
집 >데이터 베이스 >MySQL 튜토리얼 >mysql 기본 지식 활용 능력에 대한 자세한 소개(그림)
mysql 기본 지식 활용 능력에 대한 자세한 소개(그림)

- 黄舟원래의
- 2017-03-17 14:18:101244검색
이 글은 주로 mysql에 대한 아주 기본적인 지식을 소개합니다. 매우 좋은 참조 값을 가지고 있습니다. 아래 에디터로 살펴보겠습니다
이번 글에서는 이후의 SQL 최적화에 대비하기 위해 mysql에 대한 아주 기본적인 지식을 주로 소개합니다.
1: mysql에 연결
mysql 설치여기에서는 자세한 내용을 다루지 않겠습니다. mysql 서버를 연결하고 cmd 명령을 열고 MySQL 서버를 설치한 bin 디렉토리로 전환한 다음 mysql -h localhost -u root -p
를 입력합니다. 여기서 -h는 호스트 주소를 나타냅니다(이 머신은 localhost입니다). , 포트 번호를 포함하지 마십시오.) -u는 데이터베이스 연결을 의미합니다. name -p는 연결 비밀번호를 의미합니다. 다음과 같은 그림이 나오면 연결이 성공했다는 뜻입니다.

2: 자주 사용하는 sql문
2.1: 데이터베이스 생성 데이터베이스 생성 데이터베이스 이름
2.2: 데이터베이스 삭제 데이터베이스 데이터베이스 이름
2.3: 시스템에서 데이터베이스 쿼리 show Databases
2.4: 데이터베이스 사용 데이터베이스 이름
2.5: 데이터베이스 테이블 쿼리 show tables
2.6: 테이블 구조 쿼리 desc + 테이블 이름
2.7: sql 문을 쿼리하여 테이블 생성 show create table + 테이블 이름
2.8: 테이블 삭제 + 테이블 이름
2.9: 여러 테이블 레코드를 한 번에 삭제: t1, t2에서 t1, t2 삭제 [where 조건] from 뒤에 별칭을 사용하는 경우 삭제 후 별칭을 사용해야 함
3.0 : 여러 테이블을 한 번에 업데이트 update t1, t2 ...tn set t1.field=expr1,tn.exprn=exprn;
3: 쿼리
3.1 : 일반 쿼리 선택
여기서 데이터를 생성하고 테이블 2개를 넣었는데 아래 그림을 보세요
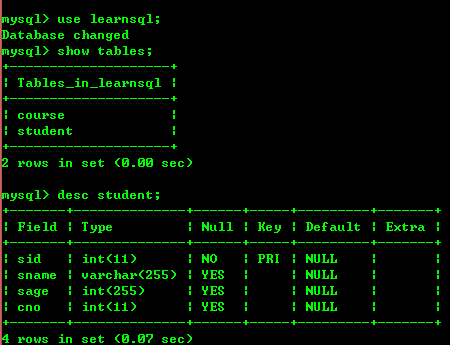
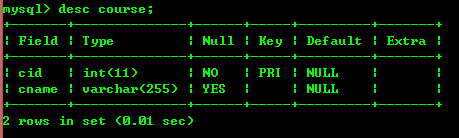
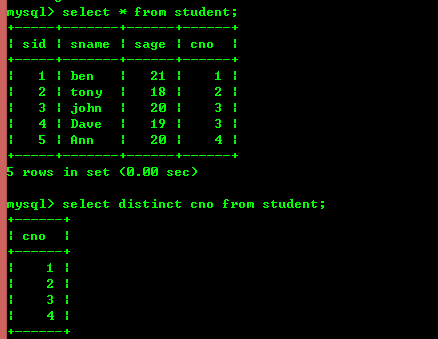
3.2: 고유 레코드 쿼리
아래 표시된 키워드 independent를 사용
3.3: 정렬 및 제한
키워드 order by Sort desc 내림차순 asc 오름차순, 제한 키워드를 사용하여 출력 제한
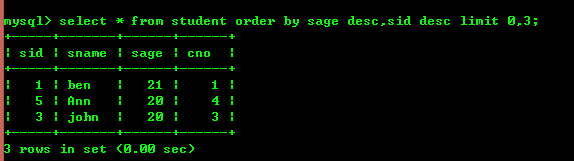
order by 뒤에 필드(order by만 있으면 됨) 첫 번째 필드를 먼저 정렬한 다음 두 번째 필드를 정렬하기 위해 한 번 작성되었습니다. 비유하자면, 제한 다음의 첫 번째 숫자는 숫자이고 두 번째 숫자는 출력 수입니다.
넷째: 집계작업
많은 경우 사용자는 회사 전체의 인원 수나 부서 수를 세는 등의 통계를 작성해야 합니다. 이때 집계 작업에 사용됩니다. 집계 연산 구문이 적용됩니다
테이블 이름에서 [field1, field2...fieldn] fun_name 선택
여기서 조건
field1, field2...fieldn으로 그룹화
롤업 포함
조건 있음
fun_name은 집계 함수 또는 집계 연산이라고 합니다. 일반적인 것에는 sum(sum), count(*) 레코드 수, max( 최대값), min(최소값).
그룹별은 분류하여 집계할 필드를 나타냅니다. 예를 들어 부서 분류에 따라 직원 수를 그룹별로 작성해야 합니다.
롤업은 선택 사항입니다. 카테고리를 집계할지 여부를 나타내는 구문입니다.
분류된 결과가 다시 필터링됨을 의미합니다
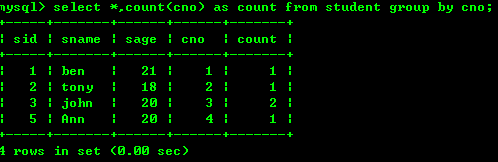
4.1: 강좌 번호에 따라 학급의 인원 수를 계산합니다.
4.2 : 학년별로 인원수를 세고 총인원을 세어보세요
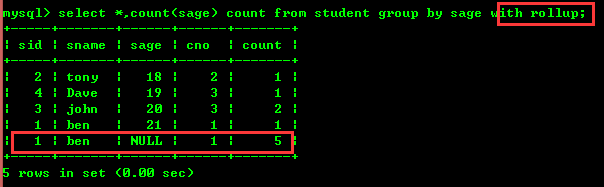
롤업은 요약해서 사진에서 볼 수 있듯이 사람의 수는 어마어마합니다.
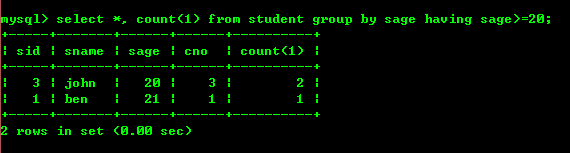
4.3: 20세 이상 인구 계산 집계 시 레코드가 필터링되는 경우 논리가 허용하는 경우 레코드를 먼저 필터링할 위치를 사용하면 결과 집합이 줄어들고 효율성이 크게 향상됩니다. 집계한 다음 보유 기준으로 필터링합니다.
 5: 테이블 연결
5: 테이블 연결
내부 조인과 외부 조인의 주요 차이점은 내부 조인은 두 테이블에서 일치하는 레코드만 필터링하는 반면 외부 조인은 일치하지 않는 다른 레코드를 필터링한다는 것입니다. 자주 사용하는 것은 내부 연결입니다.
5.1: 학생이 선택한 강좌 조회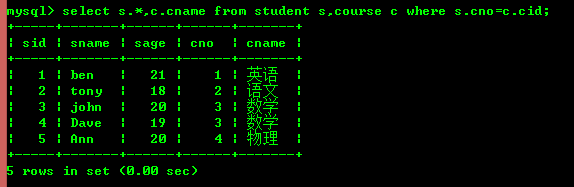
외부 조인은 왼쪽 조인과 오른쪽 조인으로 구분됩니다.
왼쪽 조인(오른쪽 테이블에 일치하는 레코드가 없더라도 왼쪽 테이블의 모든 레코드 포함)
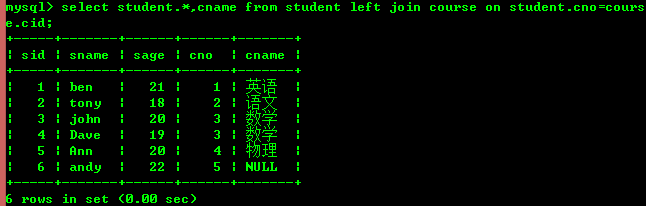
오른쪽 조인(포함) all 오른쪽 테이블의 레코드는 왼쪽 테이블의 일치하는 레코드도 없습니다.)
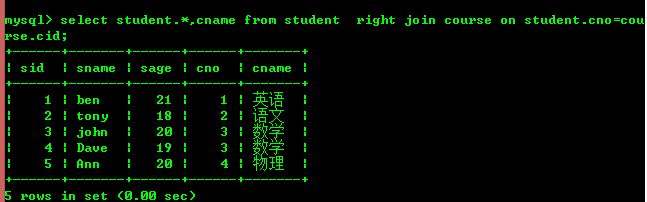
왼쪽 테이블을 기준으로 왼쪽 조인이 이루어진 것을 알 수 있으며, 오른쪽 조인은 오른쪽 테이블을 기반으로 합니다. 테이블이 기본 테이블입니다.
Six: Subquery
어떤 경우에는 쿼리를 할 때 필요한 조건이 다른 select 문의 결과인 경우가 있는데, 이 경우에는 Query를 사용합니다. 하위 쿼리에 사용되는 키워드에는 주로 in, not in, =, !=, 존재, 존재하지 않음 등이 포함됩니다.
예를 들어 in을 사용하여 쿼리
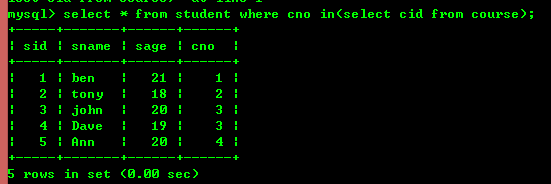
그러나 내부 조인을 사용하면 위의 효과를 얻을 수도 있습니다
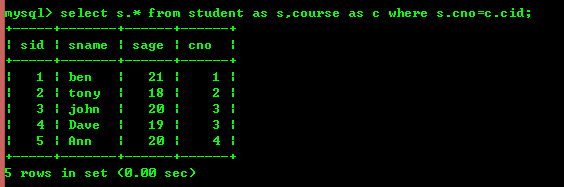
그러나 내부 조인의 효율성은 많은 경우 하위 쿼리보다 높으므로 비즈니스 로직 전제하에 인라인이 우선시됩니다.
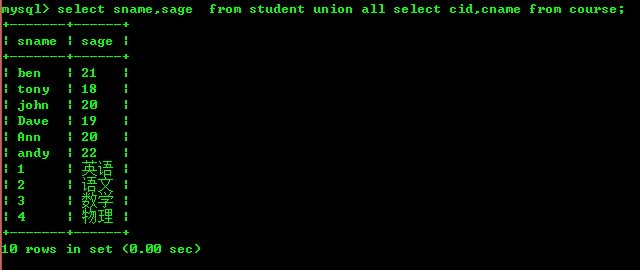
세븐: 유니온
두 테이블의 데이터를 일정한 규칙에 따라 쿼리하고 그 결과를 병합하여 함께 표시합니다. 이때 Union 또는 Union All을 사용할 수 있습니다. 구체적인 구문은 다음과 같습니다
select * from t1 Unionunion all select * from t2 Unionunion all select * from tn;
Union과 Union All의 차이점은 Union이 중복 레코드를 제거한다는 점입니다. 필터링된 결과 집합.
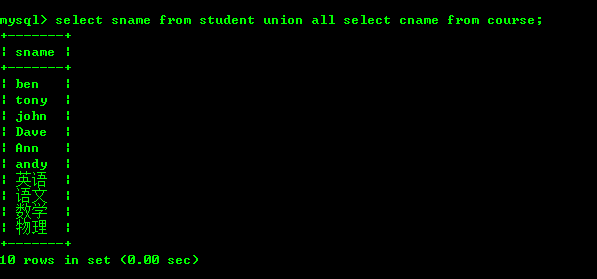
다음과 같이 일치하지 않는 두 테이블을 조인할 수 없다는 점을 기억하세요.

각 테이블을 쿼리하면 2개 필드
8: 공통 기능
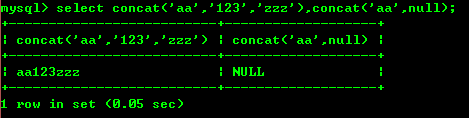
8.1: concat
cancat 기능: 전달 매개변수는 다음과 같습니다. 문자열으로 연결됩니다. 아래와 같이 null을 연결한 결과는 null입니다.
8.2: 삽입 (str,x,y,instr) 함수는 바꾸기
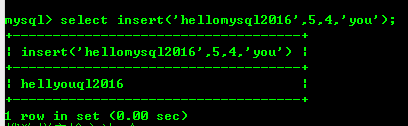
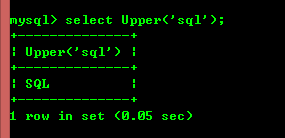
8.3: Lower(Str) 및 Upper(Str) 문자열을 소문자로 변환에서 시작하는 문자열 str을 바꿉니다. 또는 대문자.
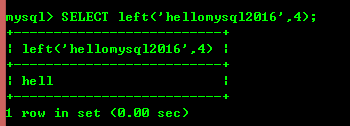
8.4: left(str,x) 및 right(str,x)는 두 매개변수가 다음과 같은 경우 각각 문자열의 가장 왼쪽 x 문자와 가장 오른쪽 x 문자를 반환합니다. null이고 문자가 반환되지 않습니다.
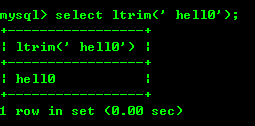
8.5: ltrim(str) 및 rtrim(str)은 문자열의 왼쪽 또는 오른쪽에 있는 문자를 제거합니다
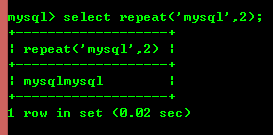
8.6: Repeat(str,x): x번 반복된 str의 결과를 반환합니다.
8.7: replacement(str, a, b ) 문자열 str에서 문자열 a의 모든 항목을 문자열 b로 바꿉니다.
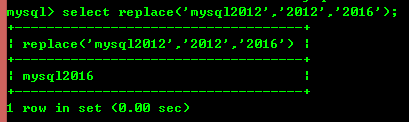
8.8: Trim(str) 앞뒤 공백 제거
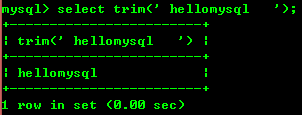
8.9: substring(str,x, y ): 문자열 str의 x번째 위치부터 시작하여 y 문자열 길이의 문자열을 반환합니다.
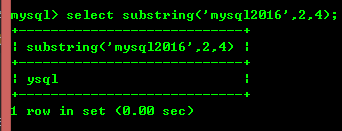
위 내용은 mysql 기본 지식 활용 능력에 대한 자세한 소개(그림)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!