
해시--일반적인 알고리즘 소개

- 零下一度원래의
- 2017-06-29 11:29:192946검색
해시(Hash)는 해싱으로도 알려져 있으며 매우 일반적인 알고리즘입니다. 해시는 주로 Java의 HashMap 데이터 구조에서 사용됩니다. 해시 알고리즘은 해시 함수와 해시 테이블의 두 부분으로 구성됩니다. 우리는 배열의 특성을 첨자(O(1))를 통해 빠르게 알 수 있습니다. 마찬가지로 해시 테이블에서는 키(해시 값)를 통해 특정 값을 빠르게 찾을 수 있습니다. 해시 값은 해시 함수 (해시(키) = 주소)를 통해 계산됩니다. [address] = value 요소는 해시 값을 통해 찾을 수 있으며, 원리는 배열과 유사합니다.
가장 좋은 해시 함수는 물론 각 key 값에 대해 고유한 해시 값을 계산할 수 있는 함수이지만, 종종 서로 다른 key 값에 대한 해시 값이 있을 수 있으며 이로 인해 두 가지 측면에서 충돌이 발생합니다. 해시 함수가 잘 설계되었는지 판단하려면:
1. 충돌이 거의 없습니다.
2. 계산이 빠릅니다.
일반적으로 사용되는 몇 가지 해시 함수는 모두 특정 수학적 원리를 갖고 있으며 여기서는 수학적 원리를 다루지 않습니다.
BKDR해시 함수 (h = 31 * h + c)
이 해시 함수는 Java에서 문자열 해시 값 계산에 적용됩니다.
//String#hashCodepublic int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; //BKDR 哈希函数,常数可以是131、1313、13131…… }
hash = h;
}return h;
}DJB2 해시 함수(h = h << 5 + h + c = h = 33 * h + c)
ElasticSearch 그냥 DJB2hash 함수를 사용하여 색인화할 문서의 지정된 key을 해시합니다.
SDBM해시 함수(h = h < SDBM (간단한 데이터베이스 엔진))를 사용합니다.
위에는 세 가지 해시 함수가 나열되어 있으며 충돌이 어떻게 나타나는지 실험해 보겠습니다.Java
1 package com.algorithm.hash; 2 3 import java.util.HashMap; 4 import java.util.UUID; 5 6 /** 7 * 三种哈希函数冲突数比较 8 * Created by yulinfeng on 6/27/17. 9 */10 public class HashFunc {11 12 public static void main(String[] args) {13 int length = 1000000; //100万字符串14 //利用HashMap来计算冲突数,HashMap的键值不能重复所以length - map.size()即为冲突数15 HashMap<String, String> bkdrMap = new HashMap<String, String>();16 HashMap<String, String> djb2Map = new HashMap<String, String>();17 HashMap<String, String> sdbmMap = new HashMap<String, String>();18 getStr(length, bkdrMap, djb2Map, sdbmMap);19 System.out.println("BKDR哈希函数100万字符串的冲突数:" + (length - bkdrMap.size()));20 System.out.println("DJB2哈希函数100万字符串的冲突数:" + (length - djb2Map.size()));21 System.out.println("SDBM哈希函数100万字符串的冲突数:" + (length - sdbmMap.size()));22 }23 24 /**25 * 生成字符串,并计算冲突数26 * @param length27 * @param bkdrMap28 * @param djb2Map29 * @param sdbmMap30 */31 private static void getStr(int length, HashMap<String, String> bkdrMap, HashMap<String, String> djb2Map, HashMap<String, String> sdbmMap) {32 for (int i = 0; i < length; i++) {33 System.out.println(i);34 String str = UUID.randomUUID().toString();35 bkdrMap.put(String.valueOf(str.hashCode()), str); //Java的String.hashCode就是BKDR哈希函数, h = 31 * h + c36 djb2Map.put(djb2(str), str); //DJB2哈希函数37 sdbmMap.put(sdbm(str), str); //SDBM哈希函数38 }39 }40 41 /**42 * djb2哈希函数43 * @param str44 * @return45 */46 private static String djb2(String str) {47 int hash = 0;48 for (int i = 0; i != str.length(); i++) {49 hash = hash * 33 + str.charAt(i); //h = h << 5 + h + c = h = 33 * h + c50 }51 return String.valueOf(hash);52 }53 54 /**55 * sdbm哈希函数56 * @param str57 * @return58 */59 private static String sdbm(String str) {60 int hash = 0;61 for (int i = 0; i != str.length(); i++) {62 hash = 65599 * hash + str.charAt(i); //h = h << 6 + h << 16 - h + c = 65599 * h + c63 }64 return String.valueOf(hash);65 }66 }
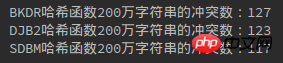
다음은 10million,
million, 백만:
반복적인 시도를 통해 세 가지 해시 함수 간의 충돌 횟수가 실제로 거의 동일한 것으로 나타났습니다. 
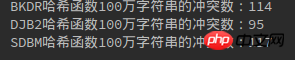 3
3
1 import uuid 2 3 def hash_test(length, bkdrDic, djb2Dic, sdbmDic): 4 for i in range(length): 5 string = str(uuid.uuid1()) #基于时间戳 6 bkdrDic[bkdr(string)] = string 7 djb2Dic[djb2(string)] = string 8 sdbmDic[sdbm(string)] = string 9 10 #BDKR哈希函数11 def bkdr(string):12 hash = 013 for i in range(len(string)):14 hash = 31 * hash + ord(string[i]) # h = 31 * h + c15 return hash16 17 #DJB2哈希函数18 def djb2(string):19 hash = 020 for i in range(len(string)):21 hash = 33 * hash + ord(string[i]) # h = h << 5 + h + c22 return hash23 24 #SDBM哈希函数25 def sdbm(string):26 hash = 027 for i in range(len(string)):28 hash = 65599 * hash + ord(string[i]) # h = h << 6 + h << 16 - h + c29 return hash30 31 length = 10032 bkdrDic = dict() #bkdrDic = {}33 djb2Dic = dict()34 sdbmDic = dict()35 hash_test(length, bkdrDic, djb2Dic, sdbmDic)36 print("BKDR哈希函数100万字符串的冲突数:%d"%(length - len(bkdrDic)))37 print("DJB2哈希函数100万字符串的冲突数:%d"%(length - len(djb2Dic)))38 print("SDBM哈希函数100万字符串的冲突数:%d"%(length - len(sdbmDic)))
해시 테이블은 빠른 검색을 위해 인덱스를 생성하기 위해 해시 함수와 함께 사용해야 하는 데이터 구조입니다——"알고리즘 노트". 일반적으로 고정 길이 저장 공간입니다. 예를 들어 HashMap의 기본 해시 테이블은 고정 길이가 16인 Entry 배열입니다. 고정된 길이의 저장 공간을 만든 후 남은 문제는 값을 어떤 위치에 넣을 것인가 하는 것입니다. 일반적으로 해시 값이 m이고 길이가 n이면 값이 저장됩니다. m mod n 위치.
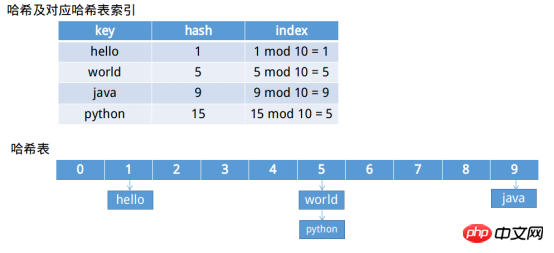
위 그림은 해시와 해시 테이블, 충돌 해결 방법(지퍼 방식)을 보여줍니다. 충돌을 해결하는 방법에는 충돌이 없을 때까지 다시 해싱하는 방법이나 위 그림과 같이 연결 리스트를 사용하여 지퍼 방식을 사용하여 동일한 위치의 요소를 연결하는 방법 등 여러 가지가 있습니다.
위 예에서 해시 테이블의 길이가 10이고 결과적으로 1 충돌이 발생한다고 상상해 보세요. 해시 테이블의 길이가 20이면 충돌이 발생하지 않습니다. 검색 속도는 더 빨라지지만 더 많은 공간을 낭비하게 됩니다. 해시 테이블 길이가 2이면 반전되어 3번 충돌 검색 속도가 느려지지만 이로 인해 많은 비용이 절약됩니다. 공간. 그래서 해시 테이블의 길이 선택도 중요하지만 중요한 문제이기도 합니다.
보충:
해시는 서로 다른 값이 서로 다른 해시 값을 갖는 등 여러 측면에서 사용되지만 해시 알고리즘은 유사하거나 동일한 값을 유사하거나 유사하게 만들도록 정교하게 설계할 수도 있습니다. 동일합니다. 해시 값입니다. 즉, 두 개체가 완전히 다른 경우 해시 값도 완전히 다릅니다. 두 개체가 정확히 동일하면 두 개체가 더 유사할수록 해시 값도 완전히 동일합니다. 해시 값도 완전히 다릅니다. 이는 실제로 유사성 문제인데, 이는 이 아이디어가 일반화되어 유사성 계산(예: Jaccard 거리 문제)에 적용될 수 있으며 궁극적으로 정확한 광고 배치, 제품 추천 등에 적용될 수 있음을 의미합니다.
또한 로드 밸런싱에도 일관된 해싱을 적용할 수 있습니다. 각 서버가 로드 압력을 균등하게 공유할 수 있도록 하려면 좋은 해시 알고리즘도 이를 수행할 수 있습니다.
위 내용은 해시--일반적인 알고리즘 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!