
DouTu.com에서 최신 이모티콘을 가져오는 방법은 무엇입니까?

- PHP中文网원래의
- 2017-06-20 14:29:442181검색
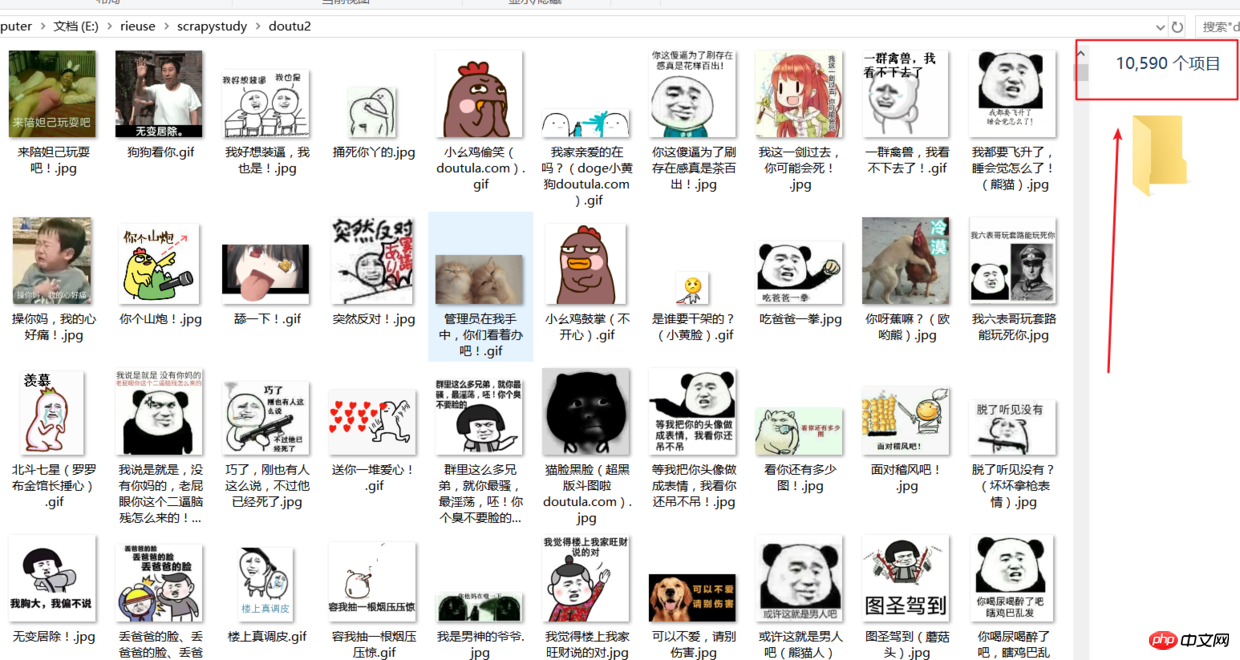
1: 목표
처음으로 Scrapy 프레임워크를 사용할 때 많은 함정에 직면했습니다. 계속해서 코드를 검색하고 수정하면 문제를 해결할 수 있습니다. 이번에는 DouTu 웹사이트의 최신 이모티콘 사진 www.doutula.com/photo/list을 크롤링했습니다. Scrapy 프레임워크를 사용하여 연습하고 금지되는 것을 방지하기 위해 임의의 사용자 에이전트를 사용했습니다. DouTu 이모티콘 패키지는 매일 업데이트되며 사용할 수 있습니다. 총 50,000개의 표현이 하드 드라이브에 저장되어 있습니다. 시간을 절약하기 위해 10,000장 이상의 사진을 찍었습니다.
2: Scrapy 소개
Scrapy는 웹사이트 데이터를 크롤링하고 구조적 데이터를 추출하기 위해 작성된 애플리케이션 프레임워크입니다. 데이터 마이닝, 정보 처리 또는 기록 데이터 저장을 포함한 일련의 프로그램에서 사용할 수 있습니다.
프로세스 사용
스크래피 프로젝트 만들기
추출된 항목 정의
웹사이트를 크롤링하고 항목을 추출하는 스파이더 작성
추출된 항목을 저장하는 항목 파이프라인 작성( 즉, 데이터)
다음 다이어그램은 시스템에서 발생하는 구성 요소 및 데이터 흐름에 대한 개요를 포함하여 Scrapy의 아키텍처를 보여줍니다(녹색 화살표로 표시). 다음은 각 구성 요소에 대한 간략한 소개와 자세한 콘텐츠 링크입니다. 데이터 흐름은 아래에 설명되어 있습니다
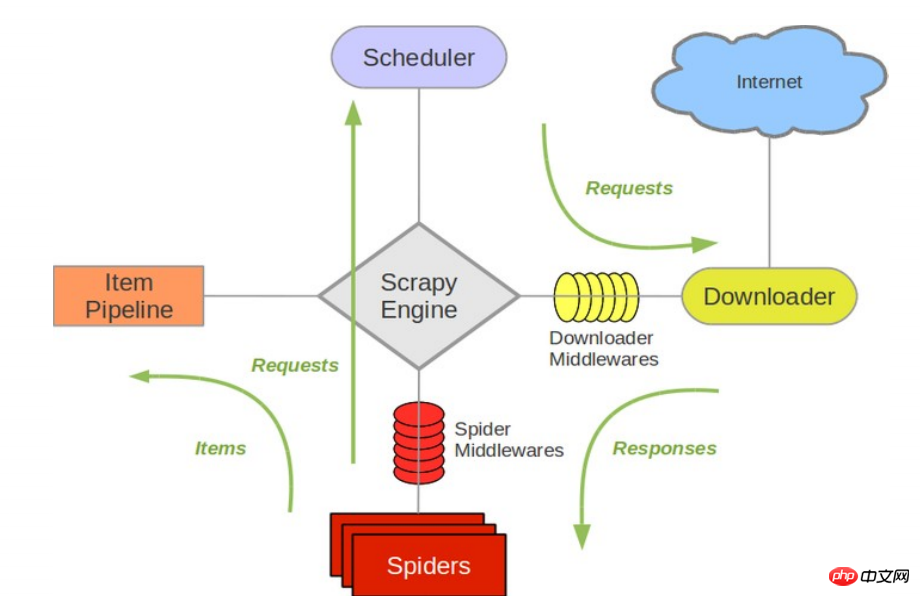
Components
Scrapy Engine
엔진은 시스템의 모든 구성 요소를 통한 데이터 흐름을 제어하고 해당 작업이 발생할 때 이벤트를 트리거하는 역할을 담당합니다. 자세한 내용은 아래 데이터 흐름 섹션을 참조하세요.Scheduler(Scheduler)
스케줄러는 엔진의 요청을 받아 나중에 엔진이 요청할 때 엔진에 제공할 수 있도록 대기열에 추가합니다.Downloader
다운로더는 페이지 데이터를 가져와 엔진에 제공한 다음 스파이더에 제공하는 역할을 합니다.Spiders
Spider는 Scrapy 사용자가 응답을 분석하여 항목(즉, 획득한 항목) 또는 추가 후속 URL을 추출하기 위해 작성한 클래스입니다. 각 스파이더는 특정(또는 몇 개의) 웹사이트 처리를 담당합니다. 자세한 내용은 거미를 참조하세요.Item Pipeline
Item Pipeline은 스파이더가 추출한 아이템을 처리하는 역할을 담당합니다. 일반적인 프로세스에는 정리, 유효성 검사 및 지속성(예: 데이터베이스 액세스)이 포함됩니다. 자세한 내용은 항목 파이프라인을 참조하세요.다운로더 미들웨어
다운로더 미들웨어는 엔진과 다운로더 사이의 특정 후크로, 다운로더가 엔진에 전달한 응답을 처리합니다. 사용자 정의 코드를 삽입하여 Scrapy 기능을 확장하는 간단한 메커니즘을 제공합니다. 자세한 내용은 다운로더 미들웨어를 참조하세요.스파이더 미들웨어
스파이더 미들웨어는 엔진과 스파이더 사이의 특정 후크로, 스파이더의 입력(응답)과 출력(항목 및 요청)을 처리합니다. 사용자 정의 코드를 삽입하여 Scrapy 기능을 확장하는 간단한 메커니즘을 제공합니다. 자세한 내용은 스파이더 미들웨어(미들웨어)를 참조하세요.
Three: 예시 분석
1. 홈페이지 홈페이지에서 최신 Dou Tu 이모티콘을 입력한 후 URL은 이고, 두 번째 페이지를 클릭하면 URL이 로 바뀌는 것을 보면 알 수 있습니다. URL의 구성은 다른 페이지 번호입니다. 그런 다음 스파이더의 start_urls 시작 항목은 다음과 같이 정의되어 1~20페이지의 이미지 표현식을 크롤링합니다. 더 많은 이모티콘 페이지를 다운로드하려면 더 추가할 수 있습니다.
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 20)]2. 개발자 모드로 진입하여 웹페이지 구조를 분석해 보면 아래와 같은 구조를 볼 수 있습니다. xpath 주소를 마우스 오른쪽 버튼으로 클릭하고 복사하여 모든 표현식이 있는 태그 콘텐츠를 가져옵니다. a[1]은 첫 번째 a를 나타내고, [1]을 제거하면 모두 a가 됩니다.
//*[@id="pic-detail"]/div/div[1]/div[2]/a
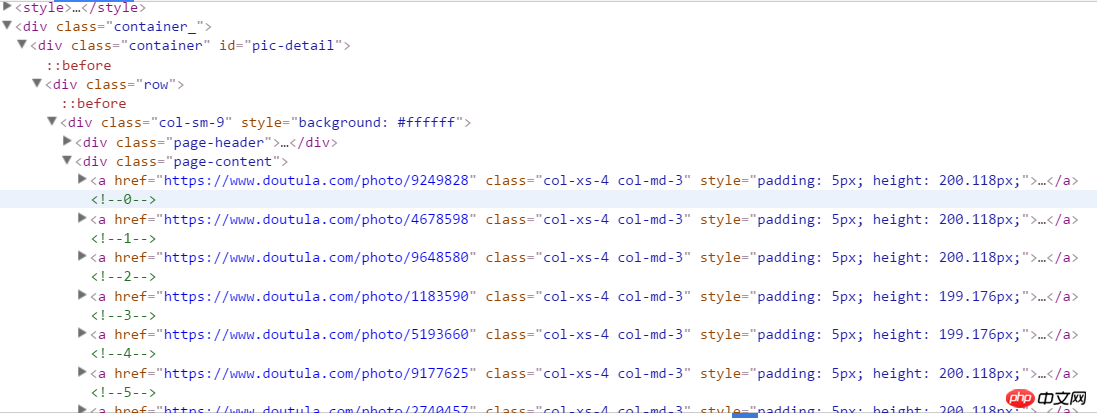
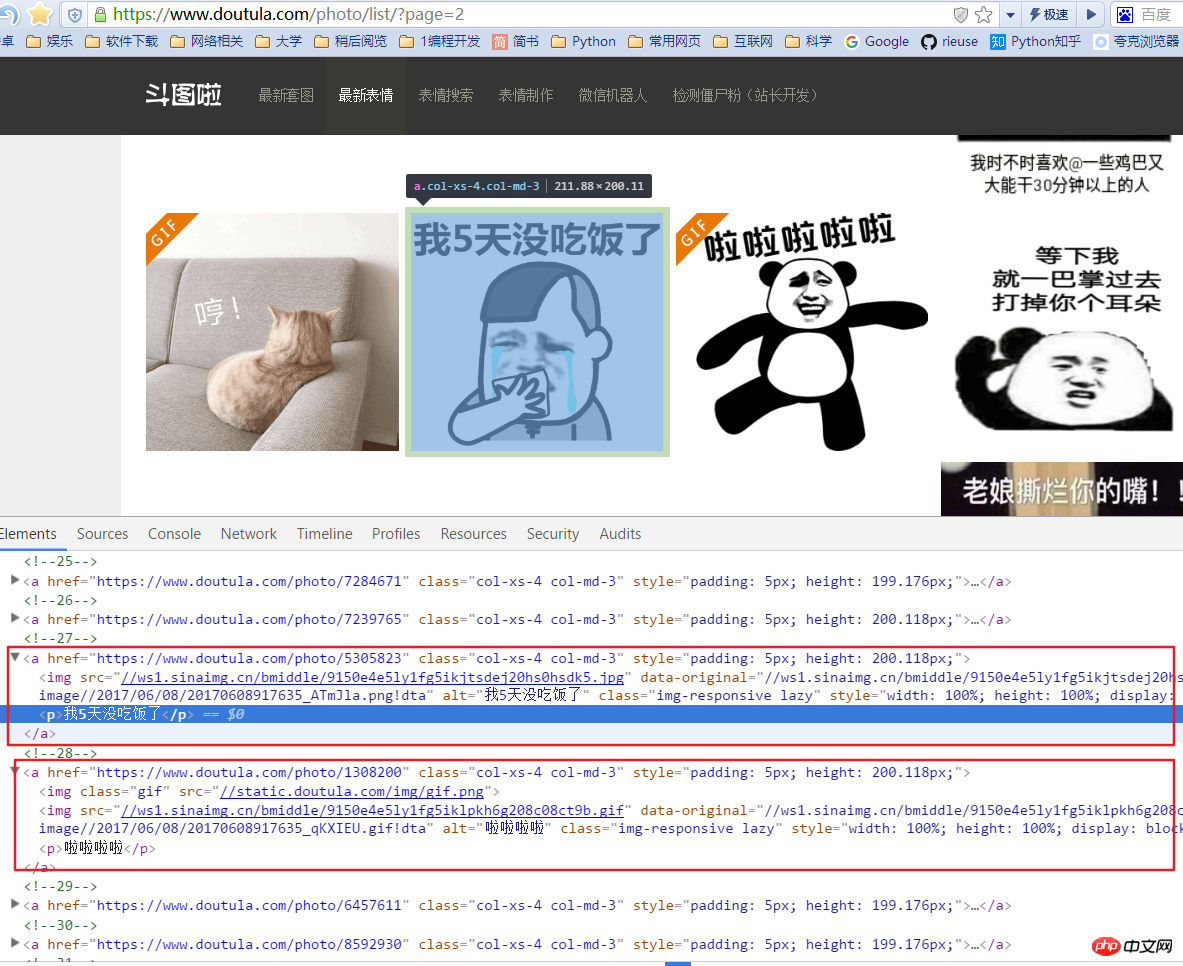
여기에는 jpg와 gif의 두 가지 표현이 있다는 점에 주목할 가치가 있습니다. 이미지 주소를 가져올 때 a 태그 아래 첫 번째 img의 src만 가져오면 오류가 발생하므로 img에서 data-original 값을 가져와야 합니다. 여기서는 이미지 소개인 a 태그 아래에 p 태그가 있는데, 이를 이미지 파일 이름으로도 잡아보겠습니다.
图片的连接是 'http:' + content.xpath('//img/@data-original') 图片的名称是 content.xpath('//p/text()')
四:实战代码
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。
scrapy startproject ScrapyDoutu cd ScrapyDoutu\ScrapyDoutu\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。
import scrapyclass DoutuItem(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。
# -*- coding: utf-8 -*-
import os
import scrapy
import requestsfrom ScrapyDoutu.items import DoutuItems
class Doutu(scrapy.Spider):
name = "doutu"
allowed_domains = ["doutula.com", "sinaimg.cn"]
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 40)] # 我们暂且爬取40页图片
def parse(self, response):
i = 0for content in response.xpath('//*[@id="pic-detail"]/div/div[1]/div[2]/a'):
i += 1item = DoutuItems()item['img_url'] = 'http:' + content.xpath('//img/@data-original').extract()[i]item['name'] = content.xpath('//p/text()').extract()[i]try:if not os.path.exists('doutu'):
os.makedirs('doutu')
r = requests.get(item['img_url'])
filename = 'doutu\\{}'.format(item['name']) + item['img_url'][-4:]with open(filename, 'wb') as fo:
fo.write(r.content)
except:
print('Error')
yield item3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中
content.xpath('//img/@data-original').extract()[i]中extract()用来返回一个list(就是系统自带的那个) 里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。filename = 'doutu\{}'.format(item['name']) + item['img_url'][-4:]是用来获取图片的名称,最后item['img_url'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。最后一点就是如果xpath没有正确匹配,则会出现64d8292994d119f5f1f87748047c90da (referer: None)
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.
# -*- coding: utf-8 -*-BOT_NAME = 'ScrapyDoutu'SPIDER_MODULES = ['ScrapyDoutu.spiders']NEWSPIDER_MODULE = 'ScrapyDoutu.spiders'DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ScrapyDoutu.middlewares.RotateUserAgentMiddleware': 400,
}ROBOTSTXT_OBEY = False # 不遵循网站的robots.txt策略CONCURRENT_REQUESTS = 16 #Scrapy downloader 并发请求(concurrent requests)的最大值DOWNLOAD_DELAY = 0.2 # 下载同一个网站页面前等待的时间,可以用来限制爬取速度减轻服务器压力。COOKIES_ENABLED = False # 关闭cookies5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。
import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
print(ua)
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]6.到现在为止,代码都已经完成了。那么开始执行吧!scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
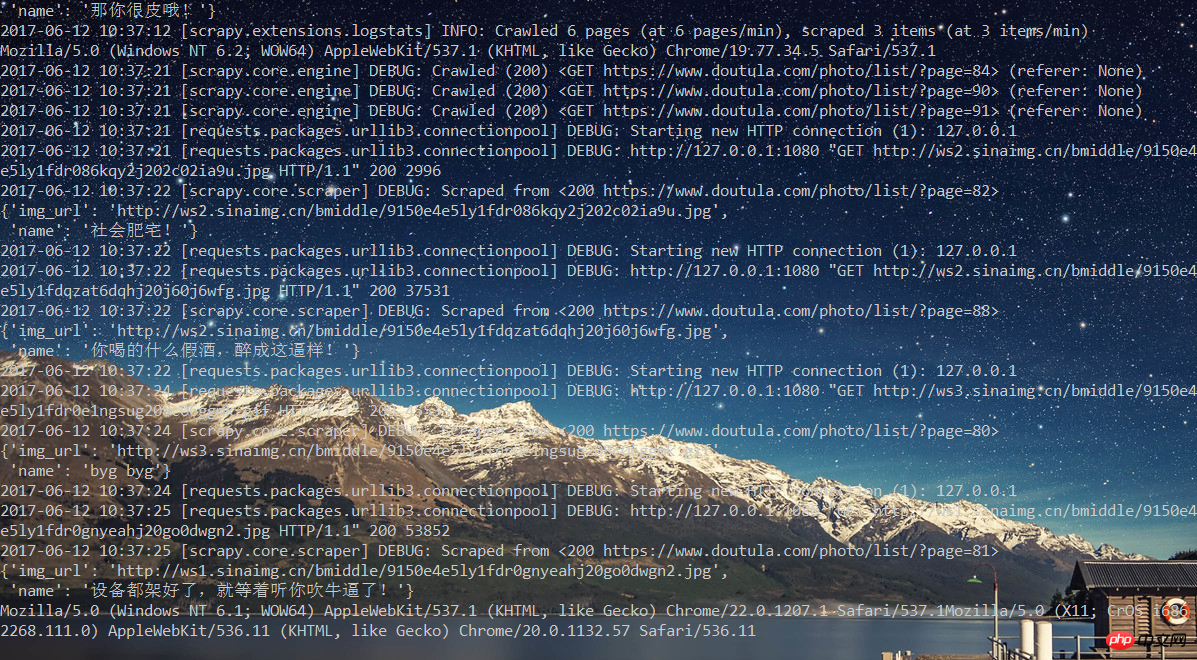
五:总结
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
위 내용은 DouTu.com에서 최신 이모티콘을 가져오는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!