
Scrapy 크롤러 프레임워크 소개

- PHP中文网원래의
- 2017-06-20 17:19:392438검색
스크래피 크롤러 프레임워크 소개
설치 방법: pip install scrapy를 설치할 수 있습니다. 나는 anaconda 명령을 사용하여 scrapy를 conda 설치합니다. 1 엔진은 Spider Request로부터 크롤링 요청을 받습니다
4 엔진은 미들웨어를 통해 다운로더에게 크롤링 요청을 보냅니다5 웹페이지를 크롤링한 후 다운로더는 응답(Response)을 형성하여 미들웨어를 통해 엔진으로 보냅니다
6 엔진은 받은 응답을 다음으로 보냅니다 미들웨어를 통한 Spider 처리 엔진 크롤링 요청은 Scheduler로 전달되어 스케줄링 7 Spider는 응답을 처리하고 스크랩된 항목(Scraped Item)
7 Spider는 응답을 처리하고 스크랩된 항목(Scraped Item)
8 엔진에서 스크랩된 항목을 Item Pipeline (framework Exit)
9 엔진은 Scheduler로 크롤링 요청을 보냅니다Engine은 각 모듈의 데이터 흐름을 제어하고 요청이 빌 때까지 Scheduler로부터 지속적으로 크롤링 요청을 얻습니다프레임 항목: Spider의 초기 크롤링 요청<br>프레임 종료: 항목 Pipelinem
<br><br> <br>
<br> <br><br>
<br><br> <br>
(1) 모든 모듈 간의 데이터 흐름 제어
(2) 조건에 따라 이벤트 트리거사용자가 수정할 필요 없음
다운로더 요청에 따라 웹 페이지 다운로드
사용자 수정이 필요하지 않습니다
Scheduler모든 크롤링 요청의 예약 및 관리<br>사용자 수정이 필요하지 않습니다<br><br>Downloader Middleware
목적: 엔진, 스케줄러 및 다운로더 간의 사용자 구성 기능 구현 제어 기능: 요청 또는 응답 수정, 삭제, 추가 <br>사용자는 구성 코드 작성 가능 <br>
Spider(1) 다운로더가 반환한 응답 분석<br>(2) 스크랩된 항목 생성<br> (3) 추가 크롤링 요청 생성(요청 )
사용자에게 구성 코드 작성을 요구합니다항목 파이프라인<br><br>(1) Spider에서 생성된 크롤링된 항목을 파이프라인 방식으로 처리합니다.<br>(2) 파이프라인과 유사한 일련의 작업 시퀀스로 구성되며, 각 작업 <br>은 항목 파이프라인 유형
(3) 가능한 작업은 다음과 같습니다.크롤링된 항목의 HTML 데이터 정리, 검사 및 중복 검사, 데이터베이스에 데이터 저장 사용자가 구성 코드를 작성해야 함 <br> 알았습니다 기본 개념을 설명한 후 작성을 시작하겠습니다. 최초의 스크래피 크롤러. <br><br>먼저 새 크롤러 프로젝트를 만듭니다. scrapy startproject xxx(프로젝트 이름) <br>
이 크롤러는 단순히 새로운 웹사이트의 제목과 작성자를 크롤링합니다. <br><br>이제 크롤러 프로젝트 북을 만들었고 이제 구성을 편집해 보겠습니다<br><br><br><br> 이제 첫 번째 수준 북 디렉터리 아래에 책을 만듭니다. start.py는 IDE에서 스크랩 크롤러를 실행하는 데 사용됩니다. 파일에 다음 코드를 작성합니다. + ~ 처음 두 매개변수는 고정되어 있고 세 번째 매개변수는 스파이더의 이름입니다
来 下 다음으로 Items: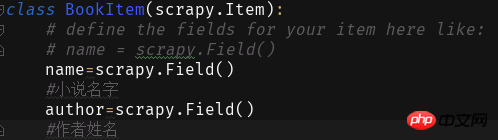
+Novel Pinyin임을 알게 됩니다. .html
이를 통해 웹페이지의 내용을 작성하고 읽습니다
이를 얻은 후 구문 분석 기능을 사용하여 얻은 웹페이지를 구문 분석하고 필요한 정보를 추출합니다.
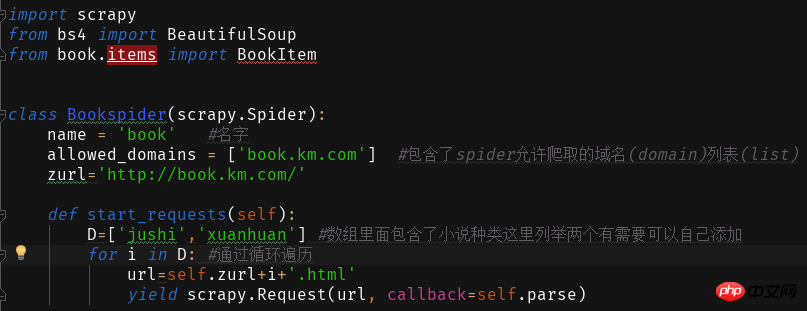
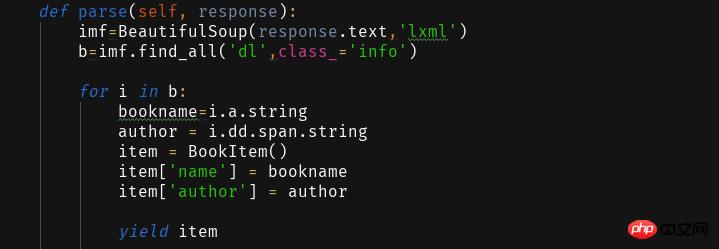 저장 방법은 두 가지가 있습니다
저장 방법은 두 가지가 있습니다
1 txt 텍스트로 저장
2 Database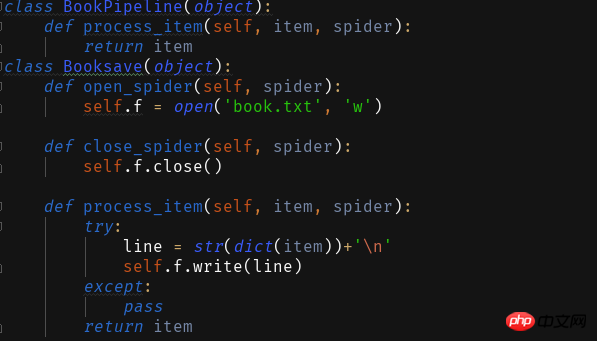
<span style="color: #000000">ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}<br>xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了<br>第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。<br>附一个book的完整代码:<br></span>
import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider):
name = 'book' #名字
allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list)
zurl=''def start_requests(self):
D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历
url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
imf=BeautifulSoup(response.text,'lxml')
b=imf.find_all('dl',class_='info')for i in b:
bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem()
item['name'] = bookname
item['author'] = authoryield item
<br>
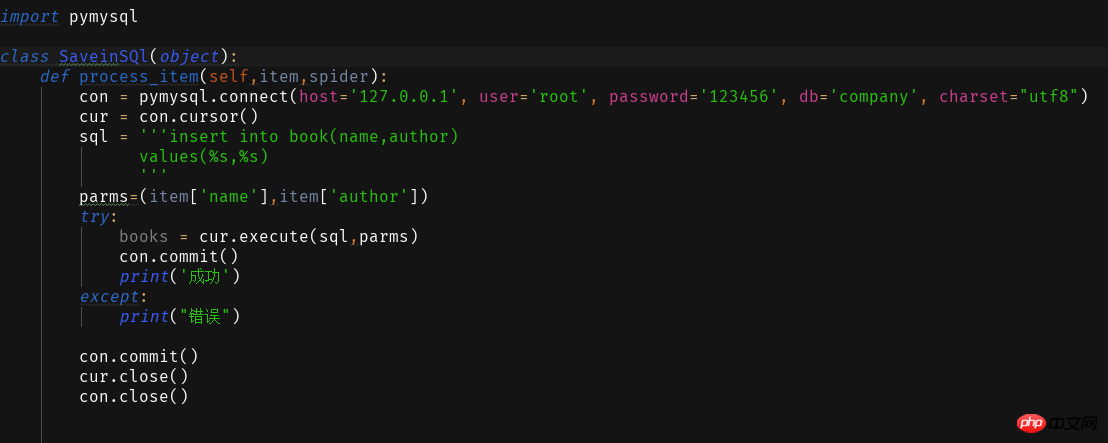
도 구성해야 합니다.
위 내용은 Scrapy 크롤러 프레임워크 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!