
키워드를 통해 웹 이미지를 크롤링하는 방법을 가르칩니다.

- Y2J원래의
- 2017-05-09 14:21:015307검색
이 글에서는 키워드를 통해 바이두 이미지를 크롤링하는 방식인 파이썬 크롤러를 주로 소개합니다. 참조 값이 매우 좋습니다. 아래 편집기를 사용하여 살펴보겠습니다
사용 도구: Python2.7, 다운로드하려면 여기를 클릭하세요
scrapy프레임워크
sublime text3
하나. Python 빌드(Windows 버전)
1.python2.7 설치 --- cmd에 python을 입력하면 인터페이스는 다음과 같으며 설치는 다음과 같습니다. 성공했습니다

2. Scrapy 프레임워크 통합----명령줄 입력: pip install Scrapy

성공적인 설치 인터페이스는 다음과 같습니다.
실패 상황이 많으며, 여기에 예가 있습니다. :
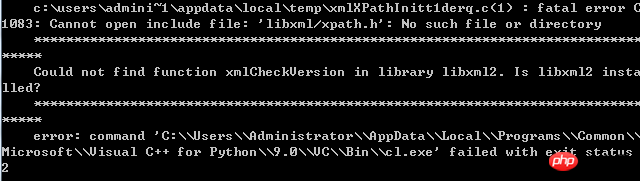
해결 방법:
둘. 프로그래밍을 시작하세요.
1. 크롤러 방지 조치 없이 정적 웹사이트를 크롤링합니다. 예를 들어 Baidu Tieba 및 Douban Reading이 있습니다.
예를 들어 "Desktop Bar"의 게시물 Tieba.baidu.com/p/2460150866?red_tag=3569129009
파이썬 코드는 다음과 같습니다.
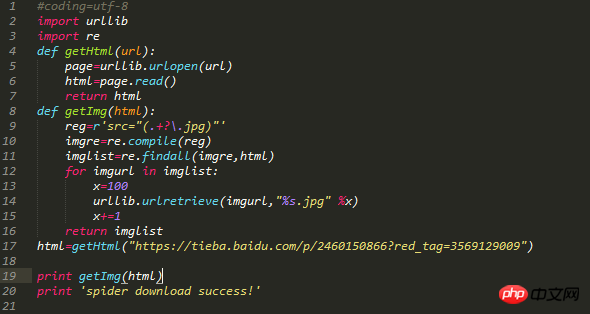
코드댓글: urllib, re라는 두 개의 모듈이 소개됩니다. 두 개의 함수를 정의합니다. 첫 번째 기능은 대상 웹페이지 전체 데이터를 얻는 것이고, 두 번째 기능은 대상 웹페이지에서 대상 이미지를 얻고, 웹페이지를 순회하고, 획득한 이미지를 시작으로 정렬하는 것입니다. 0부터.
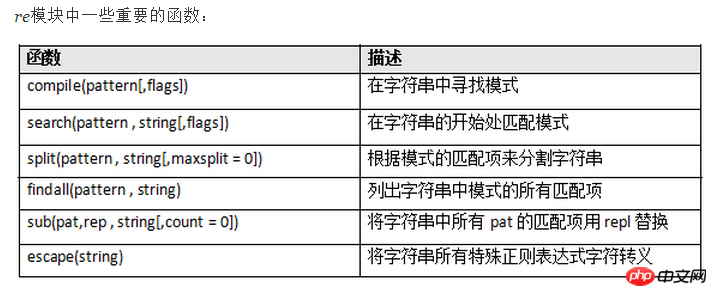
참고: 모듈 지식 포인트:
크롤링 이미지 렌더링:
이미지 기본적으로 , 저장 경로는 생성된 .py 파일과 동일한 디렉터리에 있습니다.
2. 크롤러 방지 조치를 통해 Baidu 이미지를 크롤링합니다. Baidu 사진 등
예를 들어 키워드 검색 "이모티콘 패키지" https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=% B1% ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps=111111
사진 스크롤 중입니다. 로드하려면 먼저 상위 30장의 사진을 크롤링하세요.
코드는 다음과 같습니다.
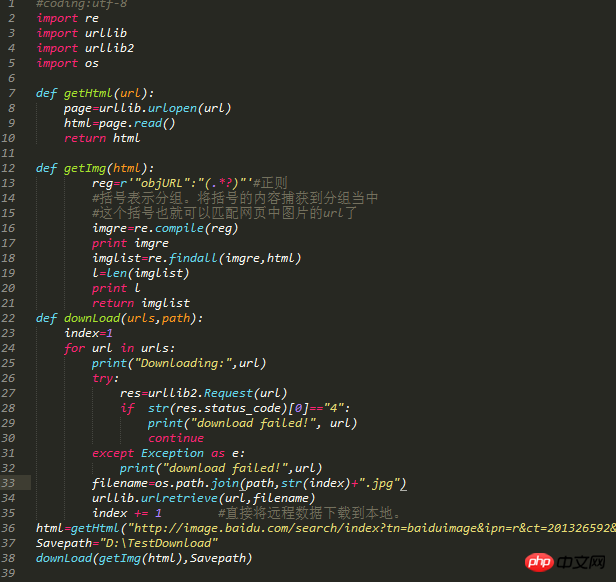
코드 설명: 4개의 모듈을 가져오고, os 모듈을 사용하여 저장을 지정합니다. 길. 처음 두 기능은 위와 동일합니다. 세 번째 함수는 if 문과 tryException 예외를 사용합니다.
크롤링 프로세스는 다음과 같습니다.
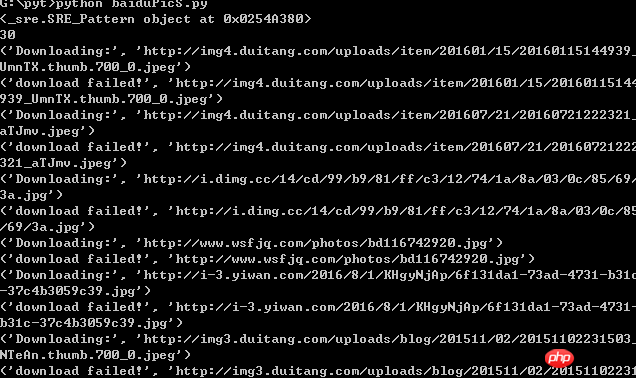
크롤링 결과:

참고: python 작성 코드 정렬에 주의하고, 오류를 보고하기 쉽기 때문에 탭과 공백을 혼합하지 마십시오.
[관련 추천]
위 내용은 키워드를 통해 웹 이미지를 크롤링하는 방법을 가르칩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!