
집 >데이터 베이스 >MySQL 튜토리얼 >데이터베이스 테이블 디자인-인접 목록, 경로 열거, 중첩 세트, 클로저 테이블
데이터베이스 테이블 디자인-인접 목록, 경로 열거, 중첩 세트, 클로저 테이블
- 巴扎黑원래의
- 2017-06-23 15:05:364263검색
데이터베이스를 디자인할 때 관습을 깨고 우리 요구 사항에 가장 적합한 디자인 솔루션을 찾을 수 있을까요? 다음은 예입니다.
일반적으로 사용되는 인접 테이블 디자인에는 지역 테이블과 같은 parent_id 필드가 추가됩니다. (국가, 도, 시, 구):
CREATE TABLE Area ([id] [int] NOT NULL,[name] [nvarchar] (50) NULL,[parent_id] [int] NULL,[type] [int] NULL );
name: 지역 이름, parent_id는 상위 ID, 해당 지역의 상위 ID는 국가, 해당 지역의 상위 ID city는 지방 등입니다.
type은 지역의 레벨: 1:국가, 2:도, 3:시, 4:군
레벨이 상대적으로 확실할 때 이렇게 테이블을 디자인하는데 문제가 없고, 전화하는 것이 매우 편리합니다.
그러나 이 인접 목록 설계 방법을 사용하면 모든 요구 사항을 충족할 수 없습니다. 수준이 확실하지 않은 경우 다음 주석 구조가 있다고 가정합니다.
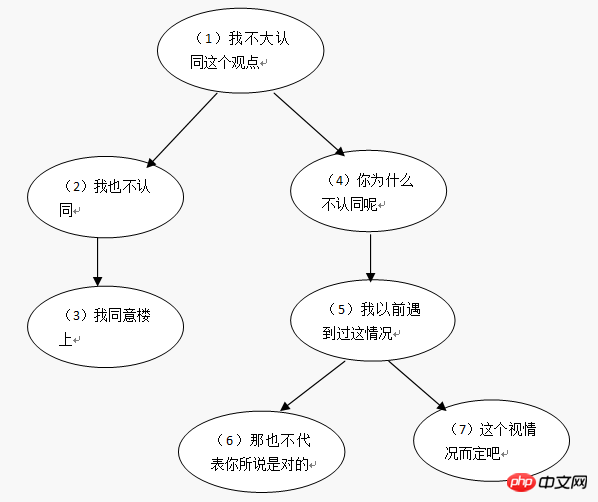
이에 대한 인접 목록 레코드 데이터 사용 댓글(댓글 테이블):
| comment_id | parent_id | author | comment |
| 1 | 0 | 샤오밍 | 별로 동의하지 않습니다 나는 이 견해에 동의하지 않는다 |
| 2 | 1 | Xiao Zhang | 나도 동의하지 않는다 |
| 3 | 2 | Xiaohong | 위층 사람의 의견에 동의한다 |
| 4 | 1 | Xiaoquan | 왜 동의하지 않나요 |
| 5 | 4 | Xiao Ming | 저는 이런 상황을 겪은 적이 있습니다 |
| 6 | 5 | 샤오 장 | 그렇다고 말씀하신 것이 옳다는 것은 아닙니다 |
| 7 | 5 | Xiaoxin | 이건 상황에 따라 다릅니다 |
이렇게 디자인한 테이블은 어렵다는 걸 아셨나요? 노드의 모든 하위 항목을 쿼리하려면 관련 쿼리를 사용하여 주석과 해당 하위 항목을 가져올 수 있습니다.
SELECT c1.*, c2.* FROM comments c1 LEFT OUTER JOIN comments c2 ON c2.parent_id = c1.comment_id;
그러나 이 쿼리는 두 가지 수준의 데이터만 가져올 수 있습니다. 이러한 종류의 트리의 특징은 어떤 깊이로든 확장할 수 있으며 깊이 데이터를 얻으려면 해당 방법이 필요하다는 것입니다. 예를 들어 주석 분기 수를 계산하거나 기계 부품의 총 비용을 계산해야 할 수 있습니다.
어떤 경우에는 프로젝트에서 인접 목록을 사용하는 것이 적합합니다. 인접 목록 설계의 장점은 주어진 노드의 직접 부모 노드와 자식 노드를 빠르게 얻을 수 있고, 새로운 노드를 삽입하기도 쉽다는 것입니다. 이러한 요구 사항이 계층적 데이터에 대한 프로젝트의 모든 작업인 경우 인접 목록을 사용하면 잘 작동합니다.
위의 트리 모델을 접할 때 고려할 수 있는 몇 가지 옵션이 있습니다: 경로 열거, 중첩 세트 및 클로저 테이블. 이러한 솔루션은 종종 인접 목록보다 훨씬 더 복잡해 보이지만 인접 목록을 사용하기가 복잡하거나 비효율적인 특정 작업을 더 쉽게 만듭니다. 프로젝트에서 실제로 이러한 작업을 제공해야 하는 경우 이러한 디자인은 인접 목록에 더 나은 선택이 될 것입니다.
1. 경로 열거
주석 테이블에서 원래 parent_id 필드를 대체하기 위해 varchar 유형의 경로 필드를 사용합니다. 이 경로 필드에 저장된 콘텐츠는 현재 노드의 최상위 상위 항목부터 자체 시퀀스까지의 시퀀스입니다. UNIX 경로와 마찬가지로 '/'를 경로 구분 기호로 사용할 수도 있습니다.
| comment_id | path | author | comment |
| 1 | 1 | 샤오밍 | 저는 이 견해에 별로 동의하지 않습니다 |
| 2 | 1/2 | Xiao Zhang | 저도 동의하지 않습니다 |
| 3 | 1/2/3 | Xiaohong | 위 내용에 동의합니다 |
| 4 | 1 /4 | 작은전 | 동의하지 않으세요 |
| 5 | 1/4/5 | Xiao Ming | 저는 이런 상황을 겪은 적이 있습니다 |
| 6 | 1/4/5 /6 | 샤오장 | 네 말이 맞다는 건 아니야 |
| 7 | 1/4/5/7 | Xiaoxin | 상황에 따라 다름 |
你可以通过比较每个节点的路径来查询一个节点祖先。比如:要找到评论#7, 路径是 1/4/5/7一 的祖先,可以这么做:
SELECT * FROM comments AS c WHERE '1/4/5/7' LIKE c.path || '%' ;
这句话查询语句会匹配到路径为 1/4/5/%,1/4/% 以及 1/% 的节点,而这些节点就是评论#7的祖先。
同时还可以通过将LIKE 关键字两边的参数互换,来查询一个给定节点的所有后代。比如查询评论#4,路径path为 ‘1/4’ 的所有后代,可以使用如下语句:
SELECT * FROM comemnts AS c WHERE c.path LIKE '1/4' || '%' ;
这句查询语句所有能找到的后台路径分别是:1/4/5、1/4/5/6、1/4/5/7。
一旦你可以很简单地获取一棵子树或者从子孙节点到祖先节点的路径,你就可以很简单地实现更多的查询,如查询一颗子树所有节点上值的总和。
插入一个节点也可以像使用邻接表一样地简单。你所需要做的只是复制一份要插入节点的父亲节点路径,并将这个新节点的ID追加到路径末尾即可。
路径枚举也存在一些缺点,比如数据库不能确保路径的格式总是正确或者路径中的节点确实存在。依赖于应用程序的逻辑代码来维护路径的字符串,并且验证字符串的正确性开销很大。无论将varchar 的长度设定为多大,依旧存在长度的限制,因而并不能够支持树结构无限扩展。
二、 嵌套集
嵌套集解决方案是存储子孙节点的相关信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,从而表示这一信息,可以将这两个数字称为nsleft 和 nsright。
每个节点通过如下的方式确定nsleft 和nsright 的值:nsleft的数值小于该节点所有后代ID,同时nsright 的值大于该节点的所有后代的ID。这些数字和comment_id 的值并没有任何关联。
确定这三个值(nsleft,comment_id,nsright)的简单方法是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值。得到数据如下:

| comment_id | nsleft | nsright | author | comment |
| 1 | 1 | 14 | 小明 | 我不大认同这个观点 |
| 2 | 2 | 5 | 小张 | 我也不认同 |
| 3 | 3 | 4 | 小红 | 我同意楼上 |
| 4 | 6 | 13 | 小全 | 你为什么不认同呢 |
| 5 | 7 | 12 | 小明 | 我以前遇到过这情况 |
| 6 | 8 | 9 | 小张 | 那也不代表你所说是对的 |
| 7 | 10 | 11 | 小新 | 这个视情况而定吧 |
一旦你为每个节点分配了这些数字,就可以使用它们来找到指定节点的祖先和后代。比如搜索评论#4及其所有后代,可以通过搜索哪些节点的ID在评论 #4 的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c2.nsleft BETWEEN c1.nsleftAND c1.nsright WHERE c1.comment_id = 4;
比如搜索评论#6及其所有祖先,可以通过搜索#6的ID在哪些节点的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c1.nsleft BETWEEN c2.nsleftAND c2.nsright WHERE c1.comment_id = 6;
使用嵌套集设计的主要优势是,当你想要删除一个非叶子节点时,它的后代会自动替代被删除的节点,成为其直接祖先节点的直接后代。就是说已经自动减少了一层。
然而,某些在邻接表的设计中表现得很简单的查询,比如获取一个节点的直接父亲或者直接后代,在嵌套集设计中会变得比较复杂。在嵌套集中,如果需要查询一个节点的直接父亲,我们会这么做,比如要找到评论#6 的直接父亲:
SELECT parent.* FROM comments AS c JOIN comments AS parent ON c.nsleft BETWEEN parent.nsleft AND parent.nsrightLEFT OUTER JOIN comments AS in_between ON c.nsleft BETWEEN in_between.nsleft AND in_between.nsrightAND in_between.nsleft BETWEEN parent.nsleft AND parent.nsright WHERE c.comment_id = 6AND in_between.comment_id IS NULL;
总之有些复杂。
对树进行操作,比如插入和移动节点,使用嵌套集会比其它设计复杂很多。当插入一个新节点时,你需要重新计算新插入节点的相邻兄弟节点、祖先节点和它祖先节点的兄弟,来确保他们的左右值都比这个新节点的左值大。同时,如果这个新节点时一个非叶子节点,你还要检查它的子孙节点。
如果简单快速查询是整个程序中最重要的部分,嵌套集是最好的选择,比操作单独的节点要方便快捷很多。然而,嵌套集的插入和移动节点是比较复杂的,因为需要重新分配左右值,如果你的应用程序需要频繁的插入、删除节点,那么嵌套集可能并不合适。
三、闭包表
闭包表是解决分级存储的一个简单而优雅的解决方案,它记录了树中所有节点间的关系,而不仅仅只有那些直接的父子节点。
在设计评论系统时,我们额外创建了一个叫 tree_paths 表,它包含两列,每一列都指向 comments 中的外键。
我们不再使用comments 表存储树的结构,而是将树中任何具有(祖先 一 后代)关系的节点对都存储在treepaths 表里,即使这两个节点之间不是直接的父子关系;同时,我们还增加一行指向节点自己。
| 祖先 | 后代 | 祖先 | 后代 | 祖先 | 后代 | 祖先 | 后代 |
| 1 | 1 | 1 | 7 | 4 | 6 | 7 | 7 |
| 1 | 2 | 2 | 2 | 4 | 7 | ||
| 1 | 3 | 2 | 3 | 5 | 5 | ||
| 1 | 4 | 3 | 3 | 5 | 6 | ||
| 1 | 5 | 4 | 4 | 5 | 7 | ||
| 1 | 6 | 4 | 5 | 6 | 6 |
通过treepaths 表来获取祖先和后代比使用嵌套集更加的直接。例如要获取评论#4的后代,只需要在 treepaths 表中搜索祖先是评论 #4的行就行了。同样获取后代也是如此。
要插入一个新的叶子节点,比如评论#6的一个子节点,应首先插入一条自己到自己的关系,然后搜索 treepaths 表中后代是评论#6 的节点,增加该节点和新插入节点的“祖先一后代”关系(新节点ID 应该为8):
INSERT INTO treepaths (ancestor, descendant)SELECT t.ancestor, 8FROM treepaths AS tWHERE t.descendant = 6UNION ALL SELECT 8, 8;
要删除一个叶子节点,比如评论#7, 应删除所有treepaths 表中后代为评论 #7 的行:
DELETE FROM treepaths WHERE descendant = 7;
要删除一颗完整的子树,比如评论#4 和它所有的后代,可删除所有在 treepaths 表中后代为 #4的行,以及那些以评论#4后代为后代的行。
闭包表的设计比嵌套集更加的直接,两者都能快捷地查询给定节点的祖先和后代,但是闭包表能更加简单地维护分层信息。这两个设计都比使用邻接表或者路径枚举更方便地查询给定节点的直接后代和祖先。
然而你可以优化闭包表来使它更方便地查询直接父亲节点或者子节点: 在 treepaths 表中添加一个 path_length 字段。一个节点的自我引用的path_length 为0,到它直接子节点的path_length 为1,再下一层为2,以此类推。这样查询起来就方便多了。
总结:你该使用哪种设计:
种设计都各有优劣,如何选择设计,依赖于应用程序的哪种操作是你最需要性能上的优化。
| 方案 | 表数量 | 查询子 | 查询树 | 插入 | 删除 | 引用完整性 |
| 邻接表 | 1 | 简单 | 困难 | 简单 | 简单 | 是 |
| 枚举路径 | 1 | 简单 | 简单 | 简单 | 简单 | 否 |
| 嵌套集 | 1 | 困难 | 简单 | 困难 | 困难 | 否 |
| 闭包表 | 2 | 简单 | 简单 | 简单 | 简单 | 是 |
层级数据设计比较
1、邻接表是最方便的设计,并且很多程序员都了解它
2、如果你使用的数据库支持WITH 或者 CONNECT BY PRIOR 的递归查询,那能使得邻接表的查询更高效。
3、枚举路径能够很直观地展示出祖先到后代之间的路径,但同时由于它不能确保引用完整性,使得这个设计非常脆弱。枚举路径也使得数据的存储变得比较冗余。
4、嵌套集是一个聪明的解决方案,但可能过于聪明,它不能确保引用完整性。最好在一个查询性能要求很高而对其他要求一般的场合来使用它。
5、闭包表是最通用的设计,并且以上的方案也只有它能允许一个节点属于多棵树。它要求一张额外的表来存储关系,使用空间换时间的方案减少操作过程中由冗余的计算所造成的消耗。
这几种设计方案只是我们日常设计中的一部分,开发中肯定会遇到更多的选择方案。选择哪一种方案,是需要切合实际,根据自己项目的需求,结合方案的优劣,选择最适合的一种。
我遇到一些开发人员,为了敷衍了事,在设计数据库表时,只考虑能否完成眼下的任务,不太注重以后拓展的问题,不考虑查询起来是否耗性能。可能前期数据量不多的时候,看不出什么影响,但数据量稍微多一点的话,就已经显而易见了(例如:可以使用外联接查询的,偏偏要使用子查询)。
我觉得设计数据库是一个很有趣且充满挑战的工作,它有时能体现你的视野有多宽广,有时它能让你睡不着觉,总之痛并快乐着。
위 내용은 데이터베이스 테이블 디자인-인접 목록, 경로 열거, 중첩 세트, 클로저 테이블의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.