
Python 개발 - 프로세스, 스레드 및 코루틴에 대한 자세한 설명

- 零下一度원래의
- 2017-06-27 09:57:521647검색
프로세스란 무엇인가요?
프로그램은 단독으로 실행될 수 없습니다. 프로그램이 메모리에 로드되고 시스템이 리소스를 할당할 때만 실행될 수 있습니다. 프로그램과 프로세스의 차이점은 프로그램은 프로세스의 정적 설명 텍스트인 명령 모음이고 프로세스는 프로그램의 실행 활동이며 동적 개념이라는 것입니다.
스레드란 무엇인가요?
스레드는 운영체제가 작업 스케줄링을 수행할 수 있는 가장 작은 단위입니다. 프로세스에 포함되며 프로세스에서 실제 작동하는 단위입니다. 스레드는 프로세스의 단일 순차적 제어 흐름을 의미하며 여러 스레드가 프로세스에서 동시에 실행될 수 있으며 각 스레드는 서로 다른 작업을 병렬로 수행합니다.
프로세스와 스레드의 차이점은 무엇인가요?
스레드는 메모리 공간을 공유하며 프로세스의 메모리는 독립적입니다.
동일 프로세스의 스레드는 서로 직접 통신할 수 있지만 두 프로세스는 중간 에이전트를 통해 서로 통신해야 합니다.
새 스레드를 만드는 것은 매우 간단합니다. 새 프로세스를 만들려면 상위 프로세스를 복제해야 합니다.
스레드는 동일한 프로세스의 다른 스레드를 제어하고 작동할 수 있지만 프로세스는 하위 프로세스만 작동할 수 있습니다.
Python GIL (Global Interpreter Lock)
열린 스레드 수와 CPU 수에 관계없이 Python은 실행 시 동시에 하나의 스레드만 허용합니다.
Python 스레딩 모듈
직접 호출
- import threading, time
- def run_num(num):
- """
- 정의 스레드에 의해 실행되는 함수
- :param num:
- :return:
- """
- print("실행 중 번호:% s"%num)
- time.sleep(3)
- if __name__ == '__main__':
- # 생성 스레드 인스턴스 t1
- t1 = threading.Thread(target=run_num,args=(1,))
- # 스레드 인스턴스 생성 t2
- t2 = threading.Th read(target=run_num ,args=(2,))
- # 스레드 시작 t1
- t1.start()
-
# 시작 스레드 t2
- t2.start()
-
# 스레드 이름을 가져옵니다. >실행 번호: 1
-
실행 번호: 2
- 가져오기 스레딩, 시간
- )self.num = num# 각 스레드에서 실행할 함수를 정의합니다. 함수 이름은 run이어야 합니다. :print("실행 중인 번호: %s"%self.num)time.sleep(3)if __name__ == '__main__':t1 = MyThread(1)
- t2 = MyThread(2)
t1.start()t2.start ()출력:running on number:1running on number:2class
MyThread(threading.Thread):- self,num):
- .Thread.__init__ (self)
- self.num = num
- (self) :
-
print("thread:% s"%self.num)
-
if__name__ == '__main__':
-
t1 = MyThread(1)
- t2 = MyThread( 2 )
- t1.start()
- t1.join()t2.start()t2.join()출력:실행 번호: 1스레드:1running on number:2thread:2
매개변수 설정의 효과는 다음과 같습니다.
- if __name__ == '__main__':
- t1 = MyThread(1)
- t2 = MyThread(2)
- t1.start()
-
t1.join(2)
- t2.start( )
- t2.join()
- 출력:
- running on number:1
- running 번호:2
- thread: 1
- thread:2
Daemon
기본적으로 메인 스레드는 종료 시 모든 하위 스레드가 끝날 때까지 기다립니다. 메인 스레드가 하위 스레드를 기다리지 않고 종료 시 모든 하위 스레드를 자동으로 종료하도록 하려면 하위 스레드를 백그라운드 스레드(데몬)로 설정해야 합니다. 메소드는 스레드 클래스의 setDaemon() 메소드를 호출하는 것입니다.
- 가져오기 시간,스레딩
- def run(n):
- print("%s".center(20," *") %n)
- time.sleep(2)
- print("done".center(20,"*"))
-
- def main():
- for i in range(5):
- t = threading.Thread(target=run,args=(i,))
- t.start()
- t.join(1)
-
print("시작 스레드",t.getName())
- m = threading.Thread(target=main,args=())
- # 메인 스레드를 프로그램의 메인 스레드의 데몬 스레드 역할을 하는 데몬 스레드로 설정합니다. 메인 스레드가 종료되면 m 스레드도 종료됩니다. 실행 완료 여부에 관계없이 m이 시작한 다른 하위 스레드도 동시에 종료됩니다. m.start()
- m.join(3)
- print("main thread done".center(20,"*"))
- 출력:
- *********0**********
- 스레드 시작 Thread-2
- ************ 1*** ******
- **********완료************
-
스레드 시작 Thread-3
- **** *****2**********
- **메인 스레드 완료**
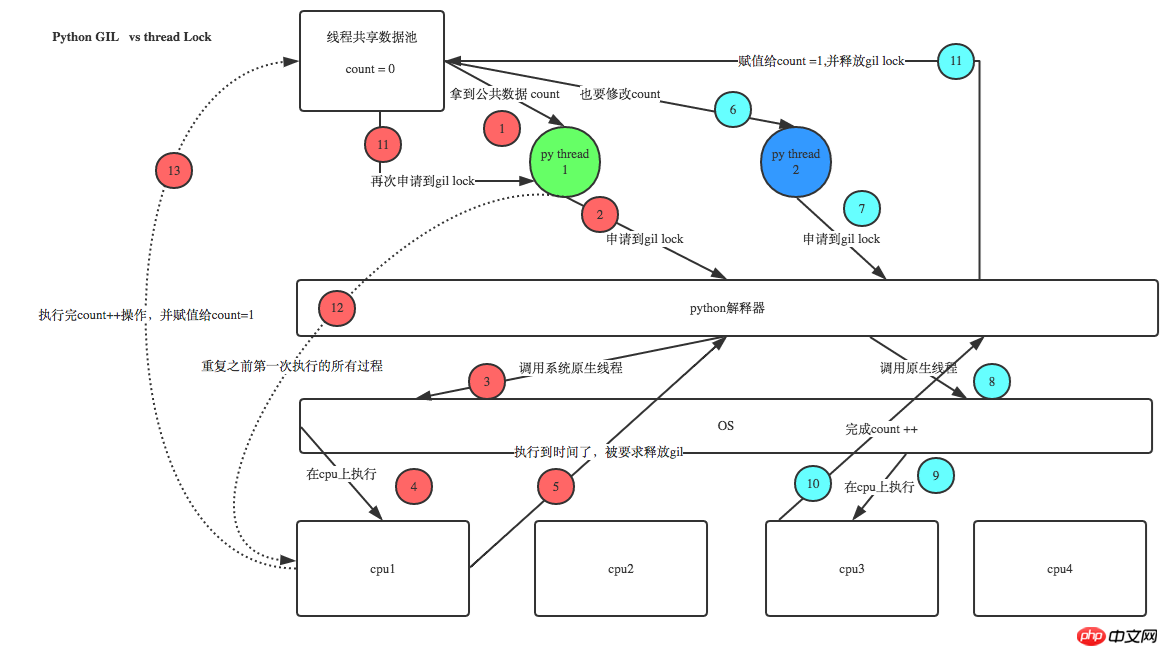
스레드 잠금(Mutex)
One 프로세스는 여러 스레드를 시작할 수 있으며, 여러 스레드는 상위 프로세스의 메모리 공간을 공유합니다. 이는 각 스레드가 동일한 데이터에 액세스할 수 있음을 의미합니다. 이때 두 스레드가 동시에 동일한 데이터를 수정하려는 경우 스레드 잠금이 수행됩니다. 필수의.
- import time,threading
- def addNum():
-
# 각 스레드에서 이 전역 변수를 가져옵니다
- 전역 번호
- num -= 1
- # 공유 변수 설정
- num = 100
- thread_list = []
-
for i in범위(100):
-
t = threading.Thread(target=addNum)
-
t.start()
- thread_list.append( t)
- # 모든 스레드의 실행이 완료될 때까지 기다립니다.
-
for t inthread_list:
-
t.join()
- 인쇄 ("최종 숫자:" ,num)잠긴 버전
- Lock은 다른 스레드가 공유 리소스에 액세스하는 것을 차단하며 동일한 스레드는 한 번만 획득할 수 있습니다. 프로그램을 계속 실행할 수 없습니다.
- import time,threading
-
def addNum():
- 전역 숫자
- print("--get num:",num)
- time.sleep(1)
- # 데이터 수정 전 잠금
- lock.acquire()
- # 이 공용 변수에 대해 -1 연산을 수행합니다
-
숫자 -= 1100
-
thread_list = [ ]
- # 전역 잠금 생성
-
lock= threading.Lock()
- i in 범위(100):
- t = threading.Thread(target=addNum)
- t.start()
- (티)# 모든 스레드가 완료될 때까지 기다리세요
-
fort in
- thread_list:
- t.join()
-
인쇄( "final num:
- ",num) GIL VS LockGIL은 동시에 하나의 스레드만 실행할 수 있도록 보장합니다. 잠금은 사용자 수준 잠금이며 GIL과 관련이 없습니다.
-
RLock(재귀 잠금)Rlock을 사용하면 동일한 스레드에서 여러 번 획득할 수 있습니다. 스레드가 공유 리소스를 해제하려면 모든 잠금을 해제해야 합니다. 즉, n번의 획득에는 n번의 해제가 필요합니다.
- def run1():
-
print("첫 번째 부분 데이터 가져오기 ")
.acquire() lock
lock- 전역 숫자ㅋㅋㅋ
- def run2():print(" 두 번째 부분 데이터 가져오기
- ")
- .acquire()
- global num2
- 숫자2 += 1
- .release()
- num2
- def run3():
- lock.acquire()
-
res = run1()
- print("run1과 run2".center(50,"*"))
- res2 = run2()
- lock.release()
- 인쇄(res,res2 )
- if __name__ == '__main__':
- num,num2 = 0,0
- lock = threading.RLock()
- for i in 범위(10):
- t = threading.Thread(target=run3)
- t.start()
- while threading.active_count() != 1:
- print(threading.active_count())
-
else:
- 인쇄(" 모든 스레드 완료".center(50,"*"))
- print(num,num2)
这两种锁的主要区别是线程中被多次acquire.而Lock却不允许这种情况。注意,如果使用RLock,那么acquireandrelease必须成对了n次acquire,必须调用n次的release才能真正释放所?锁。
세마포어(信号weight)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数weight线程更改数敍,比如售票处는 3个窗口,那最多只允许3个人同时买票,后면的人只能等前面任意窗口的人离开才能买票。
- import threading,time
-
def run(n):
- semaphore.acquire( )
- time.sleep(1)
- print("스레드 실행:%s"%n)
- semaphore.release()
- if __name__ == '__main__':
- # 最多允许5个线程同时运行
- 세마포어 = threading.BoundedSemaphore(5)
- for i in 범위(20):
- t = threading.Thread(target=run,args=(i,))
- t.start()
- while 카운트() != 1:
- # print(threading.active_count())
- pass
- else:
- print(" all thread done ".center(50,"*"))
Timer(타이머)
Timer는 일정한 간격으로 함수를 호출합니다. 일정한 간격으로 함수를 호출하려면 다음을 호출해야 합니다. 타이머 기능에서 타이머를 다시 설정하세요. 타이머는 Thread의 파생 클래스입니다.
- import threading
- def hello():
-
print("hello, world!")
- # 5초 후 지연 Hello 함수 실행
- t = threading.Timer(5,hello)
- t.start()
Event
Python은 스레드 간 통신을 위한 Event 객체를 제공합니다. 스레드에 의해 설정된 신호 플래그입니다. 신호 플래그 비트가 거짓이면 스레드는 다른 스레드에 의해 명령 신호가 참으로 설정될 때까지 기다립니다. Event 개체는 스레드 간의 통신을 실현하기 위한 간단한 스레드 통신 메커니즘을 구현합니다.
신호 설정
Event의 set() 메서드를 사용하여 Event 개체 내부의 신호 플래그를 true로 설정합니다. Event 객체는 내부 신호 플래그의 상태를 결정하기 위해 isSet() 메서드를 제공합니다. 이벤트 객체의 set() 메서드가 사용되면 isSet() 메서드는 true를 반환합니다.
Clear the signal
Event객체 내부의 signal flag를 클리어하려면 Event의clear()메소드를 사용합니다. 즉, Event의clear()메소드를 사용하면 isSet이 됩니다. () 메서드는 false를 반환합니다.
Waiting
Event의 wait() 메서드는 내부 신호가 true인 경우에만 빠르게 반환을 실행하고 완료합니다. Event 객체의 내부 신호 플래그가 false인 경우 wait() 메서드는 반환하기 전에 해당 플래그가 true가 될 때까지 기다립니다.
이벤트를 사용하여 두 개 이상의 스레드 간의 상호 작용을 구현해 보겠습니다. 즉, 신호등 역할을 하는 스레드를 시작하고 차량 역할을 하는 여러 스레드를 생성하면 차량이 그에 따라 주행합니다. 빨간색 정지와 녹색 규칙으로 이동하세요.
- import 스레딩,시간,random
- def light():
- if 이벤트 . isSet():
-
if 개수 < 5:
- 인쇄("elif 개수 < 8:print(" 33[43;1m--노란색 표시등 켜짐-- 33[0m".center(50,"*"))elif 개수 < ; 13:ifevent.isSet():event()print(" 33[41;1m--red 불 켜기-- 33[0m".center(50,"*"))else:개수 = 0이벤트. set()time.sleep(1)count += 1def car(n):while 1:time.sleep(random.randrange(10))if event.isSet():인쇄( "%s 자동차가 달리고 있습니다..."%n)else:print(" %s 자동차가 빨간불을 기다리고 있습니다..."% n)if __name__ == "__main__":event = threading.Event()빛 = 스레딩.스레드 (대상=빛,)Light.start()for i in 범위(3):t = 스레딩.스레드 (target=car,args=(i,))t.start()
queue queue
Python의 대기열은 스레드 간 데이터 교환에 가장 일반적으로 사용되는 형식입니다. Queue 모듈은 Queue 작업을 제공하는 모듈입니다.
큐 객체 생성
- import queue
- q = queue.Queue(maxsize = 10)
queue.Queue 클래스는 큐 동기화 실현입니다. 대기열 길이는 무제한이거나 제한될 수 있습니다. 큐 길이는 Queue 생성자의 선택적 매개변수 maxsize를 통해 설정할 수 있습니다. maxsize가 1보다 작으면 대기열 길이는 무제한입니다.
큐에 값을 넣습니다
- q.put("a")
큐 객체의 put() 메서드를 호출하여 큐 끝에 항목을 삽입합니다. put()에는 두 개의 매개변수가 있습니다. 첫 번째 항목은 삽입된 항목의 값이며 두 번째 블록은 선택적 매개변수이며 기본값은 1입니다. 대기열이 현재 비어 있고 블록이 1인 경우 put() 메서드는 데이터 단위가 해제될 때까지 호출 스레드를 일시 중지합니다. block이 0이면 put() 메서드는 Full 예외를 발생시킵니다.
큐에서 값 제거
- q.get()
큐 객체의 get() 메서드를 호출하여 큐의 헤드에서 항목을 삭제하고 반환합니다. 선택적 매개변수는 block이며 기본값은 True입니다. 대기열이 비어 있고 block이 True인 경우 get()은 항목을 사용할 수 있을 때까지 호출 스레드를 일시 중지합니다. 큐가 비어 있고 블록이 False인 경우 큐는 비어 있음 예외를 발생시킵니다.
Python 대기열 모듈에는 세 개의 대기열과 생성자가 있습니다
- # 선입선출
- class queue.Queue(maxsize=0)
- # 선입선출
- class queue.LifoQueue(maxsize=0)
- # 우선순위 큐 레벨이 낮을수록 먼저 나옵니다
- class queue.Priority 대기열(최대 크기 =0)
Commonmethods
- q = queue.Queue()
- # 대기열의 크기를 반환합니다
- q.qsize()
- # 대기열이 비어 있으면 True를 반환하고 그렇지 않으면 False를 반환합니다
- q.empty()
- # 대기열이 가득 차면 True를 반환하고 그렇지 않으면 False를 반환합니다
- q .full()
- # 대기열 가져오기, 대기 시간 제한 시간
- q.get([block[,timeout]])
- # q.과 동일 get(False)
- q.get_nowait()
- # 다른 작업을 수행하기 전에 대기열이 빌 때까지 기다리세요
- q.join()
생산자-소비자 모델
개발 및 프로그래밍에서 생산자와 소비자 패턴을 사용하면 대부분의 동시성 문제를 해결할 수 있습니다. 이 모드는 프로덕션 스레드와 소비자 스레드의 작업 성능 균형을 유지하여 프로그램의 전반적인 데이터 처리 속도를 향상시킵니다.
생산자와 소비자 모델을 사용하는 이유
스레드 세계에서 생산자는 데이터를 생성하는 스레드이고 소비자는 데이터를 소비하는 스레드입니다. 멀티 스레드 개발에서 생산자의 처리 속도가 매우 빠르고 소비자의 처리 속도가 매우 느린 경우 생산자는 데이터 생성을 계속하기 전에 소비자가 처리를 마칠 때까지 기다려야 합니다. 마찬가지로 소비자의 처리 능력이 생산자의 처리 능력보다 크면 소비자는 생산자를 기다려야 합니다. 이러한 문제를 해결하기 위해 생산자 모델과 소비자 모델이 등장했습니다.
생산자-소비자 패턴이란 무엇인가요?
생산자-소비자 패턴은 컨테이너를 사용하여 생산자와 소비자 간의 강력한 결합 문제를 해결합니다. 생산자와 소비자는 서로 직접 통신하지 않고 차단 대기열을 통해 통신하므로 생산자가 데이터를 생성한 후 더 이상 소비자가 이를 처리할 때까지 기다리지 않고 소비자가 직접 차단 대기열에 넣습니다. 생산자에게 데이터를 요청하지만 차단 대기열에서 직접 가져옵니다. 차단 대기열은 생산자와 소비자의 처리 기능의 균형을 맞추는 버퍼와 동일합니다.
생산자-소비자 모델의 가장 기본적인 예입니다.
- import queue,threading,time
- q = queue.Queue(maxsize=10)
- def 프로듀서():
- Count = 1
- while True:
- q.put("bone %s"%count)
- print(" 생산된 뼈 " ,count)
- count += 1
- def 소비자(이름):
- 동안 q.qsize() >인쇄 ("%[%s]가 [%s]을(를) 얻어서 먹어요... "%(name, q.
- get())) time.sleep ( 1)
- p = threading.Thread(target=Producer,)
-
c1 = threading.Thread(target=Consumer,args=("번영 ",) )
-
c2 = threading.Thread(target=Consumer,args=("来福 ",))
- p.start()
- c1.start( )
- c2.start()
위 내용은 Python 개발 - 프로세스, 스레드 및 코루틴에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
이전 기사:Django 기본 튜토리얼 요약다음 기사:Django 기본 튜토리얼 요약
 lock
lock