
JVM 심층학습 - 자바 파싱 클래스 파일 프로세스 샘플 코드

- 黄舟원래의
- 2017-03-18 10:47:351894검색
서문:
Java프로그래머로서 JVM을 어떻게 이해할 수 없겠습니까? JVM을 배우고 싶다면 Class 파일을 이해해야 합니다. 물고기가 물에 있는 것처럼 가상 머신은 클래스 때문에 살아있습니다. "Java Virtual Machine에 대한 심층적 이해"는 클래스 파일을 설명하는 장 전체를 소비하지만, 읽고 난 후에도 여전히 혼란스럽고 절반 정도 이해되었습니다. 얼마 전에 아주 좋은 책을 읽었습니다: "자신만의 Java 가상 머신 작성" 저자는 go 언어를 사용하여 JVM의 모든 기능을 완전히 구현하지는 않았지만 유용합니다. JVM에 약간 관심이 있는 사람들. 그렇긴 하지만 가독성은 여전히 매우 높습니다. 저자는 이에 대해 자세히 설명하고, 각 프로세스는 하나의 장으로 나누어지며, 그 중 일부는 클래스 파일을 구문 분석하는 방법을 설명합니다.
이 책은 두껍지 않아서 빨리 읽었어요. 하지만 종이로 배우는 것은 시간 문제일 뿐이었고, 직접 해봐야 한다는 걸 알기에 Class 파일을 직접 파싱해 보았습니다. Go 언어는 훌륭하지만 결국 능숙하지 않습니다. 특히 변수 뒤에 유형을 넣는 구문에 익숙하지 않은 경우에는 Java를 고수하는 것이 좋습니다.
클래스 파일
클래스 파일이란?
Java가 크로스 플랫폼을 구현할 수 있는 이유는 컴파일 단계에서 코드를 플랫폼 관련 기계어로 직접 컴파일하는 것이 아니라 먼저 바이너리 형태의 Java 바이트코드로 컴파일하여 클래스 파일에 넣기 때문입니다. , 가상 머신은 클래스 파일을 로드하고 프로그램을 실행하는 데 필요한 콘텐츠를 구문 분석합니다. 각 클래스는 별도의 클래스 파일로 컴파일되며 내부 클래스도 자체 클래스를 생성하기 위해 독립 클래스로 사용됩니다.
기본 구조
다음과 같이 클래스 파일을 찾아 Sublime Text로 엽니다.
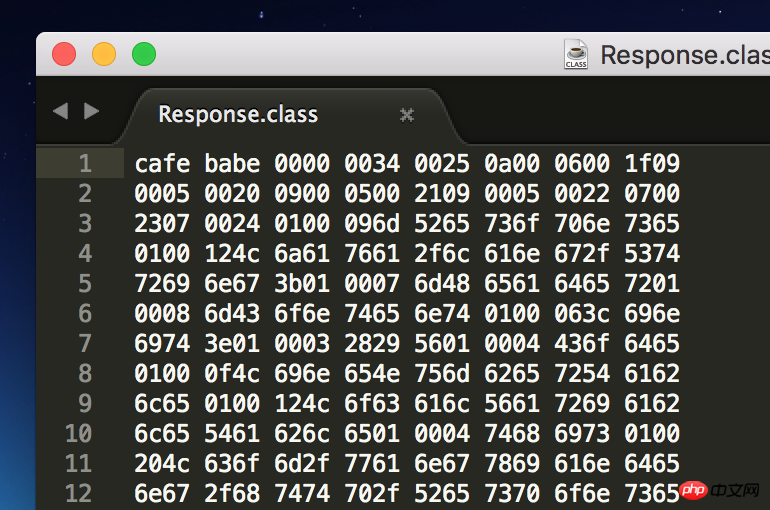
하지만 헷갈리시나요? 클래스 파일의 기본 형식은 Java Virtual Machine 사양에 나와 있습니다.
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}ClassFile의 필드 유형은 u1, u2, u4입니다. ? 사실 매우 간단합니다. 각각 1바이트, 2바이트, 4바이트를 의미합니다.
의 처음 4바이트는 Magic으로, 파일 형식을 고유하게 식별하는 데 사용됩니다. 일반적으로 가상 머신이 로드된 파일을 인식할 수 있도록 매직 넘버라고 합니다. 클래스 형식이고 클래스 파일의 마법 개수는 Cafebabe입니다. 클래스 파일뿐만 아니라 기본적으로 대부분의 파일에는 형식을 식별하는 매직 넘버가 있습니다.
다음 부분은 주로 상수 풀, 클래스 액세스 플래그, 상위 클래스, 인터페이스 정보, 필드, 메소드 등과 같은 클래스 파일에 대한 일부 정보입니다. 자세한 내용은 "Java Virtual Machine"을 참조하세요. 사양".
분석
필드 유형
위에서 언급했듯이 ClassFile의 필드 유형은 u1, u2, u4로 각각 1바이트, 2바이트, 4를 나타냅니다. 바이트의 정수입니다. Java에서 short, int 및 long은 각각 2, 4, 8바이트의 부호 있는 정수입니다. 부호 비트가 없으면 u1, u2 및 u4를 나타내는 데 사용할 수 있습니다.
public class U1 {
public static short read(InputStream inputStream) {
byte[] bytes = new byte[1];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
short value = (short) (bytes[0] & 0xFF);
return value;
}
}
public class U2 {
public static int read(InputStream inputStream) {
byte[] bytes = new byte[2];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
int num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}
public class U4 {
public static long read(InputStream inputStream) {
byte[] bytes = new byte[4];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
long num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}상수 풀
필드 유형을 정의한 후 클래스 파일을 읽을 수 있습니다. 첫 번째 단계는 매직 넘버와 같은 기본 정보를 읽는 것입니다.
FileInputStream inputStream = new FileInputStream(file); ClassFile classFile = new ClassFile(); classFile.magic = U4.read(inputStream); classFile.minorVersion = U2.read(inputStream); classFile.majorVersion = U2.read(inputStream);
이번 부분은 단지 워밍업이고 다음으로 중요한 부분은 상수 풀입니다. 상수 풀을 분석하기 전에 먼저 상수 풀이 무엇인지부터 설명하겠습니다.
상수 풀은 이름에서 알 수 있듯이 상수를 저장하는 리소스 풀입니다. 여기서 상수는 리터럴 및 기호 참조를 나타냅니다. 리터럴은 일부 문자열 리소스를 참조하며 기호 참조는 클래스 기호 참조, 메서드 기호 참조, 필드 기호 참조의 세 가지 범주로 나뉩니다. 상수 풀에 리소스를 배치하면 다른 항목을 상수 풀에 직접 인덱스로 정의할 수 있어 공간 낭비를 피할 수 있습니다. 이는 클래스 파일뿐만 아니라 Android 실행 파일인 dex에도 적용됩니다. 리소스 등은 DexData에 배치되고, 기타 항목은 인덱스를 통해 리소스를 찾습니다. Java Virtual Machine 사양에서는 상수 풀의 각 항목 형식을 제공합니다.
cp_info {
u1 tag;
u1 info[];
}위 형식은 일반적인 형식일 뿐 실제로 상수 풀에 포함되는 데이터 형식은 14개이며, 태그 값은 다음과 같습니다. 형식마다 다르며 자세한 내용은 다음과 같습니다.
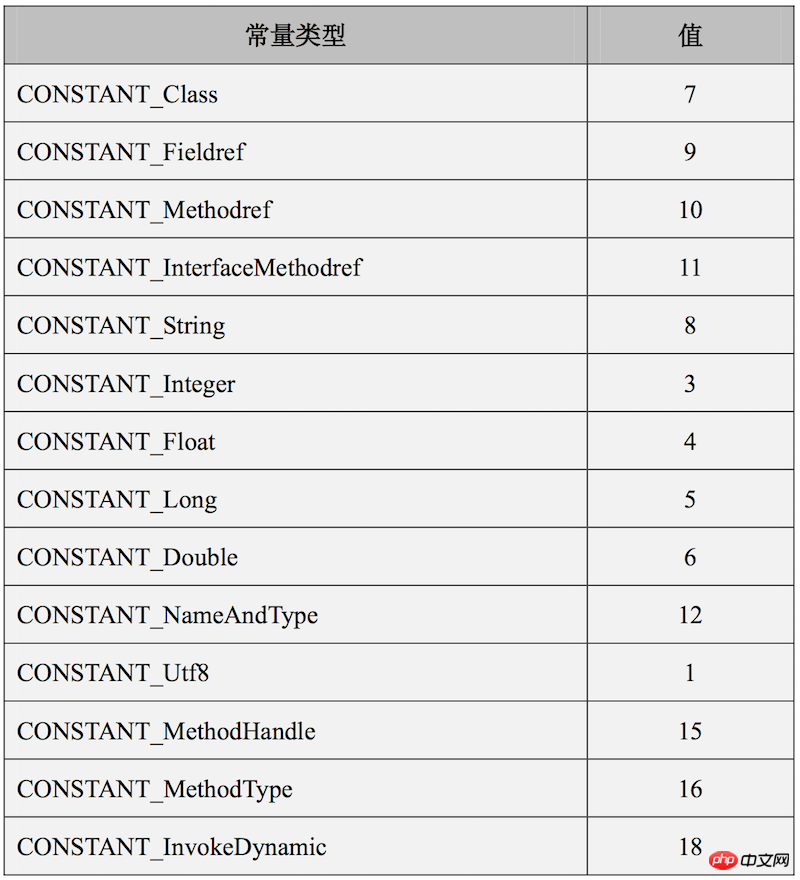
형식이 너무 많기 때문에 기사의 일부만 선택하여 설명합니다.
여기 먼저 상수 풀의 크기를 읽고 초기화합니다. 상수 풀:
//解析常量池 int constant_pool_count = U2.read(inputStream); ConstantPool constantPool = new ConstantPool(constant_pool_count); constantPool.read(inputStream);
다음으로 각 항목을 하나씩 읽어서 배열 cpInfo에 저장합니다. cpInfo[] 첨자는 1부터 시작하고 0은 유효하지 않으며 실제 상수 풀 크기는 Constant_pool_count-1입니다.
public class ConstantPool {
public int constant_pool_count;
public ConstantInfo[] cpInfo;
public ConstantPool(int count) {
constant_pool_count = count;
cpInfo = new ConstantInfo[constant_pool_count];
}
public void read(InputStream inputStream) {
for (int i = 1; i < constant_pool_count; i++) {
short tag = U1.read(inputStream);
ConstantInfo constantInfo = ConstantInfo.getConstantInfo(tag);
constantInfo.read(inputStream);
cpInfo[i] = constantInfo;
if (tag == ConstantInfo.CONSTANT_Double || tag == ConstantInfo.CONSTANT_Long) {
i++;
}
}
}
}먼저 CONSTANT_Utf8 형식을 살펴보겠습니다. 이 항목은 MUTF-8로 인코딩된 문자열을 저장합니다.
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}이 항목을 어떻게 읽어야 할까요?
public class ConstantUtf8 extends ConstantInfo {
public String value;
@Override
public void read(InputStream inputStream) {
int length = U2.read(inputStream);
byte[] bytes = new byte[length];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
value = readUtf8(bytes);
} catch (UTFDataFormatException e) {
e.printStackTrace();
}
}
private String readUtf8(byte[] bytearr) throws UTFDataFormatException {
//copy from java.io.DataInputStream.readUTF()
}
}很简单,首先读取这一项的字节数组长度,接着调用readUtf8(),将字节数组转化为String字符串。
再来看看CONSTANT_Class这一项,这一项存储的是类或者接口的符号引用:
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}注意这里的name_index并不是直接的字符串,而是指向常量池中cpInfo数组的name_index项,且cpInfo[name_index]一定是CONSTANT_Utf8格式。
public class ConstantClass extends ConstantInfo {
public int nameIndex;
@Override
public void read(InputStream inputStream) {
nameIndex = U2.read(inputStream);
}
}常量池解析完毕后,就可以供后面的数据使用了,比方说ClassFile中的this_class指向的就是常量池中格式为CONSTANT_Class的某一项,那么我们就可以读取出类名:
int classIndex = U2.read(inputStream);
ConstantClass clazz = (ConstantClass) constantPool.cpInfo[classIndex];
ConstantUtf8 className = (ConstantUtf8) constantPool.cpInfo[clazz.nameIndex];
classFile.className = className.value;
System.out.print("classname:" + classFile.className + "\n");字节码指令
解析常量池之后还需要接着解析一些类信息,如父类、接口类、字段等,但是相信大家最好奇的还是java指令的存储,大家都知道,我们平时写的java代码会被编译成java字节码,那么这些字节码到底存储在哪呢?别急,讲解指令之前,我们先来了解下ClassFile中的method_info,其格式如下:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}method_info里主要是一些方法信息:如访问标志、方法名索引、方法描述符索引及属性数组。这里要强调的是属性数组,因为字节码指令就存储在这个属性数组里。属性有很多种,比如说异常表就是一个属性,而存储字节码指令的属性为CODE属性,看这名字也知道是用来存储代码的了。属性的通用格式为:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}根据attribute_name_index可以从常量池中拿到属性名,再根据属性名就可以判断属性种类了。
Code属性的具体格式为:
Code_attribute {
u2 attribute_name_index; u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}其中code数组里存储就是字节码指令,那么如何解析呢?每条指令在code[]中都是一个字节,我们平时javap命令反编译看到的指令其实是助记符,只是方便阅读字节码使用的,jvm有一张字节码与助记符的对照表,根据对照表,就可以将指令翻译为可读的助记符了。这里我也是在网上随便找了一个对照表,保存到本地txt文件中,并在使用时解析成HashMap。代码很简单,就不贴了,可以参考我代码中InstructionTable.java。
接下来我们就可以解析字节码了:
for (int j = 0; j < methodInfo.attributesCount; j++) {
if (methodInfo.attributes[j] instanceof CodeAttribute) {
CodeAttribute codeAttribute = (CodeAttribute) methodInfo.attributes[j];
for (int m = 0; m < codeAttribute.codeLength; m++) {
short code = codeAttribute.code[m];
System.out.print(InstructionTable.getInstruction(code) + "\n");
}
}
}运行
整个项目终于写完了,接下来就来看看效果如何,随便找一个class文件解析运行:
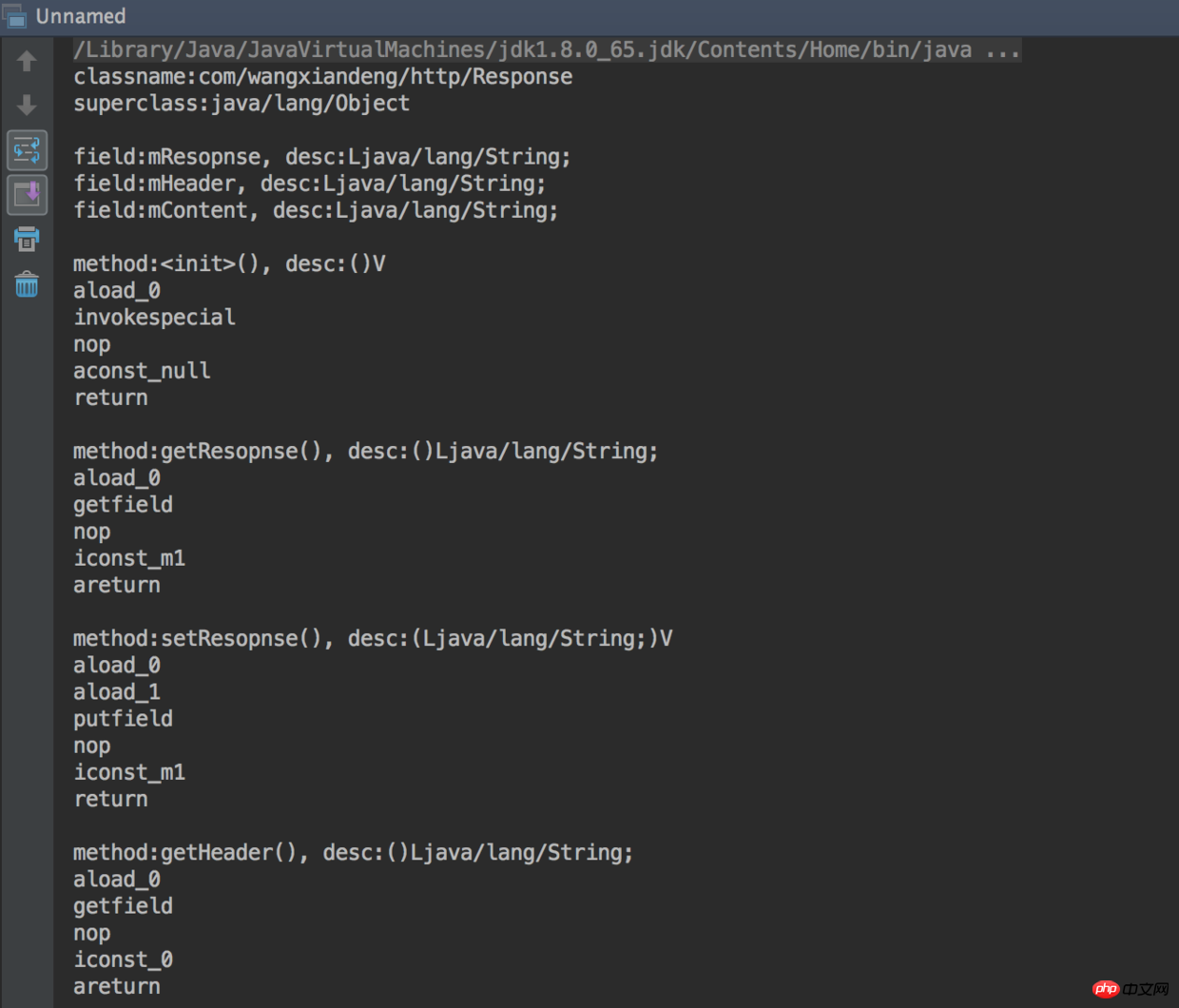
哈哈,是不是很赞!
위 내용은 JVM 심층학습 - 자바 파싱 클래스 파일 프로세스 샘플 코드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!