


xml(Extensible Markup Language)은 일종의 w3c 표준처럼 보일 수 있습니다. 지금은 실제 영향이 없으며 나중에 유용하게 사용된다면 오래 걸릴 것입니다. 후에 . 그러나 실제로는 이미 사용되고 있습니다. 따라서 즐겨 사용하는 HTML편집기에 xml이 추가될 때까지 기다리지 말고 사용을 시작하세요. . 이제 다양한 내부 문제와 B2B 시스템 문제를 해결합니다.
sparks.com에서는 특히 java객체에서 html 데이터 표시까지 다양한 시스템을 표준화하기 위해 XML을 사용합니다. , 우리는 매우 기본적인 xml 구조로 표준화되어 있는 한 데이터를 공유하고 조작하는 것이 더 쉽다는 것을 발견했습니다. xml을 사용하는 효과적인 방법은 많습니다.
xml을 사용하기 전에 사용하려는 정보와 다른 xml 데이터 형식을 만듭니다. >
동적 xml 생성데이터베이스에서 html을 생성하는 것은 새로운 것이 아니지만 여기서는 xml을 생성하는 방법을 소개합니다. 특정 생성 단계 xsl을 템플릿 언어로 사용xsl(Extensible Stylesheet Language)은 xml 데이터 표시 형식을 정의하는 좋은 방법입니다. 여러정적
템플릿 을 사용하여 html<.>xml과 xsl을 더하면 html이 됩니다. 이는 잘못된 것처럼 들릴 수도 있지만 실제로는 xml과 xsl의 힘은 유연성에서 나옵니다. 그러나 안타깝게도 때로는 너무 유연해서 어떤 XML 프로젝트에서든 문제를 해결하는 방법이 궁금할 수 있습니다. 첫 번째 단계는 표준 데이터를 만드는 것입니다. 이렇게 하려면 다음과 같은 결정을 내려야 합니다. 어떤 데이터를 포함해야 합니까?
dtd(파일 형식 정의)를 사용할지 여부
사용할지 여부를 결정합니다. DOM(Document Object Model) 또는 SAX(Simplified API for XML)를 사용하여
데이터를 확인합니다.
표준 XML 형식이 없기 때문에 개발자는 자신만의 형식을 자유롭게 개발할 수 있습니다. 그러나 형식이 하나의 응용 프로그램에서만 인식되는 경우 해당 형식을 사용하기 위해 프로그램을 실행할 수만 있습니다. XML 형식이 수정되면 다른 프로그램도 이해하는 것이 더 유용할 것입니다. 이를 사용하는 시스템도 수정해야 할 수 있으므로 가능한 한 완전한 형식을 만들어야 합니다. 대부분의 시스템은 인식하지 못하는 태그를 무시하므로 XML 형식을 변경하는 가장 안전한 방법은 태그를 수정하는 대신 태그를 추가하는 것입니다. >
xml 데이터 형식의 예를 보려면 여기를 클릭하세요sparks.com에서는 다양한 제품 프레젠테이션에 필요한 모든 제품 데이터를 살펴보지만 모든 페이지에서는 모든 데이터를 사용하지만, 모든 데이터에 적용되는 매우 완전한 xml 데이터 형식입니다. 예를 들어, 제품 세부 정보 페이지에는 제품 검색 페이지보다 더 많은 데이터가 표시됩니다. 그러나 각 페이지의 xsl 템플릿은 필요한 필드만 사용하기 때문에 두 경우 모두 동일한 데이터 형식을 사용합니다. dtd 사용 여부sparks.com에서는 올바른 xml 대신 잘 구성된 xml을 사용합니다. 전자에는 dtd가 필요하지 않기 때문입니다. DTD는 사용자가 페이지를 클릭하고 보는 사이에 처리 계층을 추가합니다. 우리는 이 레이어에 너무 많은 처리가 필요하다는 것을 발견했습니다. 물론 XML 형식으로 다른 회사와 통신할 때 DTD를 사용하는 것은 여전히 좋은 일입니다. dtd는 보내고 받을 때 데이터 구조가 올바른지 확인할 수 있기 때문입니다. 파싱 엔진 선택이제 여러 가지 파싱 엔진을 사용할 수 있습니다. 어떤 것을 선택하느냐는 거의 전적으로 애플리케이션 요구 사항에 따라 달라집니다. DTD를 사용하기로 결정한 경우 구문 분석 엔진은 XML이 DTD에 의해 확인되도록 할 수 있어야 합니다. 유효성 검사를 별도의 프로세스에 넣을 수 있지만 이는 성능에 영향을 미칩니다. Sax와 dom은 두 가지 기본 분석 모델입니다. SAX는이벤트
를 기반으로 하기 때문에 xml을 파싱하면 해당 이벤트가 엔진으로 전달됩니다. 다음으로 이벤트는 출력 파일과 동기화됩니다. DOM 구문 분석 엔진은 동적 XML 데이터 및 XSL 스타일 시트에 대한 계층적 트리 구조를 설정합니다. DOM 트리에 무작위로 액세스하면 마치 XSL 스타일시트에 의해 결정된 것처럼 XML 데이터가 제공될 수 있습니다. SAX 모델에 대한 논쟁은 주로 DOM 구조의 과도한 메모리 감소와 XSL 스타일 시트의 구문 분석 시간 가속화에 중점을 두고 있습니다. 그러나 sax를 사용하는 많은 시스템이 해당 기능을 완전히 활용하지 못하는 것으로 나타났습니다. 이러한 시스템은 이를 사용하여 DOM 구조를 구축하고 DOM 구조를 통해 이벤트를 보냅니다. 이 접근 방식을 사용하면 XML 처리 전에 스타일시트에서 DOM을 구축해야 하므로 성능이 저하됩니다. 2. 동적 xml 생성xml 형식이 설정되면 이를 데이터베이스에서 동적으로 이식하는 방법이 필요합니다.XML 문서 생성은 문자열을 처리할 수 있는 시스템만 필요하므로 상대적으로 간단합니다. Java서블릿, 엔터프라이즈 Javabean 서버, jdbc 및 rdbms(관계형 데이터베이스 관리 시스템)를 사용하여 시스템을 구축했습니다.
서블릿은 xml 문서 생성 작업을 Enterprise Javabean(ejb)으로 오프로드하여 제품 정보 요청을 처리합니다.
ejb는 jdbc를 사용하여 데이터베이스에서 필요한 제품 세부정보를 쿼리합니다.
ejb는 xml 파일을 생성하여 서블릿에 전달합니다.
서블릿은 구문 분석 엔진을 호출하여 xml 파일과 정적 xsl 스타일 시트에서 html 출력을 생성합니다. (XSL 적용에 대한 자세한 내용은 종류 사용을 참조하세요.
xml 생성 프로세스를 시작하는 코드는 ejb 메소드에 배치됩니다. 이 인스턴스는 생성된 xml 문자열을 저장하기 위해 문자열 버퍼를 즉시 생성합니다.
stringbuffer xml = new stringbuffer();
xml.append(xmlutils.begindocument("/browse_find/browse.xsl", "browse", request));
xml.append(product.toxml());
xml.append(xmlutils.enddocument("browse");
out.print(xml.tostring());다음 세 개의 xml.append() 변수 자체는 다른 메서드에 대한 호출입니다.
파일 헤더 생성
첫 번째 추가 메서드는 xmlutils 클래스를 호출하여 xml 파일 헤더를 생성합니다. Java 서블릿의 코드는 다음과 같습니다.
public static string begindocument(string stylesheet, string page)
{
stringbuffer xml = new stringbuffer();
xml.append( "<?xml version=\"1.0\"?>\n")
.append( "<?xml-stylesheet href=\"")
.append(stylesheet).append( "\"")
.append( " type =\"text/xsl\"?>\n");
xml.append( "<").append(page).append(">\n");
return xml.tostring();
} 이 코드는 xml 파일 헤더를 생성합니다. 태그는 이 파일을 버전 1.0을 지원하는 xml 파일로 정의합니다. 두 번째 코드 줄은 데이터를 표시할 올바른 스타일 시트의 위치를 가리킵니다. 마지막으로 포함된 것은 항목 수준 태그입니다(이 예에서는
<?xml version="1.0"?> <?xml-stylesheet href="/browse_find/browse.xsl" type="text/xsl"?> <browse>
제품 정보를 입력하세요
파일 헤더를 완성한 후 제어 메소드는 java 객체를 호출하여 xml을 생성합니다. 이 예에서는 제품 개체가 호출됩니다. 제품 객체는 두 가지 방법을 사용하여 XML 표현을 생성합니다. 첫 번째 메소드 toxml()은
public string toxml()
{
stringbuffer xml = new stringbuffer( "<product>\n");
xml.append(internalxml());
xml.append( "</product>\n");
return xml.tostring();
}
public string internalxml()
{
stringbuffer xml = new
stringbuffer( "\t")
.append(producttype).append( "\n");
xml.append( "\t").append(idvalue.trim())
.append( "\n");
xml.append( "\t").append(idname.trim())
.append( "\n");
xml.append( "\t").append(page.trim())
.append( "\n");
厖?
xml.append( "\t").append(amount).append("\n");
xml.append( "\t").append(vendor).append("\n");
xml.append( "\t\n");
xml.append( "\t").append(pubdesc).append("\n");
xml.append( "\t").append(vendesc).append("\n";
厖?
return xml.tostring();
}파일을 닫습니다
마지막으로 xmlutils.enddocument() 메서드가 호출됩니다. 이 호출은 xml 태그(이 경우)를 닫고 최종적으로 구조화된 xml 파일을 완성합니다. 제어 메소드의 전체 문자열 버퍼도 문자열로 변환되어 원래 http 요청을 처리한 서블릿으로 반환됩니다.
3. xsl을 템플릿 언어로 사용
html 출력을 얻기 위해 생성된 xml 파일을 xml 데이터 표시 방법을 제어하는 xsl 템플릿과 결합합니다. 우리의 xsl 템플릿은 세심하게 구성된 xsl과
html 태그로 구성되어 있습니다.
템플릿 작성 시작xsl 템플릿의 시작 부분은 아래 코드와 유사합니다. 코드의 첫 번째 줄은 필수이며 이 파일을 xsl 스타일 시트로 정의합니다. xmlns:xsl=
속성 은 이 파일에서 사용하는 xml 네임스페이스를 참조하고, version= 속성은 네임스페이스의 버전 번호를 정의합니다. 파일 끝에서 태그를 닫습니다. 으로 시작하는 두 번째 코드 줄은 xsl 템플릿의 모드를 결정합니다. match 속성은 필수이며 여기서는 xml 태그
다음으로 잘 정리된 html을 살펴보겠습니다. XML 구문 분석 엔진에 의해 처리되므로 잘 구성된 XML의 모든 규칙을 준수해야 합니다. 기본적으로 이는 모든 여는 태그에 해당하는 닫는 태그가 있어야 함을 의미합니다. 예를 들어, 일반적으로 닫히지 않는
태그는
로 닫아야 합니다.<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/xsl/transform" version="1.0"> <xsl:template match="basketpage"> <html> <head> <title>shopping bag / adjust quantity</title> </head> <body bgcolor="#cccc99" bgproperties="fixed" link="#990000" vlink="#990000"> <br> <br> </xsl:template> </xsl:stylesheet>템플릿 본문에는 데이터 표시 논리를 제공하는 데 사용되는 많은 xsl 태그가 있습니다. 일반적으로 사용되는 두 가지 태그는 아래에 설명되어 있습니다.
choose
if
-then-else 구조의 시작 부분과 유사합니다. 🎜>. XSL에서 choose 태그는 코드가 입력되는 부분에서 할당이 작업을 트리거한다는 것을 나타냅니다. 속성이 할당된在这个例子里,when标签会为quantity标签检查xml。如果quantity标签里含有值为真的error属性,quantity标签将会显示列在下面的表格单元。如果属性的值不为真,xsl将会显示otherwise标签间的内容。在下面的实例里,如果error属性不真,则什么都不会被显示。
<xsl:choose> <xsl:when test="quantity[@error='true']"> <td bgcolor="#ffffff"><img src="/static/imghwm/default1.png" data-src="http://img.sparks.com/images/i-catalog/sparks_images/sparks_ui/clearpixel.gif" class="lazy" style="max-width:90%" style="max-width:90%" / alt="XML 및 XSL을 사용하여 동적 페이지를 생성하는 코드에 대한 자세한 설명" ></td> <td valign="top" bgcolor="#ffffff" colspan="2"> <font face="verdana, arial" size="1" color="#cc3300"><b>*not enough in stock. your quantity was adjusted accordingly.</b></font></td> </xsl:when> <xsl:otherwise> </xsl:otherwise> </xsl:choose>
for-each
<xsl:for-each select="package"> <xsl:apply-templates select="product"/> </xsl:for-each>
for-each 循环在程序遇到标签时开始。这个循环将在程序遇到标签时结束。一旦这个循环运行,每次标签出现时都会应用这个模板。
四、生成html
将来的某一时刻,浏览器将会集成xml解析引擎。到那时,你可以直接向浏览器发送xml和xsl文件,而浏览器则根据样式表中列出的规则显示xml数据。不过,在此之前开发者们将不得不在他们服务器端的系统里创建解析功能。
在sparks.com,我们已经在java servlet里集成了一个xml解析器。这个解析器使用一种称为xslt (xsl transformation)的机制,按xsl标签的说明向xsl模板中添加xml数据。
当我们的java servlet处理http请求时,servlet检索动态生成的xml,然后xml被传给解析引擎。根据xml文件中的指令,解析引擎查找适当的xsl样式表。解析器通过dom结构创建html文件,然后这个文件再传送给发出http请求的用户。
如果你选择使用sax模型,解析器会通读xml源程序,为每个xml标签创建一个事件。事件与xml数据对应,并最终按xsl标签向样式表中插入数据。
위 내용은 XML 및 XSL을 사용하여 동적 페이지를 생성하는 코드에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
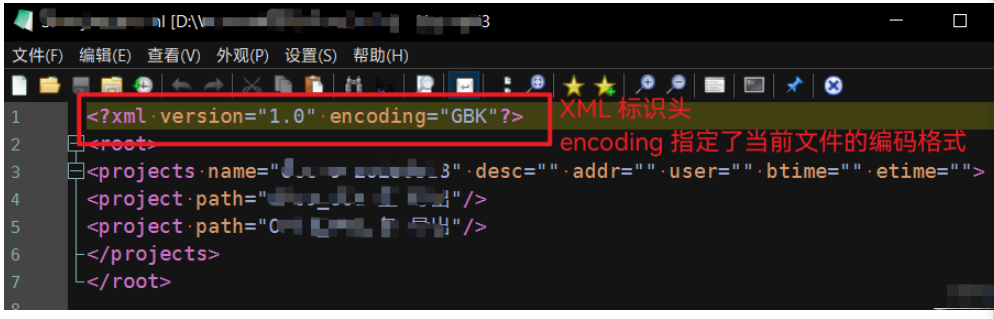 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

Dreamweaver Mac版
시각적 웹 개발 도구

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

