
Java를 사용하여 Word 파일을 html 파일로 변환하는 샘플 코드에 대한 자세한 설명

- 黄舟원래의
- 2017-03-24 10:27:212228검색
이 글에서는 word 파일을 Java에서 html 파일로 변환하는 방법을 주로 소개합니다. 관심 있는 친구들이 참고할 수 있을 정도입니다.
최근 프로젝트 중에도요. 개발 과정에서 사용자는 컴퓨터에 Office가 설치되어 있지 않을 때 브라우저에서 워드 파일을 열 것을 제안했습니다. 최종 논리는 사용자가 보려는 파일을 선택하고 js 페이지에서 파일을 열지 여부를 결정하는 것입니다. 파일은 워드입니다. 백엔드는 다운로드를 실행하는 대신 단어 파일 접미사를 기반으로 해당 변환 방법에 액세스합니다. 파일이 이미 있고 해당 html 파일이 있으면 html 파일 주소를 직접 반환하고, 파일이 없으면 해당 html 파일을 먼저 생성한 후 주소를 반환합니다. Node.js는 open()을 통해 새 탭을 직접 열어 단어 파일의 내용을 표시합니다. 저는 초보자입니다. 코드에 오류가 있거나 더 나은 구현이 있으면 수정해 주세요!
관련 jar 패키지

코드
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.converter.PicturesManager;
import org.apache.poi.hwpf.converter.WordToHtmlConverter;
import org.apache.poi.hwpf.usermodel.PictureType;
import org.apache.poi.xwpf.converter.core.BasicURIResolver;
import org.apache.poi.xwpf.converter.core.FileImageExtractor;
import org.apache.poi.xwpf.converter.core.FileURIResolver;
import org.apache.poi.xwpf.converter.xhtml.XHTMLConverter;
import org.apache.poi.xwpf.converter.xhtml.XHTMLOptions;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.w3c.dom.Document;
/**
* word 转换成html 2017-2-27
*/
public class WordToHtml {
/**
* 将word2003转换为html文件 2017-2-27
* @param wordPath word文件路径
* @param wordName word文件名称无后缀
* @param suffix word文件后缀
* @throws IOException
* @throws TransformerException
* @throws ParserConfigurationException
*/
public String Word2003ToHtml(String wordPath,String wordName,String suffix) throws IOException, TransformerException, ParserConfigurationException {
String htmlPath = wordPath + File.separator + wordName + "_show" + File.separator;
String htmlName = wordName + ".html";
final String imagePath = htmlPath + "image" + File.separator;
//判断html文件是否存在
File htmlFile = new File(htmlPath + htmlName);
if(htmlFile.exists()){
return htmlFile.getAbsolutePath();
}
//原word文档
final String file = wordPath + File.separator + wordName + suffix;
InputStream input = new FileInputStream(new File(file));
HWPFDocument wordDocument = new HWPFDocument(input);
WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter(DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument());
//设置图片存放的位置
wordToHtmlConverter.setPicturesManager(new PicturesManager() {
public String savePicture(byte[] content, PictureType pictureType, String suggestedName, float widthInches, float heightInches) {
File imgPath = new File(imagePath);
if(!imgPath.exists()){//图片目录不存在则创建
imgPath.mkdirs();
}
File file = new File(imagePath + suggestedName);
try {
OutputStream os = new FileOutputStream(file);
os.write(content);
os.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//图片在html文件上的路径 相对路径
return "image/" + suggestedName;
}
});
//解析word文档
wordToHtmlConverter.processDocument(wordDocument);
Document htmlDocument = wordToHtmlConverter.getDocument();
//生成html文件上级文件夹
File folder = new File(htmlPath);
if(!folder.exists()){
folder.mkdirs();
}
//生成html文件地址
OutputStream outStream = new FileOutputStream(htmlFile);
DOMSource domSource = new DOMSource(htmlDocument);
StreamResult streamResult = new StreamResult(outStream);
TransformerFactory factory = TransformerFactory.newInstance();
Transformer serializer = factory.newTransformer();
serializer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
serializer.setOutputProperty(OutputKeys.INDENT, "yes");
serializer.setOutputProperty(OutputKeys.METHOD, "html");
serializer.transform(domSource, streamResult);
outStream.close();
return htmlFile.getAbsolutePath();
}
/**
* 2007版本word转换成html 2017-2-27
* @param wordPath word文件路径
* @param wordName word文件名称无后缀
* @param suffix word文件后缀
* @return
* @throws IOException
*/
public String Word2007ToHtml(String wordPath,String wordName,String suffix) throws IOException {
String htmlPath = wordPath + File.separator + wordName + "_show" + File.separator;
String htmlName = wordName + ".html";
String imagePath = htmlPath + "image" + File.separator;
//判断html文件是否存在
File htmlFile = new File(htmlPath + htmlName);
if(htmlFile.exists()){
return htmlFile.getAbsolutePath();
}
//word文件
File wordFile = new File(wordPath + File.separator + wordName + suffix);
// 1) 加载word文档生成 XWPFDocument对象
InputStream in = new FileInputStream(wordFile);
XWPFDocument document = new XWPFDocument(in);
// 2) 解析 XHTML配置 (这里设置IURIResolver来设置图片存放的目录)
File imgFolder = new File(imagePath);
XHTMLOptions options = XHTMLOptions.create();
options.setExtractor(new FileImageExtractor(imgFolder));
//html中图片的路径 相对路径
options.URIResolver(new BasicURIResolver("image"));
options.setIgnoreStylesIfUnused(false);
options.setFragment(true);
// 3) 将 XWPFDocument转换成XHTML
//生成html文件上级文件夹
File folder = new File(htmlPath);
if(!folder.exists()){
folder.mkdirs();
}
OutputStream out = new FileOutputStream(htmlFile);
XHTMLConverter.getInstance().convert(document, out, options);
return htmlFile.getAbsolutePath();
}
}파일 디렉터리:
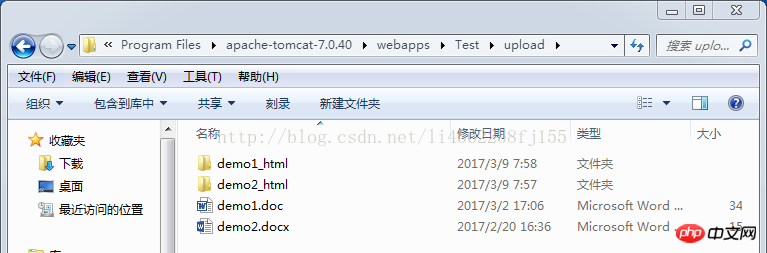

위 내용은 Java를 사용하여 Word 파일을 html 파일로 변환하는 샘플 코드에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.