
Python의 문자열 정리 예제에 대한 자세한 설명

- Y2J원래의
- 2017-05-10 12:00:302468검색
이 글은 파이썬 데이터 클리닝의 문자열 처리 관련 내용을 주로 소개합니다. 필요한 친구들은 참고하시면 됩니다.
서문
데이터 클리닝은 Complex입니다. 지루한(쿠비) 작업이지만 전체 데이터 분석 과정에서 가장 중요한 연결고리이기도 합니다. 어떤 사람들은 분석 프로젝트 시간의 80%가 데이터를 정리하는 데 사용된다고 말합니다. 이상하게 들리지만 실제 작업에서는 그렇습니다. 데이터 정리에는 두 가지 목적이 있습니다. 첫 번째는 정리를 통해 데이터를 사용할 수 있도록 하는 것입니다. 두 번째는 데이터를 후속 분석에 더 적합하게 만드는 것입니다. 즉, 세척해야 할 "더티" 데이터와 세척해야 할 클린 데이터도 있습니다.
데이터 분석, 특히 텍스트 분석에서 문자 처리에는 많은 에너지가 필요하므로 문자 처리에 대한 이해도 데이터 분석에 있어서 매우 중요한 능력입니다.
문자열 처리 방법
우선 기본 방법이 무엇인지 알아보겠습니다.
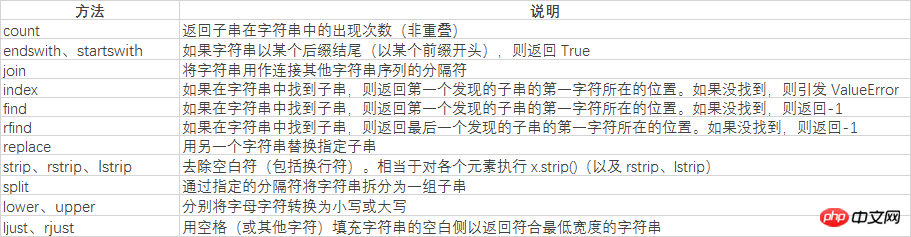
먼저 모두 이해해 봅시다. 다음 문자열 분할 방법
str='i like apple,i like bananer' print(str.split(','))
은 문자 str을 쉼표로 분할합니다.
['i like apple', 'i like bananer']
print(str.split(' '))
공백을 기준으로 분할한 결과:
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(',')) print(str.find(','))
두 검색 결과는 모두 다음과 같습니다.
12
찾지 못한 경우 index는 오류를 반환하고 find는 -1을 반환합니다.
print(str.count('i'))
결과는 다음과 같습니다.
4
connt는 대상 문자열의 빈도를 계산하는 데 사용됩니다.
print(str.replace(',', ' ').split(' '))
결과는 다음과 같습니다.
[' i', 'like', 'apple', 'i', 'like', 'bananer']
여기서 바꾸기는 쉼표를 공백으로 바꾼 다음 공백을 사용하여 문자열을 분할합니다. 모든 단어를 꺼내기에 충분합니다.
기존 방식 외에 더욱 강력한 문자 처리 도구 정규식이 바로 그것이다.
정규식
정규식을 사용하기 전에 정규식의 다양한 메소드를 이해해야 합니다.

다음 방법의 사용법을 먼저 살펴보겠습니다. 먼저 일치 방법과 검색 방법의 차이점을 이해하세요.
str = "Cats are smarter than dogs" pattern=re.compile(r'(.*) are (.*?) .*') result=re.match(pattern,str) for i in range(len(result.groups())+1): print(result.group(i))
결과는 다음과 같습니다.
고양이는 개보다 똑똑하다
고양이는
더 똑똑하다
이러한 형태의 pettern 매칭 규칙에서는 일치 결과와 검색 방법의 반환 결과가 동일합니다
이때 패턴을
pattern=re.compile(r'are (.*?) .*')
일치로 변경하면 아무 것도 반환되지 않으며 검색 결과는
are smarter입니다. 개보다
똑똑하다
다음에는 다른 방법의 사용법에 대해 알아보겠습니다
str = "138-9592-5592 # number" pattern=re.compile(r'#.*$') number=re.sub(pattern,'',str) print(number)
결과는 다음과 같습니다.
138-9592-5592
위의 작업은 숫자 추출 목적을 달성하기 위해 # 기호 뒤의 내용을 아무것도 없는 것으로 대체합니다.
숫자
print(re.sub(r'-*','',number))
의 크로스바를 추가로 교체할 수 있습니다. 결과는 다음과 같습니다.
13895925592
Us You find 메소드를 사용하여 찾은 문자열
str = "138-9592-5592 # number" pattern=re.compile(r'5') print(pattern.findall(str))
을 인쇄할 수도 있습니다. 결과는 다음과 같습니다:
['5', '5', '5']
정규식의 전체 내용은 비교적 방대하므로 문자열 일치 규칙에 대한 충분한 이해가 필요합니다. 구체적인 일치 규칙은 다음과 같습니다.

벡터화된 문자열함수
분석할 흩어진 데이터를 정리할 때 종종 문자열 정규화 작업을 수행합니다.
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)결과는 다음과 같습니다.

contains를 사용하여 각 데이터에 포함 여부를 판단하는 등 일부 통합 방법을 통해 데이터에 대한 예비 판단을 내릴 수 있습니다. key 단어
print(data.str.contains('@'))
의 결과는 다음과 같습니다.

문자열을 분할하여 필요한 문자열을 추출할 수도 있습니다.
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result) 대상: li [(120, qq, com)]
sun [(5243, gmail, com)]
wang [(5632, qq, com)]
zhao NaN
dtype:
object
print(result.str.get(0))결과는 다음과 같습니다.

print(result.str.get(1))결과는

data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])결과는 다음과 같습니다.

드디어 벡터화된 문자열 방식을 이해했습니다

요약
[관련 권장 사항 ]
위 내용은 Python의 문자열 정리 예제에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!