
크롤러&문제 해결&사고
- 巴扎黑원래의
- 2017-06-23 14:47:361611검색
최근에 Python을 접하게 되었는데, 실전에서 계속해서 문제 해결 능력을 발휘할 수 있기를 바랍니다. 이 작은 크롤러는 MOOC 강좌에서 나온 것입니다. 제가 여기에 기록하는 것은 제가 학습 과정에서 겪은 문제와 해결책, 그리고 크롤러 외부의 생각입니다.
이 작은 작업은 작은 크롤러를 작성하는 것입니다. 제가 이것을 실천하기로 선택한 가장 중요한 이유는 현재 우한의 날씨처럼 빅데이터가 너무 뜨겁기 때문입니다. 데이터는 군인에게 무기가, 고층빌딩에 벽돌과 타일이 존재하는 '빅데이터'이다. 데이터가 없으면 '빅데이터'는 하늘에 떠 있는 로프일 뿐, 실천할 수 없고 실제로 적용할 수도 없습니다. 데이터는 어디에서 오는가? 두 가지 방법이 있는데, 하나는 자신에게서 가져오는 것이고, 다른 하나는 다른 사람에게서 가져오는 것입니다. 말할 필요도 없이 다른 방법은 다른 사람에게서 물건을 가져오는 것이며, 이 "타자"는 인터넷을 의미합니다.
우선 크롤러를 이해해야 합니다. 특정 규칙에 따라 World Wide Web 정보를 자동으로 크롤링하는 프로그램 또는 스크립트(Baidu Encyclopedia에서 제공) . 이름에서 알 수 있듯이 페이지를 방문하여 페이지에 있는 콘텐츠를 저장한 다음, 저장된 페이지에서 관심 있는 콘텐츠를 필터링한 다음 별도로 저장해야 합니다. 실생활에서 우리는 종종 이런 일을 합니다. 지루한 오후에 브라우저에 주소를 입력하여 페이지에 액세스한 다음 관심 있는 기사나 단락을 발견하고 선택하고 복사하여 단어에 붙여넣습니다. 문서. . 위의 한 페이지에 대해 수행한 작업을 수백만 페이지에 수행하면 데이터가 점점 더 커질 것입니다. 이 프로세스를 "데이터 수집"이라고 합니다.
크롤러의 장점은 자동화 및 일괄 처리입니다. 여기서 오해가 있을 수 있습니다. 크롤러를 접하기 전에는 크롤러가 내가 "볼 수 없는" 것을 크롤링할 수 있다고 생각했습니다. 나중에 크롤러는 내가 "볼 수 없는" 것을 크롤링하는 데 사용된다는 것을 깨달았습니다.
다음은 이 크롤러의 아키텍처와 크롤링 과정입니다
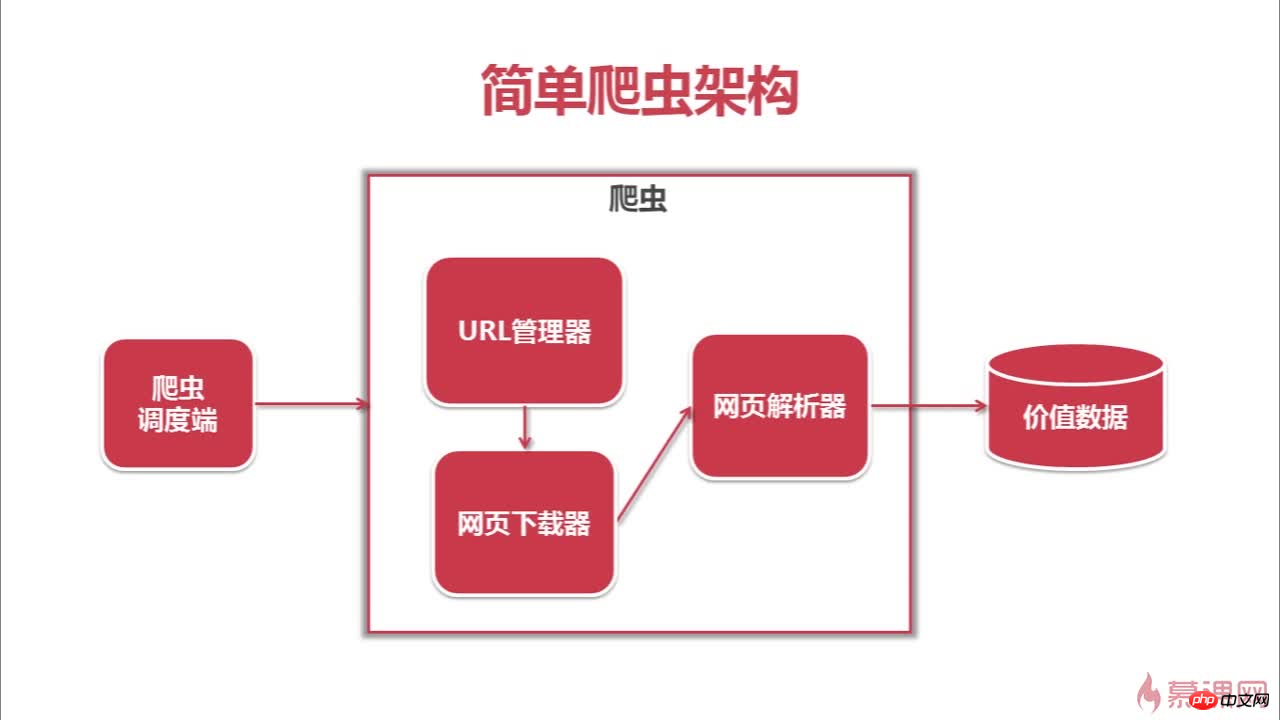
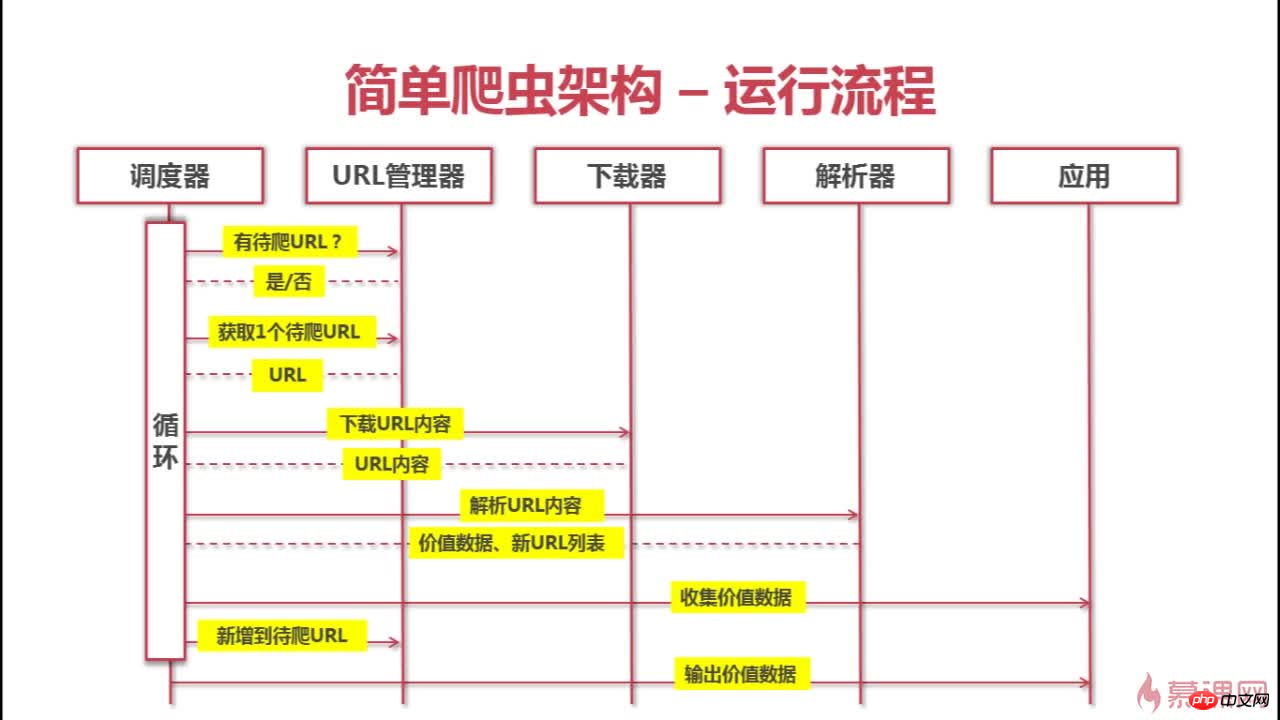
위 내용은 크롤러&문제 해결&사고의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!