
지저분한 텍스트 데이터의 Python 처리 예

- PHP中文网원래의
- 2017-06-20 16:34:565624검색
1. 운영 환경
1. 블로그 코드는 이 버전입니다.
2. 시스템 환경: win7 64비트 시스템
2. 일부 데이터 스크린샷은 다음과 같습니다. 첫 번째 필드는 원본 필드이고 다음 3개는 정리된 필드입니다. 데이터베이스의 집계 필드를 관찰하면 얼핏 보면 사용하려는 통화 금액 10,000위안과 비슷하게 데이터가 비교적 규칙적입니다. 조건부 판단을 작성하고 일률적으로 변환하는 SQL은 SQL 스크립트를 이용하여 문자열을 가로채서 '10,000 RMB' 단위로 완성할 수 있지만, 데이터가 불규칙하고 조건이 너무 많아 청소 품질이 확실하지 않은 것으로 나중에 밝혀졌습니다. 일부는 앞에 왼쪽 대괄호가 없고 일부 필드에는 통화가 포함되어 있지 않으며 일부 숫자는 정수가 아니며 일부는 10,000 단어가 없으므로 숫자와 '10,000 위안'이라는 두 필드에 저장됩니다. 단위를 사용하면 SQL 스크립트를 작성하는 것이 복잡해집니다.mysql에서 텍스트에서 숫자를 추출할 수 있는 함수를 찾지 못했습니다.정규식 mysql에 텍스트 필터링과 유사한 기능이 있다는 것을 아는 사람이라면 공식이 자주 사용됩니다. 그리고 텍스트에서 숫자를 추출하는 방법은 그렇게 많은 노력을 쏟을 필요가 없습니다. 도구를 배우고 사용하는 것이 가장 좋습니다.
Python 사용 경험과 결합하여 Python에는 문자열 필터링을 위한 많은 기능이 있습니다. 이 방법은 이후 코드에서 텍스트를 필터링하는 데 사용됩니다.
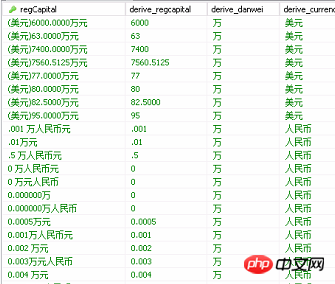 첫번째 부분클리닝 데이터 스크린샷
첫번째 부분클리닝 데이터 스크린샷3. 데이터 처리의 매크로 논리에 대해 생각하기
데이터를 얻은 후 서두르지 말고 먼저 정리의 논리에 대해 생각해 보세요. 절반의 노력으로 두 배의 결과를 얻을 수 있습니다. 남은 시간은 코드 로직을 구현하고 코드 프로세스를 디버깅하는 것입니다.
3.1 코드 작성 없이 생각하는 과정:
내가 이루고 싶은 최종 데이터 정리는 펀드 필드를 [금액 + 단위 + 각 통화] 또는 [금액 + 단위 + 통합 RMB 통화]의 조합으로 변환하는 것입니다( 환율
3.1.1 숫자, 단위, 통화 3개 필드로 분할
(단위는 수만으로 나누어 만을 제외하고, 통화는 인민폐와 특정 외화)
3.1.2 단위를 만 단위로 통일
첫 번째 단계에서 단위의 숫자 부분은 만/10000이 아니지만 만이라는 숫자 부분은 그대로 유지됩니다
3.1. 3 통화 통일 RMB의 경우
통화는 RMB이고 처음 두 필드는 변경되지 않고 숫자가 아닌 부분은 숫자가 됩니다*각 외화의 RMB에 대한 환율, 단위는 변경되지 않고 여전히 통일된 '10'입니다. 2단계에서 천'
3.2 각 단계의 청소 효과 데이터 열거가 예상됩니다:
이 결과를 시작으로 단계별로 분해하여 먼저 청소 논리 부분을 정리합니다.
3.2.1 예상 효과 첫 번째 청소는 세 개의 필드로 나뉩니다. 숫자 단위 통화:
① 필드 값 = "2000 RMB", 첫 번째 청소 10,000 RMB를 제외한 2000 RMB2000 不含万 人民币
②字段值=“2000万元人民币”,第一次清洗2000 万 人民币
③字段值=“2000万元外币”, 第一次清洗2000 万 外币
3.2.2第二次清洗期望效果 将单位 统一归为万:
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000 万 外币
注意:如果上面达到需求 则清洗完毕,如果想将单位换成人民币就进行下面三次清洗
3.2.3第三次清洗期望效果:单位 币种都统一为万+人民币
如果最后需求是换算成币种统一人民币,那么我们就在二次清洗后的基础上再写条件就好,
#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000*外币兑换人民币汇率 万 人民币
四、对具体代码的宏观逻辑思考
币种和单位这两个就2种情况,很好写
4.1、币种部分
这个条件简单,如果币种的值在字符中出现就让新字段等于这个币种的值即可。
4.2、单位(万为单位)
这个条件也简单,万字出现在字符中 单位这个变量=‘万’ 没出现就让单位变量等于‘不含万’,这样写是为了方便下一步对数字进行二次处理的时候写条件判断了。
4.3、数字部分 确保清洗后和原值逻辑上一样 做些判断
确保清洗后和原值逻辑上一样意思是假如有这样字段300.0100万清洗后变成300.01 万 人民币 也是正确的。
filter(str.isdigit,字段的值)这个代码我首先知道可以将文本中数字取出,同过对字段group by 聚合以后知道有小数点的字段,取出的值不再带有小数点,如‘20.01万’,filter(str.isdigit,‘20.01万’)②필드 값 = "2000만 RMB" , 첫 번째 청소
2000만 위안3필드 값 = "2000만 외화", 첫 번째 청소
2000만 외화3.2.2 기대 효과 두 번째 청소는 1만 단위로 통일됩니다. #带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
① 필드 값 = "2000위안"200만 위안
2000만 위안 code>
③필드 값 = "2천만 위안" 외화"2000만 외화

3.2.3 세 번째 청소의 예상 효과: 단위 모든 통화는 만 + RMB로 통합됩니다.마지막 요구 사항이 통화를 통합 RMB로 변환하는 것이라면, 다음과 같이 하면 됩니다. 2차 청소를 기준으로 조건을 작성합니다.
#coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db')①필드 값 = "2000 RMB"
200만 RMB②필드 값 = "2000만 위안"
2000만 위안 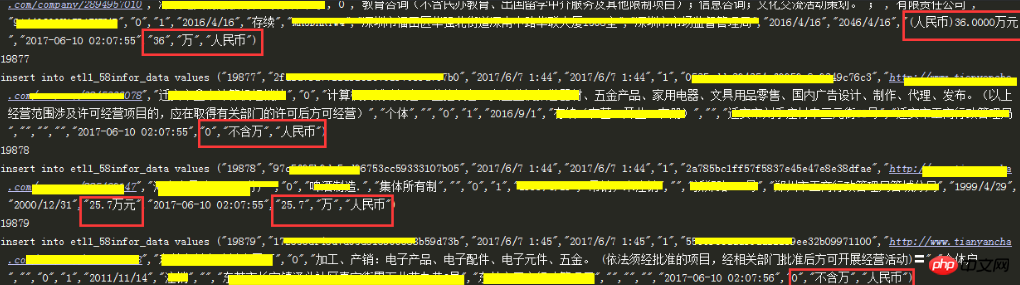
2000* 1만 위안에 대한 외화 환율filter(str.isdigit, field value)이 코드에서는 먼저 텍스트의 숫자를 추출할 수 있다는 것을 알고 있습니다. 필드를 그룹화하면 소수점이 있는 필드는 추출되지 않습니다. '200,100'과 같은 소수점을 사용하면 filter(str.isdigit,'200,100')에서 가져온 숫자는 2001입니다. 분명히 이 숫자는 올바르지 않으므로 필요합니다. 소수점이 있는지 고려하려면 소수점이 있는 항목이 원래 필드와 동일해야 합니다. 🎜🎜 4. 데이터베이스 데이터를 읽지 않고 처음으로 기본 코드를 정리합니다. 🎜🎜 데이터베이스에서 약 10개의 이상값을 추출합니다. 테스트에서 info는 regCapital 필드의 값입니다. 🎜import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestoday🎜 5. 모든 코드: 데이터베이스 데이터를 읽고 완전히 정리합니다. 🎜🎜네 번째 단계는 현재 코드가 올바른지 확인하기 위해 일부 데이터를 테스트하는 것입니다. , 로직은 매크로 관점에서 확장되어야 하며 정보 변수는 데이터베이스로 동적으로 변경되어야 합니다. 모든 값은 완전히 정리됩니다. 🎜rrreee🎜 6. 코드 작업 🎜🎜6.1 데이터베이스 및 필드의 원본 테이블 데이터를 읽습니다. 생성된 새 테이블 🎜🎜🎜🎜🎜 데이터베이스의 원본 테이블 데이터와 새 테이블에서 생성된 필드 읽기 🎜🎜🎜 6.2 새 테이블 삽입 및 첫 번째 데이터 정리 수행🎜🎜빨간색 상자 부분이 정리 부분입니다. , 다른 데이터는 둔감화되었습니다🎜🎜🎜🎜🎜새 테이블을 삽입하고 첫 번째 데이터 정리를 수행하세요🎜🎜6.3 数据表数据清洗结果
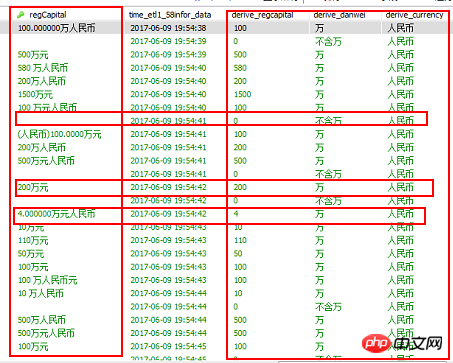
七、增量数据处理
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestoday위 내용은 지저분한 텍스트 데이터의 Python 처리 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!