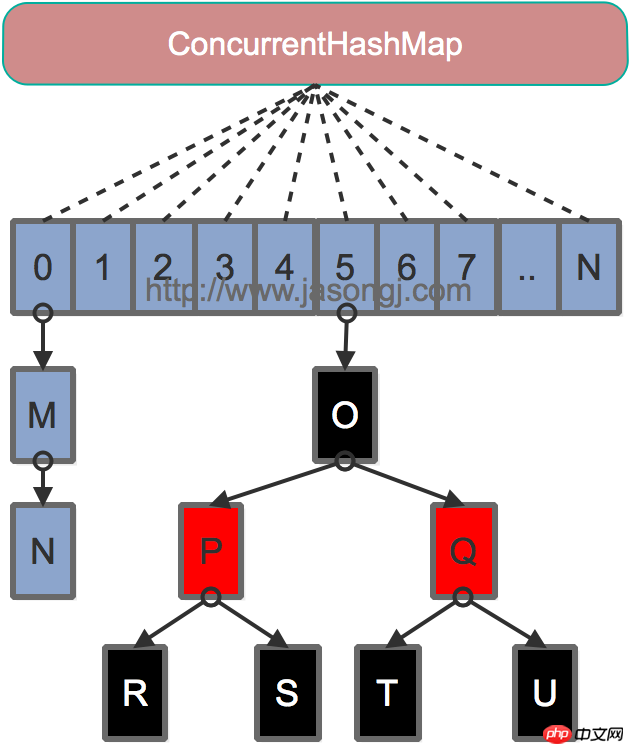
寻址方式
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)。
static final int spread(int h) { return (h ^ (h >>> 16)) & HASH_BITS;
}同步方式
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next;
}对于Key对应的数组元素的可见性,由Unsafe的getObjectVolatile方法保证。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}size 연산
put 메소드와 Remove 메소드 모두 addCount 메소드를 통해 Map의 크기를 유지합니다. size 메소드는 sumCount를 통해 addCount 메소드에 의해 유지되는 Map의 크기를 가져옵니다.
Java Advanced Series
Java Advanced(1) Annotation(Annotation)
Java Advanced(2) 스레드 안전성이란 무엇을 의미하는가
Java Advanced(3) 핵심 기술 멀티 스레드 개발
Java 고급 (4) 스레드 간 통신 방법 비교
Java 고급 (5) NIO 및 Reactor 모드 고급
Java 고급 (6) ConcurrentHashMap에서 Evolution은 Java 멀티 스레드를 살펴봅니다. 스레딩 핵심기술
위 내용은 HashMap의 구현 원리 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!