
Python의 빅데이터 처리에 대한 자세한 설명

- 零下一度원래의
- 2017-06-27 10:37:395094검색
Share

지식 포인트:
lubridate 패키지 분해 시간 | POSIXlt
결정 트리 분류 사용, 랜덤 포레스트 예측 사용
맞춤에 로그 사용 및 exp 함수 감소
훈련 세트는 Kaggle Washington Bike Sharing에서 제공 공유 자전거, 날씨, 시간 등의 관계를 분석하기 위한 계획된 자전거 대여 데이터 데이터 세트에는 총 11개의 변수와 10,000개 이상의 데이터 행이 있습니다.
우선 공식 데이터를 살펴보겠습니다. 두 개의 테이블이 있는데, 둘 다 2011년부터 2012년까지의 데이터입니다. 차이점은 테스트 파일에 매월 날짜가 모두 포함되어 있지만 등록된 사용자가 없다는 것입니다. 그리고 일반 사용자. Train 파일에는 한 달에 1~20일만 있지만 사용자에는 두 가지 유형이 있습니다.
해결 방법: Train 파일에서 21~30명의 사용자 수를 완성하세요. 평가 기준은 예측과 실제 수량을 비교하는 것입니다.

먼저 파일과 패키지를 로드하세요
library(lubridate)library(randomForest)library(readr)setwd("E:")
data<-read_csv("train.csv")head(data)여기서 R 언어의 기본 read.csv를 사용하여 올바른 파일 형식을 읽을 수 없다는 문제가 발생했습니다. xlsx로 변경하면 항상 43045와 같은 이상한 숫자가 됩니다. 이전에 as.Date를 시도해 보았는데 정확하게 변환이 되지만 이번에는 분, 초가 있어서 타임스탬프만 사용할 수 있는데 결과도 좋지 않습니다.
마지막으로 "readr" 패키지를 다운로드하고 read_csv 문을 사용하여 원활하게 해석했습니다.
테스트 날짜는 열차보다 완전하지만 사용자 수가 누락되었기 때문에 열차와 테스트를 병합해야 합니다.
test$registered=0test$casual=0test$count=0 data<-rbind(train,test)
시간 추출: 타임스탬프를 사용할 수 있습니다. 여기서 시간은 비교적 간단하며 시간 수이므로 문자열을 직접 가로챌 수도 있습니다.
data$hour1<-substr(data$datetime,12,13) table(data$hour1)
시간당 총 사용량을 계산하면 다음과 같습니다(왜 깔끔합니까):

다음 단계는 상자 그림을 사용하여 사용자와 시간을 살펴보는 것입니다. , 주 이러한 관계 중 일부입니다. 히스토그램 대신 박스 플롯을 사용하는 이유는 무엇입니까? 박스 플롯은 이산적인 점 표현을 가지므로 로그를 사용하여 적합성을 찾습니다.
그림에서 알 수 있듯이 시간 측면에서 등록 사용자와 비등록 사용자의 사용 시간은 다음과 같습니다. 매우 다릅니다.
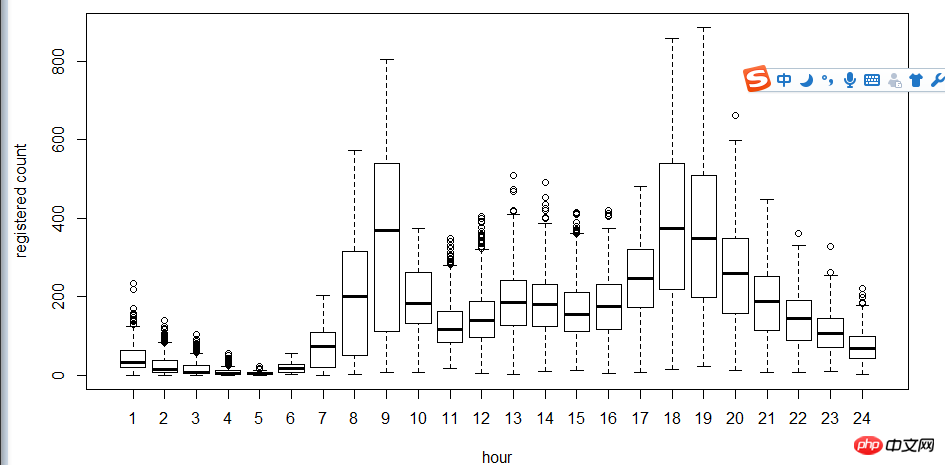
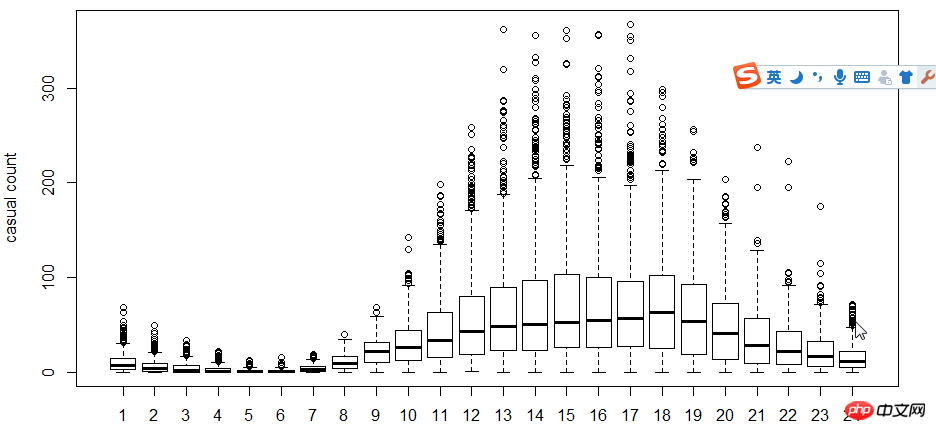
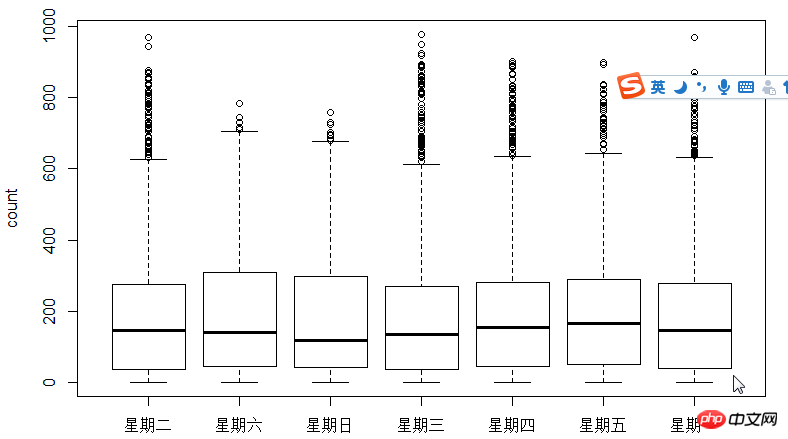
다음으로 상관 계수 cor를 사용하여 테스트합니다 사용자, 온도, 인지된 온도, 습도, 풍속 간의 관계.
상관 계수: 변수 간의 선형 연관성 측정으로, 서로 다른 데이터 간의 상관 정도를 테스트합니다.
값 범위는 [-1, 1]입니다. 0에 가까울수록 관련성이 떨어집니다.
계산 결과를 보면 사용자 수는 기온보다 풍속이 더 큰 영향을 미치는 음의 상관관계가 있음을 알 수 있습니다.

다음 단계는 의사결정 트리를 이용하여 시간 등의 요소를 분류한 후 랜덤 포레스트를 이용하여 예측하는 것입니다. 랜덤 포레스트 및 의사결정 트리에 대한 알고리즘. 아주 고급스럽게 들리지만 실제로는 현재 매우 일반적으로 사용되므로 꼭 배워야 합니다.
의사결정 트리 모델은 간단하고 사용하기 쉬운 비모수적 분류기입니다. 데이터에 대한 사전 가정이 필요하지 않고, 계산이 빠르고, 결과를 해석하기 쉽고, 견고하고 시끄러운 데이터와 누락된 데이터를 두려워하지 않습니다.
의사결정나무 모델의 기본 계산 단계는 다음과 같습니다. 먼저 n개의 독립변수 중 하나를 선택하고, 최적의 분할점을 찾은 후, 데이터를 두 그룹으로 나눕니다. 그룹화된 데이터에 대해 특정 조건이 충족될 때까지 위 단계를 반복합니다.
의사결정 트리 모델링에서 해결해야 할 세 가지 중요한 문제는 다음과 같습니다.
독립변수 선택 방법
분할점 선택 방법
분할 중지 조건 결정
등록된 사용자 및 시간에 대한 의사결정 트리 만들기,
train$hour1<-as.integer(train$hour1)d<-rpart(registered~hour1,data=train)rpart.plot(d)
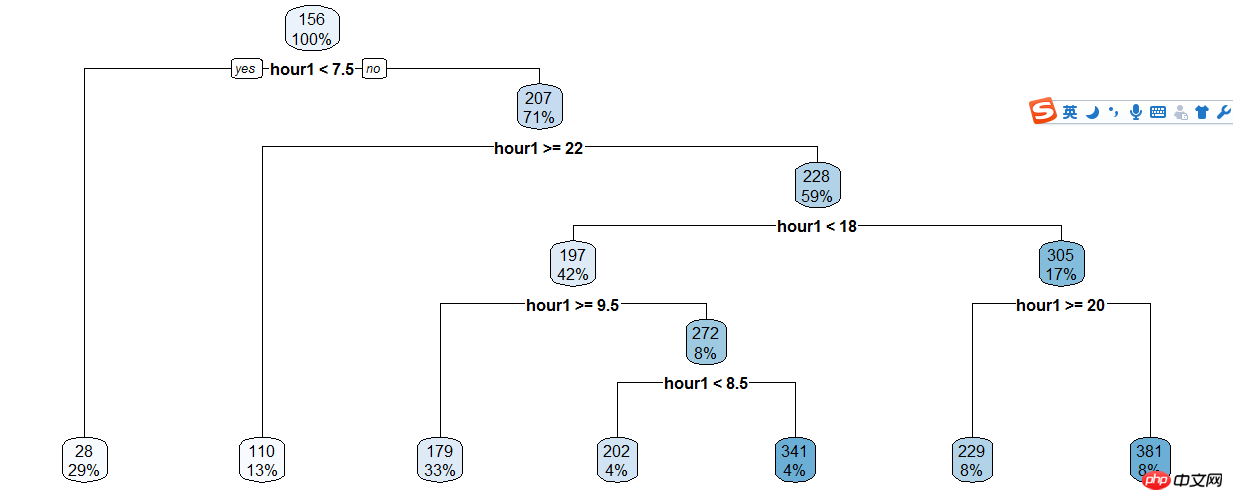
그런 다음 의사결정 트리 결과에 따라 수동으로 분류하기 때문에 여전히 많은 코드를 차지합니다...
train$hour1<-as.integer(train$hour1)data$dp_reg=0data$dp_reg[data$hour1<7.5]=1data$dp_reg[data$hour1>=22]=2data$dp_reg[data$hour1>=9.5 & data$hour1<18]=3data$dp_reg[data$hour1>=7.5 & data$hour1<18]=4data$dp_reg[data$hour1>=8.5 & data$hour1<18]=5data$dp_reg[data$hour1>=20 & data$hour1<20]=6data$dp_reg[data$hour1>=18 & data$hour1<20]=7
마찬가지로 make (hour | 온도) X (등록 | 임의 사용자) 결정 트리를 기다리고 수동 분류를 계속합니다....
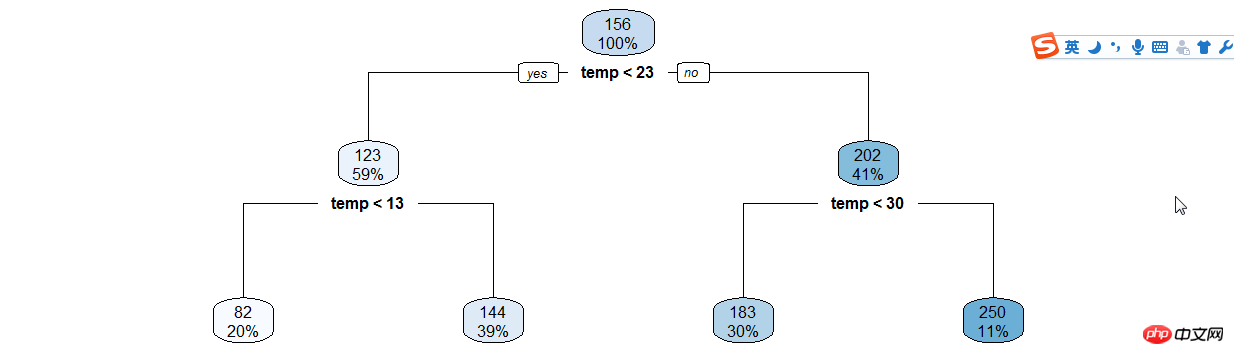
年份月份,周末假日等手动分类
data$year_part=0data$month<-month(data$datatime)data$year_part[data$year=='2011']=1data$year_part[data$year=='2011' & data$month>3]=2data$year_part[data$year=='2011' & data$month>6]=3data$year_part[data$year=='2011' & data$month>9]=4
data$day_type=""data$day_type[data$holiday==0 & data$workingday==0]="weekend"data$day_type[data$holiday==1]="holiday"data$day_type[data$holiday==0 & data$workingday==1]="working day"data$weekend=0data$weekend[data$day=="Sunday"|data$day=="Saturday"]=1
接下来用随机森林语句预测
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,再在其中选取最优的特征。这样决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
ntree指定随机森林所包含的决策树数目,默认为500,通常在性能允许的情况下越大越好;
mtry指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。一般是需要进行人为的逐次挑选,确定最佳的m值—摘自datacruiser笔记。这里我主要学习,所以虽然有10000多数据集,但也只定了500。就这500我的小电脑也跑了半天。
train<-dataset.seed(1234) train$logreg<-log(train$registered+1)test$logcas<-log(train$casual+1) fit1<-randomForest(logreg~hour1+workingday+day+holiday+day_type+temp_reg+humidity+atemp+windspeed+season+weather+dp_reg+weekend+year+year_part,train,importance=TRUE,ntree=250) pred1<-predict(fit1,train) train$logreg<-pred1
这里不知道怎么回事,我的day和day_part加进去就报错,只有删掉这两个变量计算,还要研究修补。
然后用exp函数还原
train$registered<-exp(train$logreg)-1 train$casual<-exp(train$logcas)-1 train$count<-test$casual+train$registered
最后把20日后的日期截出来,写入新的csv文件上传。
train2<-train[as.integer(day(data$datetime))>=20,]submit_final<-data.frame(datetime=test$datetime,count=test$count)write.csv(submit_final,"submit_final.csv",row.names=F)
大功告成!
github代码加群
原来的示例是炼数成金网站的kaggle课程第二节,基本按照视频的思路。因为课程没有源代码,所以要自己修补运行完整。历时两三天总算把这个功课做完了。下面要修正的有:
好好理解三个知识点(lubridate包/POSIXlt,log线性,决策树和随机森林);
用WOE和IV代替cor函数分析相关关系;
用其他图形展现的手段分析
随机树变量重新测试学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入学习交流群
626062078,我们一起学Python!
完成了一个“浩大完整”的数据分析,还是很有成就感的!
위 내용은 Python의 빅데이터 처리에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!