
JAVA WEB 참고 사항--한자가 깨져 있는 문자
- 巴扎黑원래의
- 2017-06-26 11:11:011575검색
JAVA WEB 잘못된 코드 문제 분석
잘못된 코드의 원인
Java 웹 개발 과정에서 잘못된 코드 문제를 자주 접하게 되는 이유는 문자 인코딩과 디코딩 방법의 불일치로 요약할 수 있습니다. .
문자가 깨지는 이유는 문자 인코딩과 디코딩 방법이 일치하지 않기 때문인데 왜 문자를 인코딩해야 할까요? 인코딩하지 않아도 괜찮을까요? 컴퓨터가 데이터를 저장하는 기본 단위가 1바이트, 즉 8비트이기 때문에 표현할 수 있는 최대 문자 수는 28=256자이고, 우리 현실 사회에 존재하는 문자(한자)는 문자, 영어, 기타 문자 등)은 이 숫자를 훨씬 초과하므로 문자와 바이트 간의 충돌을 해결하려면 문자를 컴퓨터에 저장하기 전에 인코딩해야 합니다.
인코딩 및 디코딩
컴퓨터의 일반적인 인코딩 방법에는 ASCII, ISO-8859-1, GB2312, UTF-16 및 UTF-8이 있습니다.
ASCII 코드는 바이트의 하위 7비트로 표현되므로 표현할 수 있는 최대 문자 수는 27=128입니다. ISO-8859-1은 ASCII 코드를 기반으로 한 ISO 조직의 확장이며 ASCII 코드와 호환되며 대부분의 서유럽 문자를 포함합니다. ISO8859-1은 1바이트를 사용하여 표현하므로 최대 256자를 표현할 수 있습니다. GB2312는 더블바이트 인코딩을 사용합니다. 인코딩 범위는 A1-F7입니다. 여기서 A1-A9는 기호 영역이고 B0-F7은 6763개의 한자를 포함하는 한자 영역입니다. GBK는 GB2312 인코딩을 확장하고, 표현할 수 있는 한자가 21,003자에 달합니다. UTF-16은 어떤 문자를 표현하든 2바이트로 표현되는 고정 길이 인코딩 방식을 사용합니다. 이는 JAVA 메모리의 문자 저장 형식이기도 합니다. UTF-16과 달리 UTF-8은 가변 길이 인코딩 방식을 사용하며 다양한 유형의 문자를 1~6바이트로 구성할 수 있습니다.
아래와 같이 문자열 "Hyuuga Hinata"를 사용하여 컴퓨터에서 다양한 인코딩 방식의 인코딩을 살펴보겠습니다.

가블드 코드 분석 및 솔루션
JAVA WEB의 잘못된 코드 문제는 요청으로 인한 잘못된 코드와 응답으로 인한 잘못된 코드로 구분합니다. 코드가 왜곡된 이유, 즉 문자를 분석해야 합니다. 인코딩 방법은 무엇이며 디코딩 방법은 무엇입니까?
요청으로 인해 코드가 왜곡되는 경우에는 HTTP 요청을 분석하여 인코딩 방법을 확인해야 합니다. HTTP 요청은 Get 요청과 Post 요청으로 나누어지므로 다음에서 별도로 논의하겠습니다.
Get 요청의 경우 브라우저의 기본 요청 방법이며, 제출 시 양식을 "Get"으로 설정한 경우의 제출 방법입니다. 다음과 같이 Firefox 브라우저를 통해 특정 콘텐츠를 확인합니다.
주소 표시줄은 
요청 콘텐츠는
문자열은 요청 라인에 저장되어 웹 서버로 전송됩니다. "Hyuga Hinata" 인코딩을 통해 브라우저에서 문자열에 대해 사용하는 인코딩 방법이 "UTF-8"임을 알 수 있습니다. 
서버 코드를 보면 아래와 같이 문자가 깨져 있는 것을 볼 수 있습니다. 이는 서버가 기본적으로 ISO-8859-1을 사용하여 문자열 인코딩을 받은 후 데이터를 디코딩하기 때문입니다. 접근 방식이 획일적이지 않습니다. 솔루션 회로도는 다음과 같습니다:
Java 웹 개발 과정에서 우리는 하이퍼링크로 매개변수를 전달하며 중국어 상황을 자주 접하게 됩니다. 이 경우 중국어를 인코딩해야 하며 이를 UTF-8로 설정할 수 있으며 디코딩 방식은 위와 동일합니다. 게시물 요청의 경우 폼 제출을 '게시'로 설정한 경우의 제출 방식입니다. 다음과 같이 Firefox 브라우저를 통해 특정 콘텐츠를 확인합니다. 주소 표시줄과 페이지는 다음과 같습니다. 게시물 요청 콘텐츠는 에서 위 그림에서 알 수 있듯이 게시 요청에서는 요청 내용이 요청 본문에 직접 배치되어 웹 서버로 전송되며 인코딩 방법은 "utf-8"입니다. 이 응답 Servlet에서 doPost 메소드 본문은 다음과 같습니다. 여기서 코드가 왜곡되는 이유는 여전히 코드 getParameter("user")가 웹 서버는 기본 디코딩 체계 "ISO-8859-1"을 사용하여 인코딩과 디코딩 체계 간에 불일치가 발생합니다. 해결 방법은 get request garbled 솔루션을 사용하는 것이지만 직접적으로 수행하는 더 간단한 솔루션이 있습니다. 메소드 본문의 인코딩을 지정합니다. /Decoding 구성표는 "utf-8"입니다. 계획은 다음과 같습니다. 이상으로 요청으로 인해 왜곡된 코드에 대한 분석이 완료되었습니다.
응답으로 인해 발생하는 잘못된 코드에 대해 다음과 같이 네 가지 방법을 포함해야 합니다. 그러나 이 두 가지 방법은 약간 다릅니다. 즉, setHeader("Content-Type", "text/html;cahrset=utf-8") 이 방법에서는 브라우저가 자동으로 다음과 같은 인코딩 방법을 사용합니다. 모든 브라우저가 setCharacterEncoding() 메서드를 디코딩하기 위해 이 메서드의 인코딩 메서드를 사용하는 것은 아닙니다. 아래에서 두 가지 메서드를 테스트하고 결과는 다음과 같습니다. 从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。 对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。 对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。 对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。 以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下: 此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示: 采用火狐浏览器进行测试,查看页面效果,及其响应结果如下: 经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。 所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。 效果如下:其中火狐浏览器并没有对其解码<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>

public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}
충격으로 인해 왜곡된 코드에서 웹 서버는 응답 내용을 응답 본문에 작성한 후 상태 줄을 포함하지 않고 클라이언트에 반환합니다. 예를 들어 브라우저에 "HelloWorld"가 출력되면 아래 그림과 같은 응답이 나옵니다.
인코딩 유형 설정 response.setHeader("Content-Type", "text/html;cahrset=utf-8") 및 response.setCharacterEncoding("utf-8")과 같은 응답 본문의 인코딩 방법입니다. 응답 본문의 인코딩 방법을 설정할 때 기본값은 ISO-8859-1이며 나중에 응답 본문 문자의 인코딩 방법을 설정하면 이전 설정 인코딩 방법이 반복됩니다. getWriter 메소드 이전에는 이 두 메소드 모두 유효하며, getWriter 메소드에서 인코딩을 설정하는 메소드는 유효하지 않습니다. 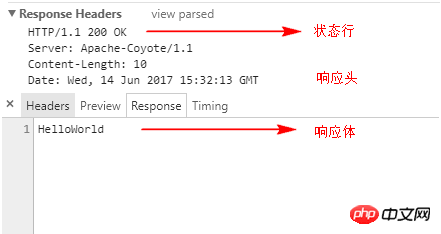 rreee
rreee
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
} public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}

public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}
위 내용은 JAVA WEB 참고 사항--한자가 깨져 있는 문자의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!