
집 >데이터 베이스 >MySQL 튜토리얼 >다양한 상황에서의 MySQL 마이그레이션 솔루션(권장)
다양한 상황에서의 MySQL 마이그레이션 솔루션(권장)

- 怪我咯원래의
- 2017-04-06 10:36:181406검색
1. 마이그레이션을 하는 이유
MySQL 마이그레이션은 DBA의 일상적인 유지 관리 작업입니다. 원래 의미에서 마이그레이션은 객체의 무결성과 연속성을 보장하기 위해 실제 존재하는 객체를 제거하는 것에 지나지 않습니다. 부드러운 해변처럼, 순수한 두 아이들은 마음의 성을 쌓기 위해 모래더미를 다른 곳으로 옮겼습니다.
프로덕션 환경에서 다음과 같은 경우 마이그레이션 작업이 필요합니다.
디스크 공간이 부족합니다. 예를 들어, 일부 오래된 프로젝트에서는 선택한 모델이 반드시 데이터베이스에 적합하지 않을 수 있습니다. 시간이 지나면서 하드 드라이브의 공급이 부족해질 가능성이 높습니다.
비즈니스 병목 현상이 발생할 수 있습니다. 예를 들어, 이 프로젝트에서는 단일 시스템을 사용하여 모든 읽기 및 쓰기 서비스를 수행하므로 비즈니스 압박이 가중되고 압도됩니다. IO 압력이 허용 범위 내에 있으면 읽기-쓰기 분리 솔루션이 채택됩니다.
기계에 병목 현상이 발생합니다. 머신의 주요 병목 현상은 디스크 IO 기능, 메모리 및 CPU입니다. 병목 현상을 최적화하는 것 외에도 마이그레이션은
프로젝트 변환에 좋은 솔루션입니다. 일부 프로젝트의 데이터베이스는 컴퓨터실에 걸쳐 있으며 노드가 다른 컴퓨터실에 추가되거나 컴퓨터가 한 컴퓨터실에서 다른 컴퓨터실로 이동할 수 있습니다. 또 다른 예를 들어, 여러 기업이 동일한 서버를 공유하는 경우 서버에 대한 부담을 완화하고 유지 관리를 용이하게 하기 위해 마이그레이션이 수행됩니다.
한마디로 이민은 최후의 수단이다. 마이그레이션 작업을 구현하는 목적은 비즈니스를 원활하고 지속적으로 운영하는 것입니다.
2. MySQL 마이그레이션 계획 개요
MySQL 마이그레이션은 데이터를 처리하고 계속 확장하는 것에 지나지 않으며, 원활하고 지속적인 사업 운영. 문제는 백업과 복구를 어떻게 빠르고 안전하게 수행하느냐이다.
한편으로는 백업. 각 마스터 노드의 슬레이브 노드 또는 백업 노드에 대한 백업이 있습니다. 이 백업은 전체 백업이거나 증분 백업일 수 있습니다. 온라인 백업 방법으로는 mysqldump, xtrabackup 또는 mydumper를 사용할 수 있습니다. 10GB 미만의 소용량 데이터베이스 백업에는 mysqldump를 사용할 수 있습니다. 그러나 대용량 데이터베이스(수백 GB 또는 TB 수준)의 경우 mysqldump 백업을 사용할 수 없습니다. 한편으로는 잠금이 생성되고 시간이 너무 오래 걸립니다. 이 경우 xtrabackup을 선택하거나 데이터 디렉터리를 직접 복사할 수 있습니다. 데이터 디렉터리 방법을 직접 복사하면 rsync를 사용하여 다른 시스템 간에 전송할 수 있습니다. 시간 소모는 네트워크에 따라 다릅니다. xtrabackup을 사용하면 주로 백업 및 네트워크 전송에 시간이 많이 소요됩니다. 이는 전체 또는 지정된 라이브러리 백업 파일이 있는 경우 백업을 얻는 가장 좋은 방법입니다. 대기 데이터베이스가 서비스 중지를 허용할 수 있는 경우 데이터 디렉터리를 직접 복사하는 것이 가장 빠른 방법입니다. 대기 데이터베이스가 서비스 중지를 허용하지 않는 경우 백업을 완료하는 데 가장 적합한 xtrabackup(InnoDB 테이블을 잠그지 않음)을 사용할 수 있습니다.
한편 회복. 소용량(10GB 미만) 데이터베이스의 백업 파일의 경우 직접 가져올 수 있습니다. 대용량 데이터베이스(수백 GB 또는 TB급) 복구의 경우 백업 파일을 로컬 머신에 가져온 후 복구가 어렵지 않습니다. 구체적인 복구 방법은 섹션 4를 참조하세요.
3. 실용적인 MySQL 마이그레이션
마이그레이션이 필요한 이유와 수행 방법을 이해한 후 프로덕션 환경이 어떻게 작동하는지 살펴보겠습니다. 다양한 애플리케이션 시나리오에는 다양한 솔루션이 있습니다.
구체적인 실제 전투를 읽기에 앞서 독자는 다음과 같은 동의를 한 것으로 가정합니다.
개인정보 보호를 위해 본 내용에는 서버 IP 및 기타 정보가 포함되어 있습니다.
서버가 같은 전산실에 있는 경우, 해당 서버 대신 서버 IP의 D 세그먼트를 사용하세요. 🎜>아키텍처 다이어그램
- 서버가 다른 컴퓨터실에 있는 경우 서버 대신 서버 IP의 C 및 D 세그먼트를 사용하십시오. 특정 IP
각 시나리오마다 방법이 제공되지만, 각 단계에서 실행되는 명령은 자세히 제공되지 않습니다. 이로 인해 글이 너무 길어질 수도 있기 때문입니다. 반면에 방법만 알면 구체적인 방법은 나올 것이라고 생각하는데, 이는 지식의 습득 정도와 정보 획득 능력에 달려 있습니다. > 실제 전투 시 주의사항은 5장을 참고하시기 바랍니다.
- 3.1 시나리오 1 라이브러리에서 하나의 마스터와 하나의 슬레이브 구조 마이그레이션
쉬운 것부터 어려운 것까지 아이디어에 따라 간단한 것부터 시작합니다. 구조. 프로젝트 A는 원래 마스터-슬레이브 구조였습니다. 101은 마스터 노드이고 102는 슬레이브 노드입니다. 비즈니스 요구로 인해 102는 노드 103에서 마이그레이션되었습니다. 아키텍처 다이어그램은 그림 1에 표시됩니다. 102 슬레이브 노드의 데이터 용량이 너무 커서 mysqldump를 사용하여 백업할 수 없습니다. R&D와 소통 후 일관된 계획을 수립합니다.
그림 1 마스터-슬레이브 구조 마이그레이션 슬레이브 라이브러리 아키텍처 다이어그램
구체적인 방법은 다음과 같습니다. 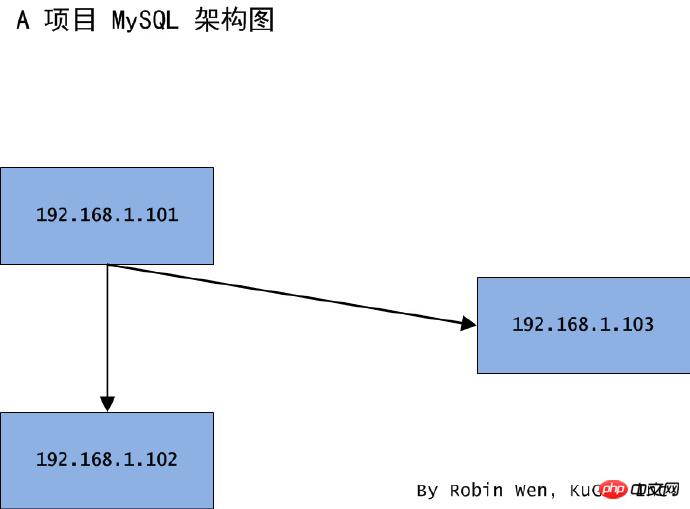
R&D는 102 읽기 업무는 메인 데이터베이스로 잘라냅니다.
102 MySQL 상태를 확인하고(주로 PROCESS LIST를 보고) 머신 트래픽을 관찰하여 올바른지 확인한 후, 102 슬레이브 노드의 서비스를 중지합니다.
103 새 MySQL 인스턴스를 생성한 후 MySQL 서비스를 중지하고 전체 데이터 디렉터리 mv를 다른 위치에 복사합니다.
102의 전체 mysql 데이터를 이동합니다. rsync를 사용하여 디렉터리를 103으로 복사합니다.
복사하는 동안 103이 binlog 풀 권한(REPLICATION SLAVE, REPLICATION CLIENT)
-
복사 완료 후 103
config 파일 에서 server_id를 수정하세요. 일관성이 없도록 주의하세요. -
103에서 MySQL 인스턴스를 시작합니다. 구성 파일의 데이터 파일 경로와 데이터 디렉터리의 권한을 참고하세요. 🎜>
103 MySQL 인스턴스를 입력하고 SHOW SLAVE STATUS를 사용하여 슬레이브 라이브러리의 상태를 확인하면 Seconds_Behind_Master가 감소하는 것을 볼 수 있습니다. - Seconds_Behind_Master가 0이 된 후 이때 pt-table-checksum을 사용하여 101과 103의 데이터가 일치하는지 확인할 수 있지만 시간이 많이 걸리고 마스터 노드에 영향을 미치게 됩니다. 데이터 일관성을 함께 확인하세요.
- 데이터 일관성을 확인하는 것 외에도 비즈니스가 다시 이전된 후 액세스 오류를 방지하려면 계정 권한도 확인해야 합니다. 🎜>
- 위 단계를 완료한 후 R&D와 협력하여 독서 사업의 일부를 101에서 103으로 전환하고 사업 상태를 관찰할 수 있습니다.
- 비즈니스에는 문제가 없습니다. 마이그레이션이 성공했음을 증명하십시오.
3.2 시나리오 2: 지정된 라이브러리를 마이그레이션하기 위한 하나의 마스터와 하나의 슬레이브 구조
- 슬레이브 라이브러리만 마이그레이션하는 방법을 알고 난 후 하나의 마스터와 하나의 슬레이브, 그러면 마스터와 슬레이브 노드를 동시에 마이그레이션하는 방법을 살펴보겠습니다. 여러 기업이 동시에 동일한 서버에 접속하기 때문에 단일 데이터베이스에 대한 부담이 너무 크고 관리가 불편합니다. 따라서 마스터 노드(101)와 슬레이브 노드(102)를 동시에 새로운 머신(103, 104)으로 마이그레이션할 계획이며, 103은 마스터 노드로, 104는 슬레이브 노드로 동작합니다. 아키텍처 다이어그램이 그림에 표시되어 있습니다. 2. 이 마이그레이션에는 지정된 라이브러리만 마이그레이션하면 됩니다. 이러한 라이브러리의 용량은 너무 크지 않으며 데이터가 실시간이 아니라는 것을 보장할 수 있습니다.
구체적인 방법은 다음과 같습니다.
103 및 104 새 인스턴스를 생성하고 마스터-슬레이브 관계를 설정합니다. 이때 마스터 노드와 슬레이브 노드가 언로드됩니다.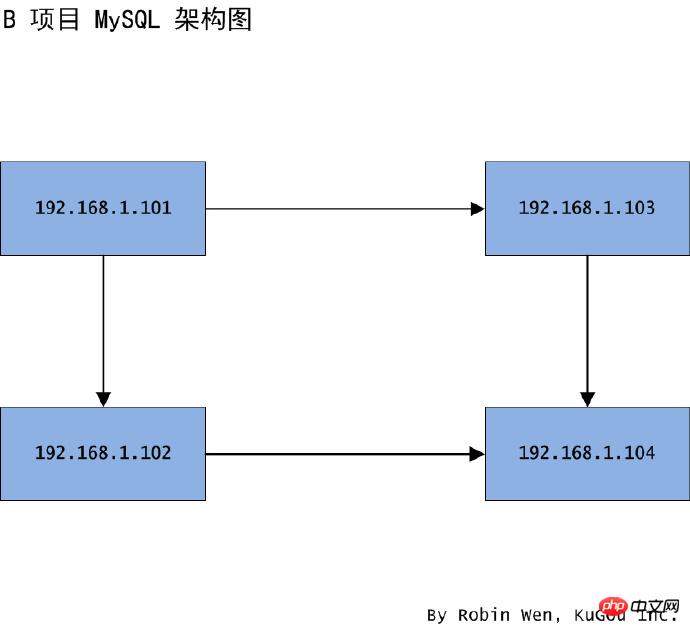
- 102 지정된 라이브러리에 필요한 계정 및 권한을 수집합니다.
- 102 데이터 내보내기가 완료되었습니다. rsync를 103으로 전송하고, 필요한 경우 압축 작업을 수행합니다.
- 103 데이터 가져오기, 데이터가 자동으로 104로 동기화되고 서버 상태를 모니터링합니다. MySQL 상태
- 103 가져오기가 완료되고, 104 동기화가 완료되고, 102에서 수집한 계정에 따라 103이 승인됩니다. 완료 후 데이터 및 계정 권한을 확인하기 위해 R&D에 알림이 전송됩니다. ;
- 위 작업이 완료되면 R&D 협력을 통해 101 및 102의 비즈니스를 103 및 104로 마이그레이션하고 비즈니스 상태를 관찰할 수 있습니다. >
사업에 문제가 없다면 마이그레이션 성공입니다.
3.3 시나리오 3 마스터-슬레이브 구조의 지정 도서관 양방향 이관
다음으로 지정 도서관을 마스터-슬레이브 구조로 양방향 이관하는 방법을 살펴보겠습니다. 마스터-슬레이브 구조. 서버가 큰 압박을 받고 관리가 혼란스러운 것도 서비스 공유 때문이다. 따라서 마스터 노드(101)와 슬레이브 노드(102)를 새로운 머신(103, 104, 105, 106)으로 동시에 마이그레이션하여 104의 마스터 노드 역할을 하고, 104가 슬레이브 노드 역할을 하도록 계획하고 있다. 103의 105는 106의 마스터 노드 역할을 하고 106은 105의 마스터 노드 역할을 합니다. 노드에서 아키텍처 다이어그램은 그림 3에 표시됩니다. 이 마이그레이션에는 지정된 라이브러리만 마이그레이션하면 됩니다. 이러한 라이브러리의 용량은 너무 크지 않으며 데이터가 실시간이 아니라는 것을 보장할 수 있습니다. 이 마이그레이션은 두 번 마이그레이션된다는 점을 제외하면 시나리오 2와 매우 유사하다는 것을 알 수 있습니다.
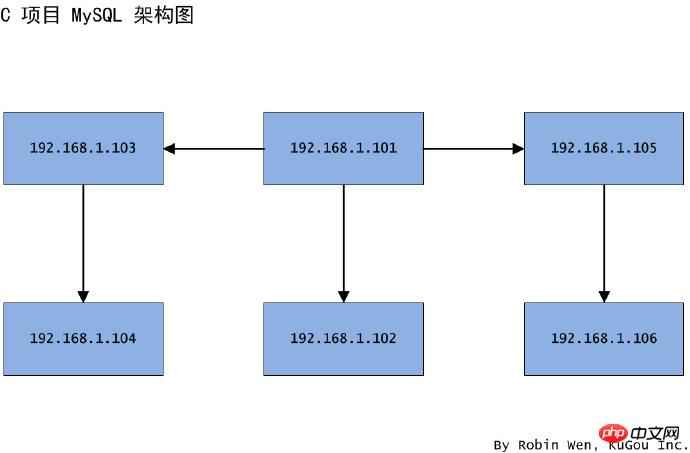
그림 3. 특정 라이브러리 아키텍처 다이어그램의 하나의 마스터와 하나의 슬레이브 구조 양방향 마이그레이션 다이어그램
구체적인 방법은 다음과 같습니다.
-
103 및 104 새 인스턴스를 생성하고 마스터-슬레이브 관계를 설정합니다. 이때 마스터 노드와 슬레이브 노드가 언로드됩니다.
102 필요한 지정된 라이브러리 데이터를 내보냅니다. 올바른 방법은 예약된 작업을 구성하는 것입니다. 비즈니스 사용량이 적은 동안 내보내기 작업을 수행하려면 여기에서 mysqldump를 선택합니다.
102 필요한 지정된 라이브러리에 필요한 계정과 권한을 수집합니다. by 103;
102 103에 필요한 지정된 라이브러리 데이터를 내보냅니다. rsync를 사용하여 103으로 전송하고 필요한 경우 압축 작업을 수행합니다. 103 데이터 가져오기 이때 데이터는 자동으로 104. 모니터 서버 상태 및 MySQL 상태
103 가져오기 완료, 104 동기화 완료, 103 기반으로 승인됩니다. 102에서 수집한 계정, 완료 후 R&D에 통보하여 데이터 및 계정 권한을 확인합니다.
위 완료 후 R&D와 협력하여 101 및 102의 비즈니스를 103 및 104로 마이그레이션합니다. , 비즈니스 상태를 관찰합니다.
105 및 106의 새 인스턴스를 생성하고 마스터-슬레이브 관계를 구축합니다. 현재 마스터 노드와 슬레이브 노드는 로드되지 않습니다.
102 105에서 요구하는 지정된 데이터베이스 데이터를 내보냅니다. 올바른 방법은 예약된 작업을 구성하고 업무량이 적을 때 수행하는 것입니다. 내보내기 작업의 경우 여기에서 mysqldump를 선택합니다.
102 지정된 라이브러리에 필요한 계정 및 권한을 수집합니다. 105
102 내보내기 105 필요한 지정된 라이브러리 데이터가 완료되었습니다. rsync를 사용하여 전송합니다. 105, 필요한 경우 압축 작업을 수행합니다.
105는 데이터를 가져오며, 데이터는 자동으로 106에 동기화되어 서버 상태와 MySQL 상태를 모니터링합니다. ;
105 가져오기가 완료되고, 106 동기화가 완료되고, 102에서 수집한 계정에 따라 105가 승인되며, 완료 후 데이터 및 계정 권한을 확인하기 위해 R&D에 알림이 전송됩니다.
위 작업 완료 후 R&D와 협력하여 101, 102 사업을 105, 106 사업으로 이전하고 사업 현황을 관찰합니다.
모든 비즈니스에 문제가 있으면 마이그레이션이 성공합니다.
- 3.4 시나리오 4: 1개의 마스터와 1개의 슬레이브 구조 마스터와 슬레이브의 완전 마이그레이션
다음으로 완전히 마이그레이션하는 방법을 살펴보겠습니다. 하나의 마스터와 하나의 슬레이브의 마스터 및 슬레이브 구조를 마이그레이션합니다. 시나리오 2와 유사하지만 여기서는 모든 라이브러리가 마이그레이션됩니다. 마스터 노드 101의 IO 병목 현상으로 인해 우리는 마스터 노드 101과 슬레이브 노드 102를 동시에 새로운 머신 103과 104로 마이그레이션할 계획이며, 103은 마스터 노드 역할을 하고 104는 슬레이브 노드 역할을 합니다. 마이그레이션이 완료되면 이전 마스터 노드와 슬레이브 노드는 폐기됩니다. 아키텍처 다이어그램은 그림 4에 나와 있습니다. 이 마이그레이션은 대용량의 전체 데이터베이스 마이그레이션이며 실시간으로 수행되어야 합니다. 이 마이그레이션은 채택된 전략이 새 슬레이브 데이터베이스를 먼저 교체한 다음 새 마스터 데이터베이스를 교체하는 것이기 때문에 특별합니다. 그래서 방법이 조금 더 복잡해졌습니다.
그림 41 마스터-슬레이브 구조 완전 마이그레이션 마스터-슬레이브 아키텍처 다이어그램
구체적인 방법은 다음과 같습니다. 
R&D 102의 읽기 업무를 메인 데이터베이스로 차단합니다.
102 MySQL 상태(주로 PROCESS LIST, MASTER STATUS 참조)를 확인하고 머신 트래픽을 관찰한 후 확인합니다. 맞습니다. 102 슬레이브 노드의 서비스를 중지합니다. ;
104 새 MySQL 인스턴스를 생성한 후 MySQL 서비스를 중지하고 전체 데이터 디렉터리 mv를 다른 위치에 복사합니다. 백업. 여기서 작업은 미래인 104입니다.
-
rsync를 사용하여 102의 전체 mysql 데이터 디렉터리를 104로 복사합니다. 🎜>
복사하는 동안 101에 권한을 부여하여 104 binlog를 가져올 수 있는 권한을 부여합니다(REPLICATION SLAVE, REPLICATION CLIENT). 복사가 완료된 후 104 구성 파일에서 server_id를 수정합니다. 102의 구성 파일과 일치하지 않도록 주의하세요.
104의 MySQL 인스턴스, 구성 파일에 주의하십시오. 데이터 파일 경로 및 데이터 디렉토리의 권한
104 MySQL 인스턴스를 입력하고 SHOW SLAVE STATUS를 사용하여 상태를 확인하십시오. 슬레이브 라이브러리에서 Seconds_Behind_Master가 감소하는 것을 볼 수 있습니다.
Seconds_Behind_Master가 0이 되면 동기화가 완료되었음을 의미합니다. 이때 pt-table-checksum을 사용하여 확인할 수 있습니다. 101과 104의 데이터는 일치하지만 시간이 많이 걸리고 마스터 노드에 영향을 미칩니다. 데이터 일관성 검증은
데이터 일관성 검증 외에도 비즈니스 마이그레이션 후 접속 오류를 방지하기 위해 계정 권한도 검증해야 합니다.
-
기존 102 슬레이브 노드의 읽기 사업을 104로 전환하기 위해 R&D와 협력합니다. ;
102의 데이터를 사용하여 103을 101의 슬레이브 노드로 변경합니다. 방법은 위와 동일합니다. 핵심은 104를 103의 슬레이브 라이브러리로 전환해야 한다는 것입니다.
- 104 STOP SLAVE ;
103 STOP SLAVE IO_THREAD;
103 STOP SLAVE SQL_THREAD, MASTER_LOG_FILE 및 MASTER_LOG_POS를 기억하세요.
-
104 START SLAVE UNTIL을 위의 MASTER_LOG_FILE 및 MASTER_LOG_POS로 설정하세요.
104 STOP SLAVE 다시
104 RESET SLAVE ALL 슬레이브 구성 정보 지우기; 103 MASTER_LOG_FILE 및 MASTER_LOG_POS를 기억하세요.
104에 binlog 액세스 권한을 부여합니다.
-
104 MASTER를 103으로 변경;
104 MySQL을 다시 시작합니다. RESET SLAVE ALL 이후 SLAVE STATUS를 확인하면 Master_Server_Id가 여전히 103이 아닌 101입니다.
104 MySQL이 다시 시작된 후, 이때 IO_THREAD와 SQL_THREAD가 YES인지 확인하세요.
- 103 START SLAVE 상태를 보시면 됩니다. 103과 104 이때, 104가 예전에는 101의 슬레이브 노드였으나 지금은 103의 슬레이브 노드가 된 것을 알 수 있습니다.
비즈니스 마이그레이션 전 103과 101 간의 동기화 관계를 해제하세요.
위 단계를 완료한 후 R&D 조정을 통해 101의 읽기 및 쓰기 사업을 다시 102로, 독서 사업을 104로 전환할 수 있다. 이때 101과 103을 모두 쓸 수 있다는 점에 유의해야 합니다. 쓰기 없이 101이 103으로 전환되는지 확인해야 합니다. FLUSH TABLES WITH READ LOCK을 사용하여 101을 잠근 다음 103으로 전환할 수 있습니다. 업무는 사용량이 적은 시간에 실행되어야 합니다.
- 전환이 완료된 후 업무 상태를 관찰하세요. 비즈니스에 문제가 없다면 마이그레이션 성공을 증명하세요.
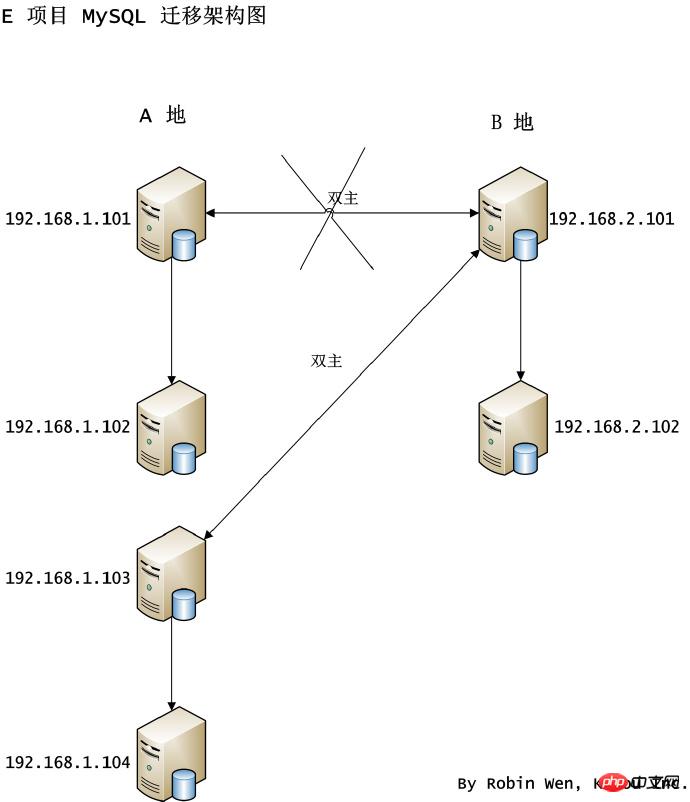
- 3.5 시나리오 5 이중-1차 구조 컴퓨터실 간 마이그레이션 이중-1차 구조 간 컴퓨터실 마이그레이션을 수행하는 방법을 살펴보겠습니다. 컴퓨터실 이주. 재해 복구를 위해 특정 프로젝트에서는 교차 기계실을 사용하고 양면에 쓸 수 있는 이중 마스터 구조를 채택합니다. 디스크 공간 문제로 인해 위치 A의 머신을 교체해야 합니다. 마스터 노드 1.101과 슬레이브 노드 1.102를 새로운 머신 1.103 및 1.104로 동시에 마이그레이션할 계획이며, 1.103은 마스터 노드로, 1.104는 슬레이브 노드로 작동합니다. 위치 B의 2.101과 2.102는 변경되지 않은 상태로 유지되지만 마이그레이션이 완료된 후 1.103과 2.101은 서로의 이중 마스터가 됩니다. 아키텍처 다이어그램은 그림 5에 나와 있습니다. 듀얼 마스터 구조이기 때문에 양쪽이 동시에 쓰기 때문에 마스터 노드를 교체하려면 한 노드가 서비스를 중단해야 합니다.
- 그림 5 이중 1차 구조 기계실 간 마이그레이션 아키텍처 다이어그램
구체적인 방법은 다음과 같습니다.
1.103 및 1.104 새 인스턴스는 마스터-슬레이브 관계를 설정합니다. 이때 마스터 노드와 슬레이브 노드는 무부하 상태입니다.
1.102 MySQL 상태를 확인합니다(주로 다음을 참조하세요. PROCESS LIST), MASTER STATUS가 더 이상 변경되지 않는지 주의 깊게 관찰하세요. 머신 트래픽을 관찰하여 올바른지 확인한 후 1.102 슬레이브 노드의 서비스를 중지합니다.
1.103 새 MySQL 인스턴스를 생성한 후 MySQL 서비스를 중지합니다. 전체 데이터 디렉터리 mv를 다른 위치에 백업합니다. ;
- rsync를 사용하여 1.102의 전체 mysql 데이터 디렉터리를 1.103으로 복사합니다.
- 복사하는 동안 , 1.103이 풀 수 있도록 1.101을 승인합니다. binlog(REPLICATION SLAVE, REPLICATION CLIENT)의 권한을 얻습니다.
- 복사가 완료된 후 1.103 구성 파일에서 server_id를 수정합니다. 주의하세요. 1.102와 일치하지 않도록
1.103 MySQL 인스턴스를 입력하고 SHOW SLAVE STATUS를 사용하여 슬레이브 상태를 확인하면 Seconds_Behind_Master가 감소하는 것을 볼 수 있습니다.
Seconds_Behind_Master가 0이 된 후, 이는 동기화가 완료되었음을 의미합니다. 이때 pt-table-checksum을 사용하여 1.101과 1.103의 데이터가 일치하는지 확인할 수 있지만 시간이 많이 걸리고 마스터 노드에 영향을 미칩니다.
1.104를 1.103의 슬레이브 라이브러리로 만드는 것과 같은 방법을 사용합니다.
데이터 일관성 검증, 비즈니스 마이그레이션 후 접속 오류 방지를 위해 계정 권한도 검증해야 합니다.
이때 우리가 해야 할 일은 1.103을 슬레이브 라이브러리로 전환하는 것입니다. 2.101의 구체적인 방법은 시나리오 4를 참조하세요.
1.103의 홀수 및 짝수 구성은
- 위 단계를 완료한 후 R&D와 협력하여 1.101 읽기 및 쓰기 작업을 1.103으로, 1.102의 읽기 작업을 1.104로 삭감할 수 있습니다. 비즈니스 상태를 관찰하세요.
- 비즈니스에 문제가 없으면 마이그레이션이 성공한 것입니다.
3.6 시나리오 6 다중 인스턴스 컴퓨터실 간 마이그레이션
다음으로 다중 인스턴스 컴퓨터실 간 마이그레이션 증명을 살펴보겠습니다. . 각 머신의 인스턴스 관계는 그림 6을 참조할 수 있습니다. 이 마이그레이션의 목적은 데이터 복구를 수행하는 것입니다. 2.117에 인스턴스 7938, 7939를 생성하여 이전 인스턴스를 비정상적인 데이터로 대체합니다. 비즈니스상의 이유로 일부 라이브러리는 A 위치에만 작성되고 일부 라이브러리는 B 위치에만 작성되므로 동기 필터링되는 상황이 있습니다.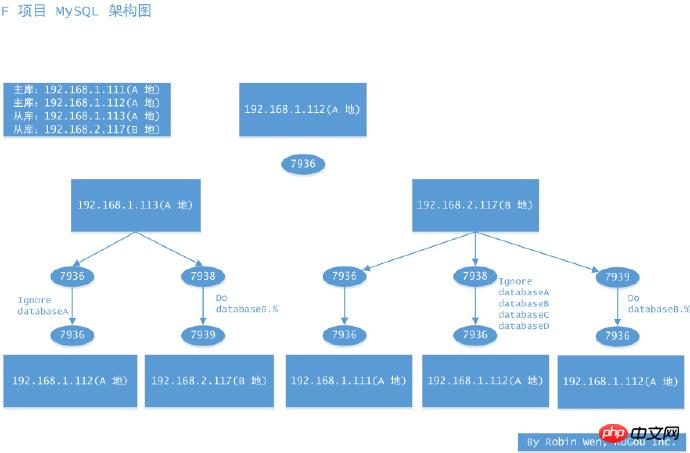 그림 6 멀티 인스턴스 머신룸 간 마이그레이션 아키텍처 다이어그램
그림 6 멀티 인스턴스 머신룸 간 마이그레이션 아키텍처 다이어그램
- 1.113 7936개 인스턴스에는 innobackupex를 사용하세요. 데이터 백업을 수행하려면 데이터베이스를 지정하고 슬레이브 정보 매개변수를 추가해야 합니다.
- 백업이 완료된 후 압축 파일을 다음 위치에 복사하세요. 2.117;
- 2.117 구성 파일과 관련된 데이터 디렉터리 및 관련 디렉터리를 생성합니다. 2.117 로그를 복원하려면 innobackupex를 사용하세요.
2.117 innobackupex를 사용하여 데이터 복사
2.117 구성 파일을 수정하고 다음 매개변수에 주의하세요. , read_only = 1, server_id;
2.117 데이터 디렉토리 권한을
1.112 인증으로 변경하여 2.117이 binlog를 가져올 수 있는 권한을 갖도록 합니다. 복제 슬레이브, 복제 클라이언트)
2.117 MASTE를 1.112로 변경하고 로그 파일 및 로그 POS는 xtrabackup_slave_info를 참조하세요.
2.117 START SLAVE, 슬레이브 상태를 확인하세요.
2.117에서 7939를 빌드하세요. 방법은 비슷하지만 구성 파일에 Replicate-wild-do-table을 지정해야 합니다. - 비즈니스 마이그레이션 후 액세스 오류를 방지하기 위해 개발팀과 협력하여 데이터 일관성을 확인하고 계정 권한을 확인합니다.
- 위 단계를 완료한 후 R&D와 협력하여 해당 마이그레이션을 마이그레이션할 수 있습니다. 2.117의 7938 인스턴스와 7939 인스턴스에 대한 비즈니스입니다. 비즈니스 상태를 관찰하세요.
- 비즈니스에 문제가 없으면 마이그레이션이 성공한 것입니다.
- 네 가지 노트
다양한 시나리오에 대한 마이그레이션 솔루션을 소개한 후에는 다음 사항에 주의해야 합니다.
데이터베이스 마이그레이션,
이벤트와 관련된 경우 마스터 노드에서 event_scheduler 매개변수를 켜야 합니다.
마이그레이션 시나리오가 무엇이든 항상 해야 합니다. 디스크 공간 및 네트워크 지터와 같은 서버 상태에 주의하십시오. 또한, 비즈니스에 대한 지속적인 모니터링도 필수적입니다.
CHANGE MASTER TO의 LOG FILE 및 LOG POS. 잘못된 것을 지정하면 결과는 다음과 같습니다. 데이터가 일치하지 않거나 마스터-슬레이브 관계가 설정되지 않습니다. - $HOME 디렉터리, 데이터 디렉터리에서 수행해야 합니다.
- 마이그레이션 작업을 수행할 수 있습니다. 스크립트를 사용하여 자동화할 수 있지만 모든 스크립트를 테스트해야 합니다. ;
- 명령을 실행하기 전에 두 번 생각하고 각 명령의 매개변수의 의미를 이해하세요. ;
- 다중 인스턴스 환경에서. , mysqladmin을 사용하여 MySQL을 닫으십시오.
- read_only = 1을 삭제하면 많은 문제를 피할 수 있습니다. 🎜>
- 각 머신의 server_id는 일관되어야 합니다. 그렇지 않으면 동기화 예외가 발생합니다.
- replicate-ignore-db 및 Replicate-wild-do-table을 올바르게 구성하세요. >
위의 일부 시나리오에서는 이전 인스턴스에서 이 매개변수가 0이었기 때문에 ibdata1이 너무 커서 백업 및 전송에 많은 시간이 걸렸습니다.
gzip을 사용하여 데이터를 압축하는 경우 압축이 완료된 후 gzip이 소스 파일을 삭제합니다.
모든 작업은 슬레이브 노드 또는 대기 노드에서 수행되어야 합니다. 작업이 기본 노드에서 작동되는 경우 기본 노드가 다운될 가능성이 높습니다.
xtrabackup 백업은 InnoDB 테이블을 잠그지 않습니다. , 그러나 MyISAM 테이블을 잠글 것입니다. 따라서 운영하기 전에 현재 데이터베이스 테이블이 MyISAM 스토리지 엔진을 사용하고 있는지 확인해야 합니다. 그렇다면 별도로 처리하거나 테이블의 엔진을 변경하십시오.
5가지 팁
실제 MySQL 마이그레이션에서는 다음 기술을 사용할 수 있습니다.
relay_master_log_file로의 모든 마이그레이션 로그 파일 (동기화되는 마스터의 binlog 로그 이름)이 우선하며 LOG POS는 exec_master_log_pos(동기화되는 현재 binlog 로그의 POS 지점)의 적용을 받습니다. 데이터를 복사하려면 rsync를 사용하세요. nohup을 사용하는 것은 정말 멋진 조합입니다.
-
innobackupex를 사용하여 데이터를 백업하는 동안 gzip을 사용하여 압축할 수 있습니다.
innobackupex를 사용하여 데이터를 백업하는 경우 데이터의 경우 슬레이브 데이터베이스를 용이하게 하기 위해 –slave-info 매개변수를 추가할 수 있습니다.
innobackupex를 사용하여 데이터를 백업하는 경우 –throttle 매개변수를 추가하여 IO를 제한하고 비즈니스에 미치는 영향을 줄일 수 있습니다. –parallel=n 매개변수를 추가하여 백업 속도를 높일 수도 있지만 tar 스트림 압축을 사용하는 경우 –parallel 매개변수는 데이터 백업에 유효하지 않습니다.
할 일 목록을 만들고, 프로세스를 그려보고, 실행해야 할 명령을 미리 준비할 수 있습니다.
폴더를 로컬로 빠르게 복사하는 좋은 방법은 다음과 같습니다. rsync와 다음 매개변수를 사용하려면: -avhW –no-compress –progress;
-
다른 파티션 간에 데이터를 빠르게 복사하려면 dd를 사용할 수 있습니다. 또는 보다 안정적인 방법을 사용하여 하드 디스크에 백업한 다음 서버에 저장합니다. 다른 곳에는 더 좋은 것이 있는데 바로
빠른 배송 하드 드라이브입니다. - 이 기사는 마이그레이션이 필요한 이유부터 시작하여 마이그레이션 계획에 대해 설명하고 다양한 시나리오에서 실제 마이그레이션을 설명하며 마지막으로 메모. 문제와 실제 기술. 정리하자면 다음과 같습니다.
첫째, 마이그레이션의 목적은 비즈니스를 원활하고 지속적으로 운영하는 것입니다.
둘째, 마이그레이션의 핵심은 마스터-슬레이브 동기화를 어떻게 지속하느냐입니다. 우리는 서로 다른 서버에서 이를 수행해야 합니다.셋째, 비즈니스 전환은 서로 다른 머신에서의 읽기 및 쓰기 분리 순서와 마스터-슬레이브 관계 요구 사항을 고려해야 합니다. 고려해야 할 사항은 기계실 간 호출이 비즈니스에 미치는 영향을 고려해야 한다는 것입니다.
독자는 마이그레이션 과정에서 이 문서에 제공된 아이디어를 참조할 수 있습니다. 그러나 각 작업이 올바르게 실행되도록 하려면 진행하기 전에 신중하게 생각해야 합니다.
여담이지만, "자신이 능력이 있다는 것을 증명하는 가장 중요한 것은 모든 것을 통제하는 것입니다."
위 내용은 다양한 상황에서의 MySQL 마이그레이션 솔루션(권장)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!