
Python에서 일반적으로 사용되는 정렬 예제 공유

- PHP中文网원래의
- 2017-06-21 16:40:361433검색
정렬 알고리즘의 안정성과 중요성
버블 정렬
복잡성과 안정성
선택 정렬
삽입 정렬
-
힐 정렬
-
빠른 정렬
일반적인 정렬 알고리즘의 효율성 비교
정렬 알고리즘의 안정성과 중요성
정렬할 순서에는 동일한 키워드를 가진 레코드가 있지만 정렬 후에도 이들 레코드의 상대적 순서는 변경되지 않습니다. , 정렬 알고리즘이 안정적입니다.
정렬이 불안정하면 여러 키워드의 정렬을 완료할 수 없습니다. 예를 들어 정수 정렬은 자릿수가 높을수록 우선 순위가 높아지며 높은 자릿수에서 낮은 자릿수로 정렬됩니다. 그러면 각 비트를 정렬하려면 안정적인 알고리즘이 필요합니다. 그렇지 않으면 올바른 결과를 얻을 수 없습니다.
즉, 여러 키워드를 여러 번 정렬하려면 안정적인 알고리즘을 사용해야 합니다.
버블 정렬
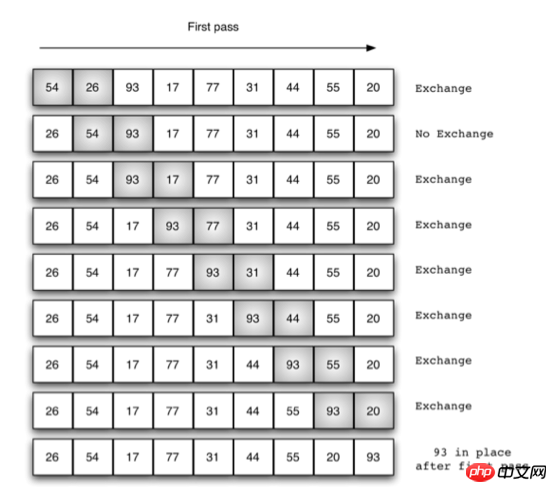 행
행
def bubble_sort(alist):
"""
冒泡排序
"""
if len(alist) <= 1:
return alist
for j in range(len(alist)-1,0,-1):
for i in range(j):
if alist[i] > alist[i+1]:
alist[i], alist[i+1] = alist[i+1], alist[i]
return alist
복잡성과 안정성
최적의 시간 복잡도: ( O(n) ) 순회에서 교환 가능한 요소를 찾지 못하고 정렬이 종료됩니다
최악의 시간 복잡도: (O(n^2))
안정성: 안정적
선택 정렬
선택 정렬은 다음과 같습니다. 간단하고 직관적인 정렬 알고리즘. 작동 방식은 다음과 같습니다. 먼저 정렬되지 않은 시퀀스에서 가장 작은(큰) 요소를 찾아 정렬된 시퀀스의 시작 부분에 저장한 다음, 정렬되지 않은 나머지 요소에서 계속해서 가장 작은(큰) 요소를 찾아 마지막에 넣습니다. 정렬된 순서. 모든 요소가 정렬될 때까지 계속됩니다.
삽입 정렬
삽입 정렬은 정렬되지 않은 데이터의 경우 정렬된 순서를 뒤에서 앞으로 스캔하여 해당 위치를 찾아 삽입합니다. 삽입 정렬의 구현에서는 뒤에서 앞으로 스캔하는 과정에서 정렬된 요소를 반복적으로 점진적으로 뒤로 이동하여 최신 요소에 대한 삽입 공간을 제공해야 합니다.
 행
행
def insert_sort(alist):
"""
插入排序
"""
n = len(alist)
if n <= 1:
return alist
# 从第二个位置,即下表为1的元素开始向前插入
for i in range(1, n):
j = i
# 向前向前比较,如果小于前一个元素,交换两个元素
while alist[j] < alist[j-1] and j > 0:
alist[j], alist[j-1] = alist[j-1], alist[j]
j-=1
return alist
복잡도 및 안정성
최적의 시간 복잡도: O((n)) (오름차순으로 정렬, 시퀀스는 이미 오름차순)
최악의 시간 복잡도: O( (n ^2))
안정성: 안정적
Hill Sort
Hill Sort(Shell Sort)는 삽입 정렬을 개선한 것으로 정렬이 안정적이지 않습니다. 힐 정렬은 첨자의 특정 증분으로 레코드를 그룹화하고 직접 삽입 정렬 알고리즘을 사용하여 각 그룹을 정렬하는 것입니다. 증분이 1로 줄어들면 각 그룹에는 더 많은 키워드가 포함됩니다. 이번에는 전체 파일을 하나의 그룹으로 나누고 알고리즘을 종료합니다.
def shell_sort(alist): n = len(alist) gap = n//2 # gap 变化到0之前,插入算法之行的次数 while gap > 0: # 希尔排序, 与普通的插入算法的区别就是gap步长 for i in range(gap,n): j = i while alist[j] < alist[j-gap] and j > 0: alist[j], alist[j-gap] = alist[j-gap], alist[j] j-=gap gap = gap//2 return alist
복잡도 및 안정성
최적의 시간 복잡도: (O(n^{1.3})) (주문할 필요 없음)
최악의 시간 복잡도: (O(n^) 2))
안정성: 불안정
퀵 정렬
퀵 정렬(Quicksort)은 정렬할 데이터를 하나의 정렬을 통해 독립적인 두 부분으로 나누고 한 부분의 모든 데이터가 다른 부분보다 우수해야 합니다. 그런 다음 이 방법을 사용하면 데이터의 두 부분을 각각 빠르게 정렬할 수 있으므로 전체 정렬 프로세스를 반복적으로 수행할 수 있으므로 전체 데이터가 정렬된 시퀀스가 됩니다.
단계는 다음과 같습니다.
시퀀스에서 "피벗"이라는 요소를 선택합니다.
시퀀스를 재정렬합니다. 피벗 값보다 작은 모든 요소는 피벗 값 앞에 배치되고, 피벗 값보다 작은 모든 요소는 피벗 값은 피벗 앞에 배치됩니다. 더 큰 값을 갖는 값이 베이스 뒤에 배치됩니다(동일한 숫자는 양쪽에 있을 수 있음). 이 분할 후 데이텀은 시퀀스의 중간에 있습니다. 이를 파티션 작업이라고 합니다.
기본 값보다 작은 요소의 하위 배열과 기본 값보다 큰 요소의 하위 배열을 재귀적으로 정렬합니다.
재귀의 가장 낮은 경우는 배열의 크기가 0 또는 1인 경우, 즉 항상 정렬된 경우입니다. 계속 반복되지만 이 알고리즘은 항상 종료됩니다. 왜냐하면 각 반복(반복)에서 최소한 하나의 요소를 최종 위치로 이동하기 때문입니다.
일반적인 정렬 알고리즘의 효율성 비교
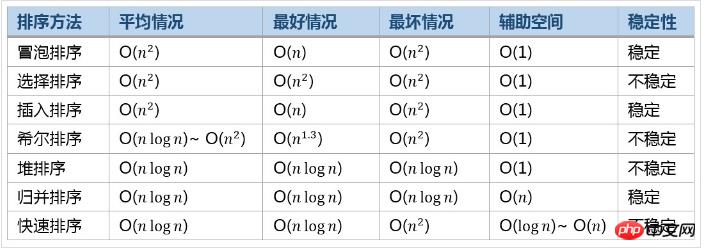 되기도
되기도
위 내용은 Python에서 일반적으로 사용되는 정렬 예제 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!