
Hill 정렬을 구현하는 Python의 코드 예

- Y2J원래의
- 2017-04-24 15:43:411610검색
이 기사에서는 주로 Python의 Hill 정렬 구현을 소개합니다. 프로그래밍된 Hill 정렬에는 특정 참조 값이 있습니다. 관심 있는 친구는 이를 참조할 수 있습니다.
"삽입 정렬" 관찰: 실제로는 어렵지 않습니다. 그녀에게 단점이 있음을 발견합니다:
데이터가 "5, 4, 3, 2, 1"이면 이때 "순서가 지정되지 않은 블록"의 레코드를 "with" "시퀀스"에 삽입합니다. block"을 사용하면 충돌이 발생할 것으로 예상되며 삽입할 때마다 위치가 이동하게 됩니다. 이때 삽입 정렬의 효율성을 상상할 수 있습니다.
쉘은 이러한 약점을 기반으로 알고리즘을 개선하고 "감소 증분 정렬 방법"이라는 아이디어를 통합했습니다. 실제로는 매우 간단하지만 주목해야 할 점은 다음과 같습니다. , 그러나 따라야 할 규칙이 있습니다.
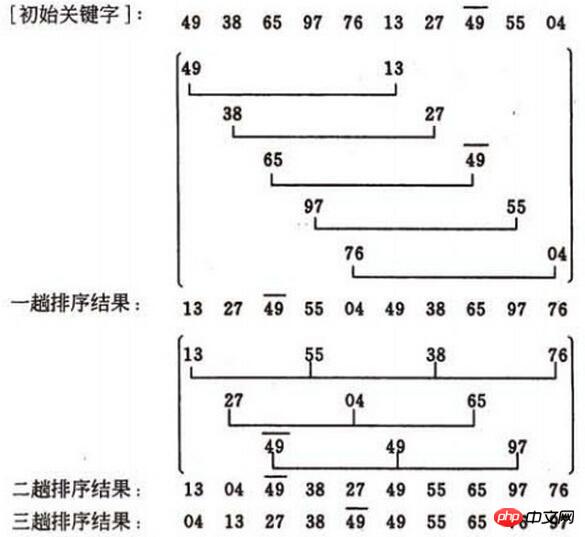 Hill 정렬의 적시성 분석은 어렵습니다.
Hill 정렬의 적시성 분석은 어렵습니다.
, 특정 상황에서 다음은 키 코드 비교 횟수와 기록된 동작 횟수를 정확하게 추정할 수 있습니다. 아직까지 최고의 증분 요소 순서를 선택하는 방법을 제시한 사람은 없습니다. 증분 인자의 순서는 홀수, 소수 등 다양한 방법으로 취할 수 있지만 증분 인자 중 1 외에는 공통 인자가 없으며 마지막 증분 인자는 1이어야 한다는 점에 유의해야 한다. 힐 정렬 방법은 불안정 정렬 방법입니다. 먼저 증가 방법을 명확히 해야 합니다(여기에 있는 사진은 다른 사람의 블로그에서 복사한 것이며, 증가는 홀수이고 아래 프로그래밍에서는 짝수를 사용합니다). 첫 번째 증분 선택 방법은 다음과 같습니다. d=count/2;
두 번째 증분은 d=(count/2)/2;
마지막으로 다음으로 이동합니다. d =1;
첫 번째 패스의 증분 d1=5는 10개의 레코드를 각각 5개의 하위 시퀀스로 나눕니다.
직접 삽입 정렬결과는 (13, 27, 49, 55, 04, 49, 38, 65, 97, 76)
두 번째 패스의 증분은 d2=3이고, 대기열에 추가될 10개의 레코드는 다음과 같습니다. 직접 삽입을 위해 3개의 하위 시퀀스로 나누어 결과는 (13, 04, 49, 38, 27, 49, 55, 65, 97, 76)세 번째 패스의 증분 d3=1입니다. 전체 시퀀스에 대해 직접 삽입 정렬을 수행하면
최종 결과
는 (04, 13, 27, 38, 49, 49, 55, 65, 76, 97) 여기서 핵심이 나옵니다. 증분량이 1로 감소하면 기본적으로 순서가 정렬됩니다. Hill 정렬의 마지막 단계는 직접 삽입 정렬이며 이는 최상의 상황에 가깝습니다. 이전 단계의 "매크로" 조정은 마지막 단계의 전처리로 간주될 수 있으며, 이는 직접 삽입 정렬을 하나만 수행하는 것보다 효율적입니다.
저는 Python을 배우고 있는데, 오늘은 Python을 사용하여 Hill 정렬을 구현했습니다. def ShellInsetSort(array, len_array, dk): # 直接插入排序
for i in range(dk, len_array): # 从下标为dk的数进行插入排序
position = i
current_val = array[position] # 要插入的数
index = i
j = int(index / dk) # index与dk的商
index = index - j * dk
# while True: # 找到第一个的下标,在增量为dk中,第一个的下标index必然 0<=index<dk
# index = index - dk
# if 0<=index and index <dk:
# break
# position>index,要插入的数的下标必须得大于第一个下标
while position > index and current_val < array[position-dk]:
array[position] = array[position-dk] # 往后移动
position = position-dk
else:
array[position] = current_val
def ShellSort(array, len_array): # 希尔排序
dk = int(len_array/2) # 增量
while(dk >= 1):
ShellInsetSort(array, len_array, dk)
print(">>:",array)
dk = int(dk/2)
if __name__ == "__main__":
array = [49, 38, 65, 97, 76, 13, 27, 49, 55, 4]
print(">:", array)
ShellSort(array, len(array))출력:
>: [49, 38, 65, 97, 76, 13, 27, 49, 55, 4] >>: [13, 27, 49, 55, 4, 49, 38, 65, 97, 76] >>: [4, 27, 13, 49, 38, 55, 49, 65, 97, 76] >>: [4, 13, 27, 38, 49, 49, 55, 65, 76, 97]
우선 삽입 정렬을 알아야 합니다. 그렇지 않으면 절대 이해하지 못할 것입니다.
삽입정렬은 위 그림의 노란색 박스 3개에 숫자를 넣어서 정렬하는 것입니다. 예: 13, 55, 38, 76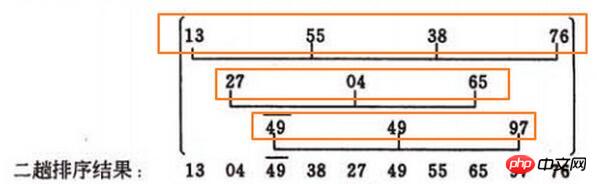 움직이지 않고 55, 55<13을 똑바로 보세요. 그런 다음 38, 38
움직이지 않고 55, 55<13을 똑바로 보세요. 그런 다음 38, 38
여기에 문제가 있습니다. 예를 들어 두 번째 노란색 상자
[27, 4, 65], 4<27, 27이 뒤로 이동한 다음 4가 첫 번째 상자를 대체하고 데이터는 다음과 같습니다. [ 4, 27, 65],그런데 컴퓨터는 4가 첫 번째라는 것을 어떻게 알 수 있나요??
제 접근 방식은 먼저 [27, 4, 65 중 첫 번째를 찾는 것입니다. ] 숫자의 첨자 이 예에서 27의 첨자는 1입니다. 삽입할 숫자의 첨자가 첫 번째 첨자 1보다 큰 경우 뒤로 이동할 수 있습니다.
이전 숫자는 뒤로 이동할 수 없습니다. 앞에 데이터가 있고 삽입하려는 숫자보다 작을 경우 뒤에만 삽입할 수 있습니다. 또 한 가지 매우 중요한 점은 삽입할 숫자가 이전 숫자보다 작을 경우 삽입할 숫자를 먼저 넣어야 한다는 점입니다. 이때 삽입할 숫자의 첨자 = 첫 번째 숫자의 첨자입니다. (이 구절은 초보자에게는 잘 이해되지 않을 수도 있습니다...)첫 번째 숫자의 첨자를 찾기 위해 제가 가장 먼저 생각한 것은 루프를 앞쪽까지 사용하는 것이었습니다. while True: # 找到第一个的下标,在增量为dk中,第一个的下标index必然 0<=index<dk
index = index - dk
if 0<=index and index <dk:
break
시간 복잡도:
Hill 정렬의 시간 복잡도는 취해진 증분 시퀀스의 함수입니다. 정확하게 분석하기 어렵습니다. 일부 문헌에서는 증분 시퀀스가 d[k]=2^(t-k+1)일 때 Hill 정렬의 시간 복잡도는
O(n^1.5),이며 여기서 t는 숫자를 정렬한다고 지적합니다. 여행의.
안정성: 불안정
힐 정렬 효과: 참고: 프로그래밍은 제가 직접 구현합니다. 디버깅하고 실행되는 프로세스를 살펴보는 것이 좋습니다 C++의 8가지 주요 정렬 알고리즘 자주 사용되는 여러 정렬 알고리즘을 시각적, 직관적으로 경험해 보세요 세븐 C#의 클래식 정렬 알고리즘 시리즈(2부) 1. 비체계적인 학습도 시간낭비 2. 아름다움을 감상하고, 예술을 이해하고, 예술을 아는 기술인이 되자
위 내용은 Hill 정렬을 구현하는 Python의 코드 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!