
Pandas 라이브러리에 도입된 DataFrame의 기본 작업

- PHPz원래의
- 2017-04-04 13:38:054870검색
빈 문자를 삭제목록하는 방법은 무엇입니까?
가장 간단한 방법: new_list = [ x for x in li if x != '' ]
오늘은 5월 1일이다.
이 부분에서는 앞선 두 가지 데이터 구조를 기반으로 팬더의 기본 연산을 주로 연구합니다.
设有DataFrame结果的数据a如下所示: a b c one 4 1 1 two 6 2 0 three 6 1 6
1. 데이터 보기(객체 를 보는 방법은 시리즈에도 적용 가능)
1. 또는 DataFrame 라인 xx
a=DataFrame(data);
a.head(6) 뒤는 head에 매개변수가 없는 경우 데이터의 처음 6개 행을 표시한다는 의미입니다. (), 모든 데이터가 표시됩니다.
a.tail(6)은 데이터의 마지막 6개 행을 표시한다는 의미입니다. tail()에 매개변수가 없으면 모든 데이터가 표시됩니다.
2. DataFrame의 인덱스, 열 및 값을 봅니다.
a.index; a.values; 🎜>3.describe()
빠른 데이터 통계 요약a.describe()는 데이터의 각 열(개수, 평균, 표준점, 각 분위수 등)에 대한 통계를 수행합니다. .
4. 데이터 전치
a.T
5. 축 정렬
a. _index(axis=1,ascend
ing=False);여기서 axis=1은 의 모든 열 정렬을 의미하며 다음 숫자도 이에 따라 이동합니다. 다음 ascending=False는 내림차순으로 정렬한다는 의미이며, 매개변수가 누락된 경우 기본값은 오름차순입니다.
6. DataFrame의 값을 정렬합니다.
즉, a의 x 열을 작은 것부터 정렬합니다. 크기가 큰 . x 열만 해당되며 위의 축별 정렬은 모든 열에 대해 작동합니다. 2. 객체 선택
이 메서드는 한 번에 하나의 열만 반환할 수 있습니다. a.x는 a['x']와 같은 의미입니다.
행 데이터를 가져오고 []를 분할하여 을 선택합니다. 예를 들어 a[0:3]은 처음 세 행의 데이터를 반환합니다.
2.loc는 태그를 통해 데이터를 선택합니다.
동작 'one'이 있는 행이 선택되었음을 나타냅니다. ;
a.loc[:,['a','b'] ]는 열이 a와 b인 모든 행과 열을 선택하는 것을 의미합니다. a.loc[['one' ,'two'],['a','b']]는 'one'과 'two'라는 두 행과 a와 b인 열을 선택하는 것을 의미합니다.
a.loc['one; ' ,'a'] 는 a.loc[['one'],['a']] 와 동일한 효과를 가지지만 전자는 해당 값만 표시하고 후자는 해당 행 및 열 레이블을 표시합니다.
3.iloc은 위치별로 직접 데이터를 선택합니다레이블별로 선택하는 것과 비슷합니다a.iloc[1:2,1:2]가 표시됩니다. 첫 번째 행과 첫 번째 열에서; (슬라이스 이후의 값을 얻을 수 없음) a.iloc[1:2]는 후속 열에 값이 없을 때
행을 의미합니다. position은 기본적으로 1로 선택되어 있습니다. data
;
a.iloc[[0,2],[1,2]]는 행 위치와 열 위치에 해당하는 데이터를 자유롭게 선택할 수 있다는 의미입니다. .
4. 조건을 사용하여 선택 별도의 열을 사용하여 데이터 선택 a[a.c>0]은 c 열 선택을 의미합니다. 0보다 큼
데이터 선택 위치 사용a[a>0] 테이블에서 0보다 큰 모든 데이터를 직접 선택
행 선택
copy()a1[a1['one'].isin(['2','3']) 열에 특정 값이 포함되어 있음 ] 표에는 조건을 충족하는 모든 행이 표시됩니다. 첫 번째 열의 값에는 '2', '3'이 포함됩니다.
3. 설정값(할당)
위의 선택 연산을 바탕으로 할당 연산을 직접 할당할 수 있습니다.
a.iloc[:,[1, 3] ]=9는 a열과 c열의 모든 행에 있는 값을 9로 설정한다는 의미이기도 합니다
동시에 조건을 사용하여 값을 직접 할당할 수도 있습니다
a[ a>0]=-a 에 a를 설정한다는 의미 0보다 큰 모든 숫자는 음수값으로 변환됩니다.
pandas에서는 np.nan을 사용하여 교체합니다. 누락된 값은 기본적으로 계산에 포함되지 않습니다.
의 인덱스 를 a.reindex(index=['one','five'],columns=list(a.columns)+['d']) 即用index=[]表示对index进行操作,columns表对列进行操作。 2.对缺失值进行填充 3.去掉包含缺失值的行 1.contact 例:a1=[b['a'],b['c']] 2.Append 将一行或多行数据连接到一个DataFrame上 3.merge类似于SQL中的join 用pd.date_range函数生成连续指定天数的的日期 此外用a.groupby('gender').size()可以对各个gender下的数目进行计数。 所以可以看到groupby的作用相当于: 如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下: 所以可以看出重新编码后的编码会自动增加到dataframe最后作为一列。 描述性统计: 2.统计某一列x中各个值出现的次数:a['x'].value_counts(); 3.对数据应用函数 4.字符串相关操作 在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。 此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下: 1.png 2.PNG 3.png 写入和读取excel文件 还有将数据写入表格中时,excel会自动给你在表格最前面增加一个字段,对数据行进行编号。
변경/추가/삭제하는 데 사용됩니다. 원본 데이터의 사본이 반환됩니다. a.reindex(index=list(a.index)+['five'],columns=list(a.columns)+['d'])
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
a.dropna(how='any')
表示去掉所有包含缺失值的行五、合并
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
result=pd.concat(a1,axis=1,keys=['1','2'])
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。六、分组(groupby)
pd.date_range('20000101',periods=10)def shuju():
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=DataFrame(data)
print(a)
date gender height weight
0 2000-01-01 0 47 165
1 2000-01-02 0 46 179
2 2000-01-03 1 48 172
3 2000-01-04 0 45 173
4 2000-01-05 1 47 151
5 2000-01-06 0 45 172
6 2000-01-07 0 48 167
7 2000-01-08 0 45 157
8 2000-01-09 1 42 157
9 2000-01-10 1 42 164
用a.groupby('gender').sum()得到的结果为: #注意在python中groupby(''xx)后要加sum(),不然显示
不了数据对象。
gender height weight
0 256 989
1 170 643
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。七、Categorical按某一列重新编码分类
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female
八、相关操作
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。九、时间序列
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定起始日期。
十、画图(plot)
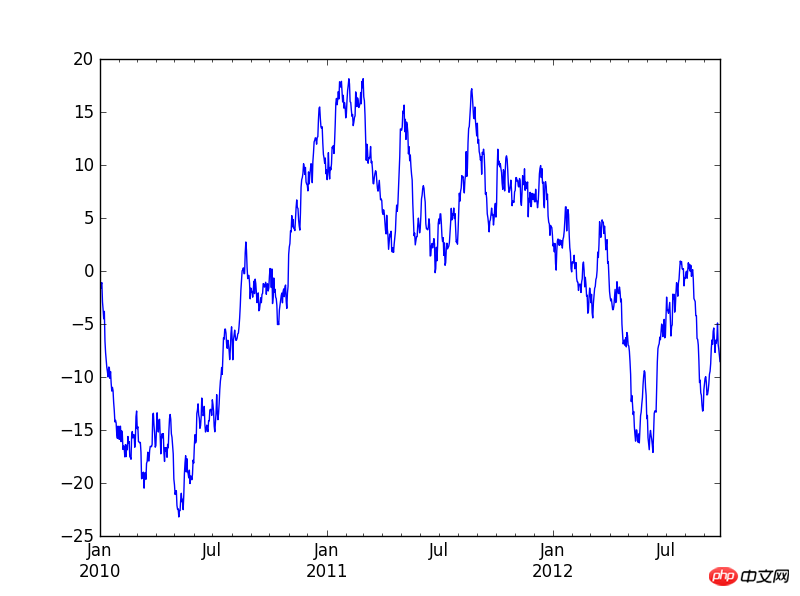
在pycharm中首先要:import matplotlib.pyplot as plt
a=Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b=a.cumsum()
b.plot()
plt.show() #最后一定要加这个plt.show(),不然不会显示出图来。
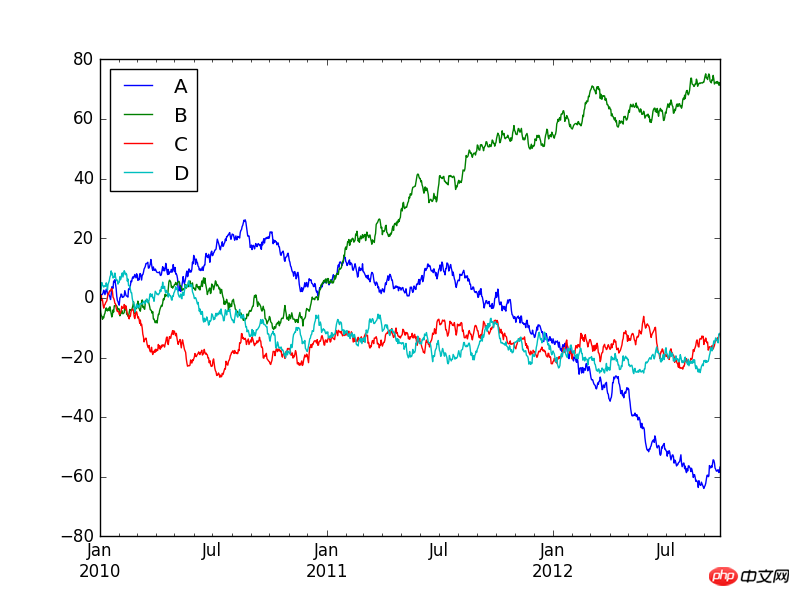
也可以使用下面的代码来生成多条时间序列图:a=DataFrame(np.random.randn(1000,4),index=pd.date_range('20100101',periods=1000),columns=list('ABCD'))
b=a.cumsum()
b.plot()
plt.show()
十一、导入和导出文件
虽然写入excel表时有两种写入xls和csv,但建议少使用csv,不然在表中调整数据格式时,保存时一直询问你是否保存新格式,很麻烦。而在读取数据时,如果指定了哪一张sheet,则在pycharm又会出现格式不对齐。a.to_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls',sheet_name='Sheet1')
a=pd.read_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls','Sheet1',na_values=['NA'])
注意sheet_name后面的Sheet1中的首字母大写;读取数据时,可以指定读取哪一张表中的数据,而
且对缺失值补上NA。
最后再附上写入和读取csv格式的代码:
a.to_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',sheet_name='Sheet1')
a=pd.read_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',na_values=['NA'])
위 내용은 Pandas 라이브러리에 도입된 DataFrame의 기본 작업의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!