
Java에서 버퍼 소스 코드를 구문 분석합니다.

- 零下一度원래의
- 2017-06-17 12:44:191966검색
이 글은 주로 Java의 Buffer 소스 코드 분석 관련 정보를 소개하고 있습니다. 필요하신 분들은
Analytics of Buffer source code in java
Buffer
을 참고하시기 바랍니다. Buffer의 클래스 다이어그램은 다음과 같습니다. :
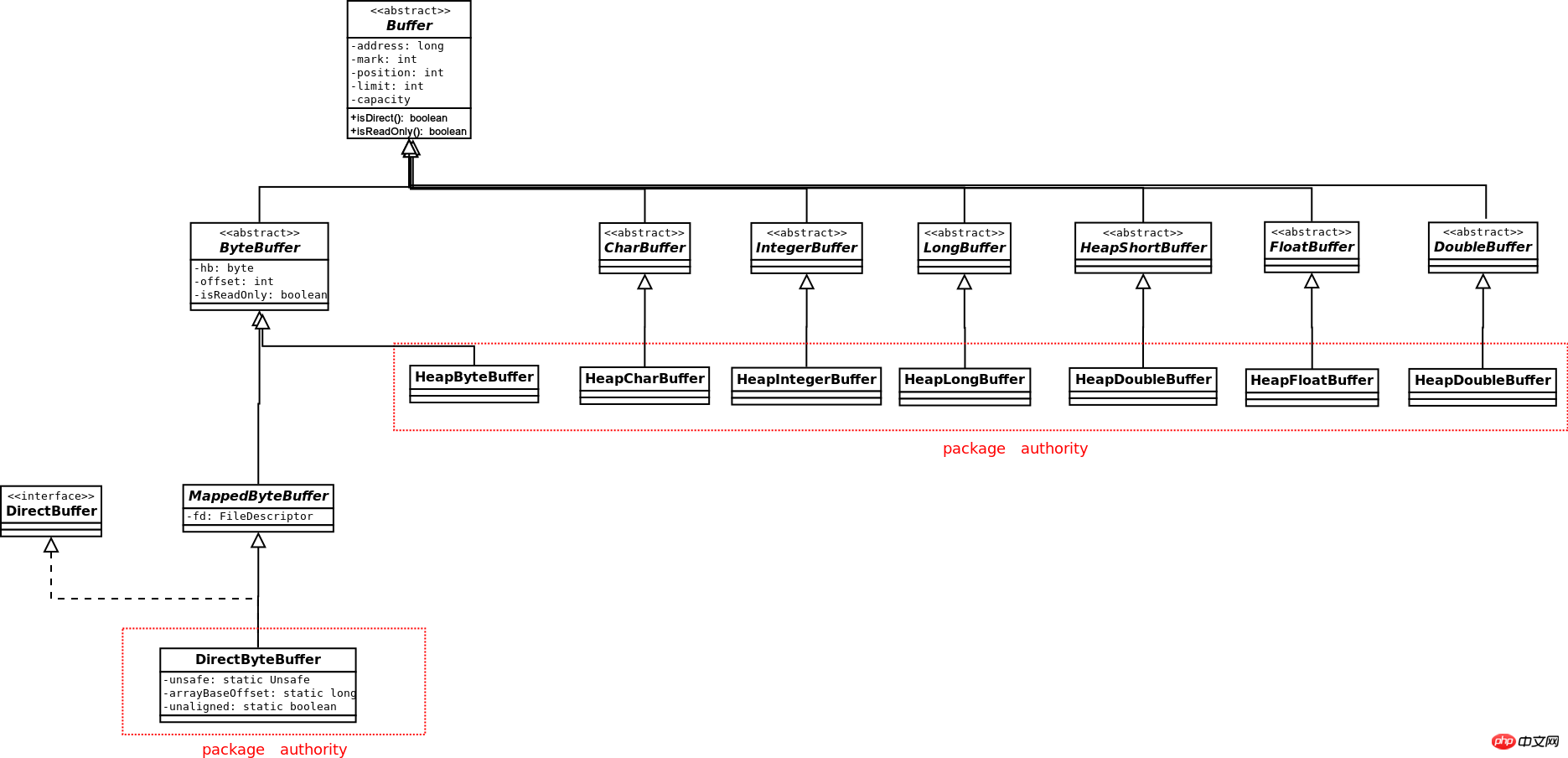
Boolean을 제외하고 다른 기본 데이터 유형에는 해당 버퍼가 있지만 ByteBuffer만 채널과 상호 작용할 수 있습니다. ByteBuffer만 Direct 버퍼를 생성할 수 있으며, 다른 데이터 유형의 버퍼는 Heap 유형 버퍼만 생성할 수 있습니다. ByteBuffer는 다른 데이터 유형의 뷰 버퍼를 생성할 수 있습니다. ByteBuffer 자체가 Direct인 경우 생성된 각 뷰 버퍼도 Direct입니다.
Direct 및 Heap 유형 버퍼의 본질
첫 번째 선택은 JVM이 IO 작업을 수행하는 방법에 대해 이야기하는 것입니다.
JVM은 운영 체제 호출을 통해 IO 작업을 완료해야 합니다. 예를 들어 읽기 시스템 호출을 통해 파일 읽기를 완료할 수 있습니다. 읽기의 프로토타입은 ssize_t read(int fd, void *buf, size_t nbytes)이며, 다른 IO 시스템 호출과 마찬가지로 일반적으로 매개변수 중 하나로 버퍼가 필요하며 버퍼는 연속적이어야 합니다.
버퍼는 직접 및 힙의 두 가지 범주로 구분됩니다. 이 두 가지 유형의 버퍼는 아래에 설명되어 있습니다.
Heap
Heap 유형의 버퍼는 JVM 힙에 존재합니다. 메모리의 이 부분의 재활용 및 배열은 일반 객체와 동일합니다. 힙 유형의 버퍼 객체에는 모두 기본 데이터 유형(예: final **[] hb)에 해당하는 배열 속성이 포함되어 있으며, 배열은 힙 유형 버퍼의 기본 버퍼입니다.
그러나 Heap 유형의 Buffer는 다음 두 가지 이유 때문에 시스템 호출의 버퍼 매개변수로 직접 사용할 수 없습니다.
JVM은 GC 중에 버퍼를 이동(복사 구성)할 수 있으며 버퍼의 주소는 고정되어 있지 않습니다.
시스템 호출을 할 때 버퍼는 연속적이어야 하지만 배열은 연속적이지 않을 수 있습니다(JVM 구현에서는 연속성이 필요하지 않습니다).
따라서 IO용 힙형 버퍼를 사용하는 경우 JVM은 임시 Direct형 버퍼를 생성한 다음 데이터를 복사한 다음 임시 Direct의
Buffer를 매개변수로 사용하여 운영 체제 호출을 수행해야 합니다. 이는 주로 다음 두 가지 이유로 인해 매우 낮은 효율성을 초래합니다.
데이터를 힙 유형 버퍼에서 임시 생성된 직접 버퍼로 복사해야 합니다.
많은 수의 Buffer 객체를 생성하여 GC 빈도를 높일 수 있습니다. 따라서 IO 작업 중에 Buffer를 재사용하여 최적화를 수행할 수 있습니다.
Direct
Direct형 버퍼는 힙에 존재하지 않고, JVM이 malloc을 통해 직접 할당한 연속 메모리로, 이 부분이 JVM에서 사용하는 다이렉트 메모리이다. IO 시스템 호출. 버퍼로 메모리를 직접 호출합니다.
-XX:MaxDirectMemorySize, 이 구성을 통해 할당이 허용되는 최대 직접 메모리 크기를 설정할 수 있습니다(MappedByteBuffer에 의해 할당된 메모리는 이 구성의 영향을 받지 않습니다).
직접 메모리 재활용은 힙 메모리 재활용과 다릅니다. 직접 메모리를 부적절하게 사용하면 OutOfMemoryError가 발생하기 쉽습니다. Java는 직접 메모리를 적극적으로 해제하는 명시적 방법을 제공하지 않습니다. sun.misc.Unsafe 클래스는 직접 기본 메모리 작업을 수행할 수 있으며, 이 클래스를 통해 직접 메모리를 적극적으로 해제하고 관리할 수 있습니다. 마찬가지로 효율성을 높이려면 직접 메모리를 재사용해야 합니다.
MappedByteBuffer와 DirectByteBuffer의 관계
이것은 약간 반대입니다. 당연히 MappedByteBuffer는 DirectByteBuffer의 하위 클래스여야 하지만 사양을 명확하고 단순하게 유지하고 최적화 목적을 위해 다른 방식으로 수행하는 것이 더 쉽습니다. 이는 DirectByteBuffer가 패키지 전용 클래스이기 때문에 작동합니다. (이 단락은 MappedByteBuffer의 소스 코드에서 가져왔습니다.)
사실 MappedByteBuffer는 매핑된 버퍼이지만(가상 메모리를 직접 살펴보세요) DirectByteBuffer는 그 내용만 보여줍니다. 메모리의 이 부분은 JVM이 직접 메모리 영역에 할당한 연속 버퍼가 항상 매핑되는 것은 아닙니다. 즉, MappedByteBuffer는 DirectByteBuffer의 하위 클래스여야 하나, 편의성과 최적화를 위해 MappedByteBuffer를 DirectByteBuffer의 부모 클래스로 사용한다. 또한, MappedByteBuffer는 논리적으로 DirectByteBuffer의 서브클래스여야 하고, MappedByteBuffer 메모리의 GC는 직접 메모리의 GC와 유사하지만(힙 GC와 다름), 할당된 MappedByteBuffer의 크기는 -XX:MaxDirectMemorySize의 영향을 받지 않는다. 매개변수.
MappedByteBuffer는 메모리 매핑된 파일 작업을 캡슐화합니다. 즉, 파일 IO 작업만 수행할 수 있습니다. MappedByteBuffer는 mmap을 기반으로 생성된 매핑 버퍼로, 이 부분은 해당 파일 페이지에 매핑되며, 사용자 모드에서는 직접 메모리에 속하며, 매핑된 버퍼는 MappedByteBuffer를 통해 직접 동작할 수 있다. 파일 페이지. 시스템에서 운영 체제는 해당 메모리 페이지를 호출하여 파일 쓰기를 완료합니다.
MappedByteBuffer
FileChannel.map(MapMode 모드, 긴 position, 긴 크기)을 통해 MappedByteBuffer를 가져옵니다. MappedByteBuffer 생성 과정은 아래 소스 코드와 함께 설명됩니다.
FileChannel.map 소스 코드:
public MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException
{
ensureOpen();
if (position < 0L)
throw new IllegalArgumentException("Negative position");
if (size < 0L)
throw new IllegalArgumentException("Negative size");
if (position + size < 0)
throw new IllegalArgumentException("Position + size overflow");
//最大2G
if (size > Integer.MAX_VALUE)
throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");
int imode = -1;
if (mode == MapMode.READ_ONLY)
imode = MAP_RO;
else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;
else if (mode == MapMode.PRIVATE)
imode = MAP_PV;
assert (imode >= 0);
if ((mode != MapMode.READ_ONLY) && !writable)
throw new NonWritableChannelException();
if (!readable)
throw new NonReadableChannelException();
long addr = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return null;
//size()返回实际的文件大小
//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。
if (size() < position + size) { // Extend file size
if (!writable) {
throw new IOException("Channel not open for writing " +
"- cannot extend file to required size");
}
int rv;
do {
//增大文件的大小
rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}
//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer
//并返回
if (size == 0) {
addr = 0;
// a valid file descriptor is not required
FileDescriptor dummy = new FileDescriptor();
if ((!writable) || (imode == MAP_RO))
return Util.newMappedByteBufferR(0, 0, dummy, null);
else
return Util.newMappedByteBuffer(0, 0, dummy, null);
}
//allocationGranularity的大小在我的系统上是4K
//页对齐,pagePosition为第多少页
int pagePosition = (int)(position % allocationGranularity);
//从页的最开始映射
long mapPosition = position - pagePosition;
//因为从页的最开始映射,增大映射空间
long mapSize = size + pagePosition;
try {
// If no exception was thrown from map0, the address is valid
//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,
//参见下面的说明
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted memory
// so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
end(IOStatus.checkAll(addr));
}
}map0 소스 코드 구현:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
//linux系统调用是通过整型的文件id引用文件的,这里得到文件id
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmap
mapAddress = mmap64(
0, /* Let OS decide location */
len, /* Number of bytes to map */
protections, /* File permissions */
flags, /* Changes are shared */
fd, /* File descriptor of mapped file */
off); /* Offset into file */
if (mapAddress == MAP_FAILED) {
if (errno == ENOMEM) {
//如果没有映射成功,直接抛出OutOfMemoryError
JNU_ThrowOutOfMemoryError(env, "Map failed");
return IOS_THROWN;
}
return handle(env, -1, "Map failed");
}
return ((jlong) (unsigned long) mapAddress);
}FileChannel.map()의 zise 매개 변수는 길지만 최대 크기는 정수입니다. MAX_VALUE 즉, 최대 2G 공간만 매핑할 수 있습니다. 실제로 운영체제에서 제공하는 MMAP은 더 큰 공간을 할당할 수 있지만 JAVA는 2G로 제한되어 있고 ByteBuffer 등의 버퍼는 최대 버퍼 크기인 2G까지만 할당할 수 있다.
MappedByteBuffer는 mmap을 통해 생성된 버퍼입니다. 버퍼의 이 부분은 운영 체제에서 직접 생성하고 관리합니다. 마지막으로 JVM에서는 unmmap을 통해 이 메모리 부분을 운영 체제에서 직접 해제할 수 있습니다.
Haep****Buffer
다음은 힙 유형 버퍼의 세부 사항을 설명하기 위해 ByteBuffer를 예로 들어 설명합니다.
이 유형의 버퍼는 다음과 같은 방법으로 생성될 수 있습니다.
ByteBuffer.allocate(int 용량)
ByteBuffer.wrap(byte[] array) 들어오는 배열을 기본 버퍼로 사용하여 배열은 버퍼에 영향을 미치며, 버퍼를 변경하면 배열에도 영향을 줍니다.
ByteBuffer.wrap(byte[] array, int offset, int length)
들어오는 배열의 일부를 기본 버퍼로 사용합니다. 배열의 해당 부분을 변경하면 버퍼에 영향을 미치고 버퍼도 변경됩니다. 배열에도 영향을 미칩니다.
DirectByteBuffer
DirectByteBuffer는 ByteBuffer.allocateDirect(int 용량)로만 생성할 수 있습니다.
ByteBuffer.allocateDirect() 소스 코드는 다음과 같습니다.
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}DirectByteBuffer() 소스 코드는 다음과 같습니다.
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}unsafe.allocateMemory() 소스 코드는 openjdk/src/openjdk/에 있습니다. 핫스팟/src/share/vm /prims/unsafe.cpp. 구체적인 소스코드는 다음과 같습니다.
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size;
if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
}
if (sz == 0) {
return 0;
}
sz = round_to(sz, HeapWordSize);
//最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal);
if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
}
//Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDJVM은 malloc을 통해 연속 버퍼를 할당합니다. 버퍼의 이 부분은 운영체제 호출을 위한 버퍼 매개변수로 직접 사용될 수 있습니다.
위 내용은 Java에서 버퍼 소스 코드를 구문 분석합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!