
Python을 사용하여 w3shcool을 크롤링하고 이를 로컬 코드 예제에 저장하는 방법을 가르치는 과정

- Y2J원래의
- 2017-04-27 11:42:032252검색
이 글에서는 w3shcool의 JQuery 강좌를 Python이 크롤링하고 로컬에 저장하는 방법 분석을 주로 소개합니다. 매우 좋은 참조 값을 가지고 있습니다. 아래 에디터와 함께 살펴보겠습니다
최근에 일자리를 구하느라 바빴습니다. 틈틈이 기술을 연습하고 코드를 작성하기 위해 크롤러 프로젝트도 찾았습니다. , 하지만 Shushan에는 도로 작업이 더 많이 필요합니다. 테스트 피트가 있다면 자동화, 기능, 인터페이스 모두 가능하도록 소개해 주실 수 있나요?
우선 우리는 우리의 요구 사항을 명확하게 정의했습니다. 많은 학생들이 할 일이 없을 때 몇 가지 기술을 보고 싶어하지만 예를 들어 JQuery의 구문을 보고 싶지 않습니다. 지금은 인터넷이 있고 휴대폰에는 전자책이 없습니다. 정말 불편하니 걱정하지 마세요. 우선 여러분의 요구 사항을 충족시키기 위해 왔습니다. JQuery를 사용하면 이 필요성을 알 수 있고 응답하는 웹사이트가 있으므로 계속해서 이 웹사이트를 분석해 보겠습니다. www.w3school.com.cn/jquery/jquery_syntax.asp 이것이 문법 URL입니다. http://www.w3school.com.cn/jquery/jquery_intro.asp 이것이 소개 URL입니다. 그럼 URL 분석을 많이 했습니다. , 우리 www.w3school.com.cn/jquery 는 동일하므로 인터페이스에서 이를 얻는 방법을 분석해 보겠습니다. 오른쪽에 해당 대상 표시줄이 있는 것을 볼 수 있으므로 분석해 보겠습니다
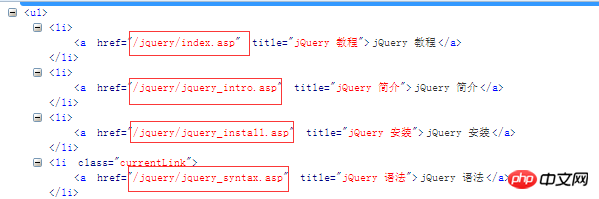
이 링크를 살펴보겠습니다. 우리는 이러한 링크를 http://www.w3school.com.cn과 연결할 수 있습니다. 그런 다음 새 URL
을 만들고
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text코드를 추가하면 url_s 함수를 사용하여 모든 링크를 가져올 수 있습니다.
['/jquery/index.asp', '/jquery/jquery_intro.asp', '/jquery/jquery_install.asp', '/jquery/jquery_syntax.asp', '/jquery/jquery_selectors.asp', '/jquery/jquery_events.asp', '/jquery/jquery_hide_show.asp', '/jquery/jquery_fade.asp', '/jquery/jquery_slide.asp', '/jquery/jquery_animate.asp', '/jquery/jquery_stop.asp', '/jquery/jquery_callback.asp', '/jquery/jquery_chaining.asp', '/jquery/jquery_dom_get.asp', '/jquery/jquery_dom_set.asp', '/jquery/jquery_dom_add.asp', '/jquery/jquery_dom_remove.asp', '/jquery/jquery_css_classes.asp', '/jquery/jquery_css.asp', '/jquery/jquery_dimensions.asp', '/jquery/jquery_traversing.asp', '/jquery/jquery_traversing_ancestors.asp', '/jquery/jquery_traversing_descendants.asp', '/jquery/jquery_traversing_siblings.asp', '/jquery/jquery_traversing_filtering.asp', '/jquery/jquery_ajax_intro.asp', '/jquery/jquery_ajax_load.asp', '/jquery/jquery_ajax_get_post.asp', '/jquery/jquery_noconflict.asp', '/jquery/jquery_examples.asp', '/jquery/jquery_quiz.asp', '/jquery/jquery_reference.asp', '/jquery/jquery_ref_selectors.asp', '/jquery/jquery_ref_events.asp', '/jquery/jquery_ref_effects.asp', '/jquery/jquery_ref_manipulation.asp', '/jquery/jquery_ref_attributes.asp', '/jquery/jquery_ref_css.asp', '/jquery/jquery_ref_ajax.asp', '/jquery/jquery_ref_traversing.asp', '/jquery/jquery_ref_data.asp', '/jquery/jquery_ref_dom_element_methods.asp', '/jquery/jquery_ref_core.asp', '/jquery/jquery_ref_prop.asp'], ['jQuery 教程', '', 'jQuery 教程', 'jQuery 简介', 'jQuery 安装', 'jQuery 语法', 'jQuery 选择器', 'jQuery 事件', '', 'jQuery 效果', '', 'jQuery 隐藏/显示', 'jQuery 淡入淡出', 'jQuery 滑动', 'jQuery 动画', 'jQuery stop()', 'jQuery Callback', 'jQuery Chaining', '', 'jQuery HTML', '', 'jQuery 获取', 'jQuery 设置', 'jQuery 添加', 'jQuery 删除', 'jQuery CSS 类', 'jQuery css()', 'jQuery 尺寸', '', 'jQuery 遍历', '', 'jQuery 遍历', 'jQuery 祖先', 'jQuery 后代', 'jQuery 同胞', 'jQuery 过滤', '', 'jQuery AJAX', '', 'jQuery AJAX 简介', 'jQuery 加载', 'jQuery Get/Post', '', 'jQuery 杂项', '', 'jQuery noConflict()', '', 'jQuery 实例', '', 'jQuery 实例', 'jQuery 测验', '', 'jQuery 参考手册', '', 'jQuery 参考手册', 'jQuery 选择器', 'jQuery 事件', 'jQuery 效果', 'jQuery 文档操作', 'jQuery 属性操作', 'jQuery CSS 操作', 'jQuery Ajax', 'jQuery 遍历', 'jQuery 数据', 'jQuery DOM 元素', 'jQuery 核心', 'jQuery 属性', '', ''])
모든 링크의 이름과 해당 링크의 해당 문법 모듈입니다. 그런 다음 다음 단계는 str splicing
['http://www.w3school.com.cn//jquery/index.asp', 'http://www.w3school.com.cn//jquery/jquery_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_install.asp', 'http://www.w3school.com.cn//jquery/jquery_syntax.asp', 'http://www.w3school.com.cn//jquery/jquery_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_events.asp', 'http://www.w3school.com.cn//jquery/jquery_hide_show.asp', 'http://www.w3school.com.cn//jquery/jquery_fade.asp', 'http://www.w3school.com.cn//jquery/jquery_slide.asp', 'http://www.w3school.com.cn//jquery/jquery_animate.asp', 'http://www.w3school.com.cn//jquery/jquery_stop.asp', 'http://www.w3school.com.cn//jquery/jquery_callback.asp', 'http://www.w3school.com.cn//jquery/jquery_chaining.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_get.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_set.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_add.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_remove.asp', 'http://www.w3school.com.cn//jquery/jquery_css_classes.asp', 'http://www.w3school.com.cn//jquery/jquery_css.asp', 'http://www.w3school.com.cn//jquery/jquery_dimensions.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_ancestors.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_descendants.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_siblings.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_filtering.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_load.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_get_post.asp', 'http://www.w3school.com.cn//jquery/jquery_noconflict.asp', 'http://www.w3school.com.cn//jquery/jquery_examples.asp', 'http://www.w3school.com.cn//jquery/jquery_quiz.asp', 'http://www.w3school.com.cn//jquery/jquery_reference.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_events.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_effects.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_manipulation.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_attributes.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_css.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_ajax.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_data.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_dom_element_methods.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_core.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_prop.asp']
를 사용하여 URL을 연결하는 것입니다. 그러면 이러한 URL이 모두 있으므로 기사 텍스트를 분석해 보겠습니다.
분석 결과 모든 텍스트가 id=maincontent에 있음을 알 수 있으며, 각 인터페이스에서 id=maincontent 태그를 직접 구문 분석하고 응답 텍스트 문서를 가져와 저장합니다.
따라서 모든 코드는 다음과 같습니다.
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()Results
이제 크롤링 작업이 완료되었으며 나머지는 사소한 것입니다. 수리와 소소한 개선이 있었지만, 주요 콘텐츠는 모두 완료했어야 했습니다.
사실 Python의 크롤러는 여전히 매우 간단합니다. 웹사이트의 요소를 분석하고 모든 요소의 공통 용어를 알아낼 수 있다면 문제를 매우 잘 분석하고 해결할 수 있습니다.
위 내용은 Python을 사용하여 w3shcool을 크롤링하고 이를 로컬 코드 예제에 저장하는 방법을 가르치는 과정의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!